
Jupyter AI は、JupyterLab の拡張機能で、色々なAI機能が提供されています。
その中で、データサイエンティストとして嬉しいのが、コード生成機能です。
会話しながら、Pythonコーディングを実施できます。
今現在(2023年6月29日現在)、Jupyter AI はまだ開発中ですが、使いやすく有望なツールになることでしょう。
以前、Jupyter AI のインストールと簡単な使い方について説明しました。
既にJupyter AI(jupyter_ai)がインストールされ使える状態という前提で、今回はお話しを進めます。まだJupyter AI(jupyter_ai)がインストールなどの設定をされていない方は、前回の記事を参考にしてください。
伝統的な機械学習系には、回帰問題と分類問題というものがあります。
前回、Jupyter AI を使った会話ベースによる回帰問題の予測モデルの構築例を示しました。
ということで今回は、「分類問題の予測モデルをJupyter AIで作ろう!」というお話しをします。
分類問題とは、どのカテゴリに属するかを予測する問題です。構築する予測モデルの目的変数が質的変数となります。
Contents [hide]
今回利用するJupyter AIの構文
今回利用する構文は以下です。【プロンプト】と記載されているところに、ChatGPTに与える質問や指示などを記載します。
%%ai chatgpt -f code 【プロンプト】
プロンプトに記載されている質問や指示などに応じて、Pythonコードがセルごと生成されます。
そのPythonコードの記載されたセルを実行することで、データ分析を進めることができます。
データセットの説明
今回はscikit-learnから提供されているサンプルデータセットの、乳がんの診断結果を分類する問題を例に解いてみます。
【今回使用】
scikit-learnから提供されているサンプルデータセット
https://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_breast_cancer.html#sklearn.datasets.load_breast_cancer
今回使う乳がんの診断結果のデータセットは、カリフォルニア大学アーバイン校から提供されている機械学習用データセットのひとつです。
目的変数Yは、画像の分類結果良性(=1)と悪性(=0)の2クラス値です。
特徴量(説明変数X)は、細胞核の画像を処理し表にある10個の特徴量をから平均値、標準偏差、最低値を算出し、最終的に30個の特徴量にしています。
| 項目名 | 詳細 |
| radius | 細胞核の中心から外周までの距離 |
| texture | 画像のグレースケールの標準偏差 |
| perimeter | 細胞核周囲の長さ |
| area | 細胞核の面積 |
| smoothness | 細胞核の直径の局所分散値 |
| compactness | perimeter^2/area – 1.0で計算される値 |
| concavity | 輪郭の凹面度の重大度 |
| concave point | 輪郭の凹面部の数 |
| symmetry | 対称性 |
| fractal dimension | フラクタル次元 |
準備
では、準備をします。
以下のコードをJupyter Labに記述し実行するだけです。
import os os.environ["OPENAI_API_KEY"]="あなたのOpenAI API Key" %load_ext jupyter_ai
分類問題
データ読み込みと探索的データ分析
データ読み込みと、最初の探索的データ分析
先ず、以下のようなコード(プロンプト付きコード)を記載しました。
%%ai chatgpt -f code scikit-learnから提供されているサンプルデータセットの乳がんの診断結果(breast_cancer)を使います。 データ理解のために、データの可視化と探索的データ分析をして下さい。
次のような回答(Pythonコード)を得ました。
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_breast_cancer
# Load breast cancer dataset
data = load_breast_cancer()
df = pd.DataFrame(data['data'], columns=data['feature_names'])
df['target'] = data['target']
# Visualize correlation matrix
corr_matrix = df.corr()
sns.heatmap(corr_matrix, annot=True, cmap='coolwarm')
plt.title('Correlation Matrix')
plt.show()
# Visualize distribution of target classes
sns.countplot(x='target', data=df)
plt.title('Target Class Distribution')
plt.show()
# Visualize a few features against target class
sns.boxplot(x='target', y='mean radius', data=df)
plt.title('Mean Radius vs Target Class')
plt.show()
sns.boxplot(x='target', y='mean texture', data=df)
plt.title('Mean Texture vs Target Class')
plt.show()
sns.boxplot(x='target', y='mean area', data=df)
plt.title('Mean Area vs Target Class')
plt.show()
このPythonコードをそのまま実行します。
以下、実行結果です。
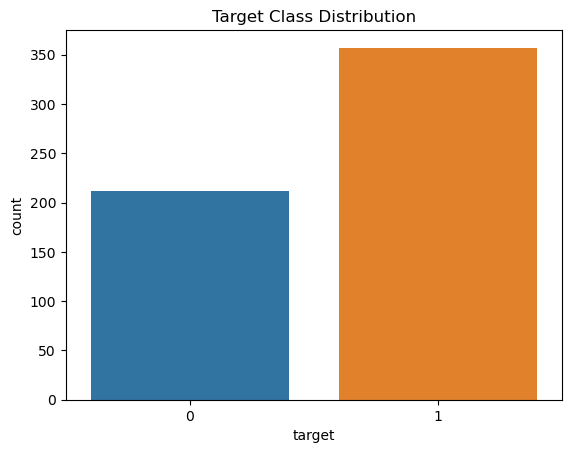
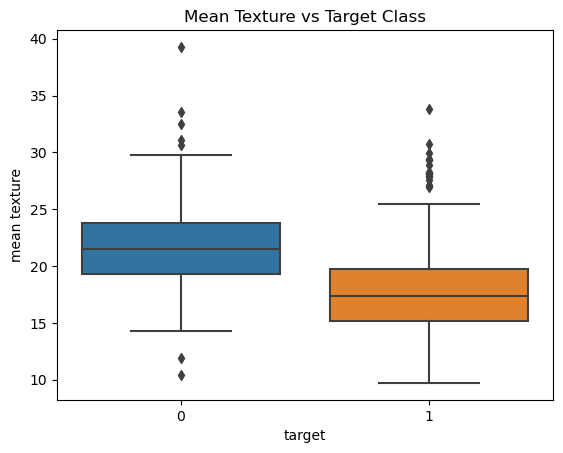
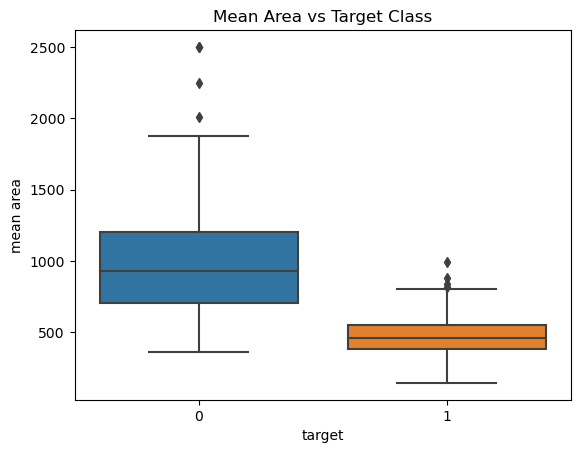
さらなる探索的データ分析
探索的データ分析としては不十分な気がしますので、以下のようなコード(プロンプト付きコード)を記載しました。
%%ai chatgpt -f code 続けてください。
次のような回答(Pythonコード)を得ました。
# Visualize pairwise scatter plots of features sns.pairplot(df[data['feature_names']]) plt.show()
このPythonコードをそのまま実行します。
以下、実行結果です。

特徴量重要度も知りたい
特徴量重要度も知りたいので、名指しで指示を出してみます。
以下のようなコード(プロンプト付きコード)を記載しました。
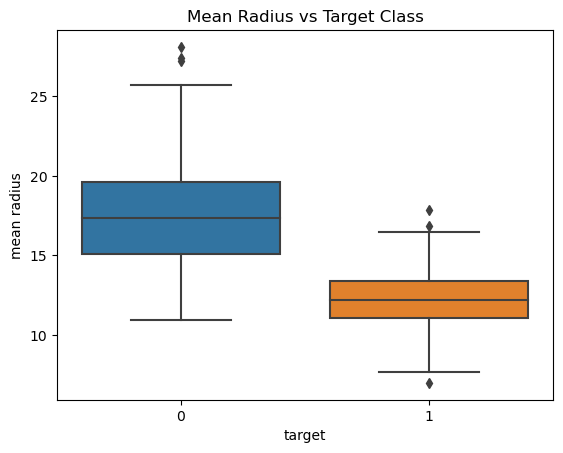
%%ai chatgpt -f code 乳がんにとって重要な特徴量を見つけるため 特徴量重要度のランキングを作って下さい。
次のような回答(Pythonコード)を得ました。
from sklearn.ensemble import RandomForestClassifier
# データセットの読み込み
data = load_breast_cancer()
X = data.data
y = data.target
# ランダムフォレスト分類器の作成
rf = RandomForestClassifier(n_estimators=100, random_state=0)
rf.fit(X, y)
# 特徴量の重要度のランキングを作成
importance = rf.feature_importances_
indices = importance.argsort()[::-1]
# 特徴量の重要度のランキングを可視化
importance_df = pd.DataFrame(data=importance[indices], index=data.feature_names[indices], columns=["Importance"])
sns.barplot(x="Importance", y=importance_df.index, data=importance_df)
plt.xlabel("Feature Importance")
plt.ylabel("Features")
plt.title("Feature Importance Ranking")
plt.show()
このPythonコードをそのまま実行します。
以下、実行結果です。
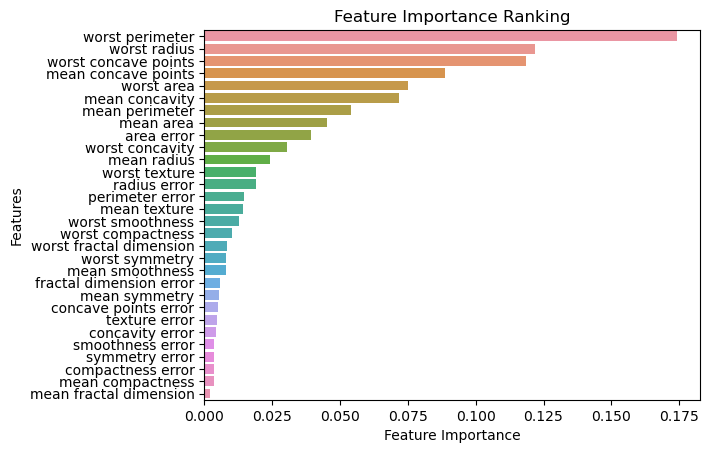
探索的データ分析はこのあたりで終えます。
漠然と「探索的データ分析をして」と頼むでのではなく、具体的に明示した方が良さそうです。
それはさておき、次は予測モデルの構築です。
予測モデルの構築
とりあえず作ってみて
先ず、以下のようなコード(プロンプト付きコード)を記載しました。
%%ai chatgpt -f code 乳がんかどうかを予測する分類モデルを構築して下さい。 テストデータの正答率を出力してください。
次のような回答(Pythonコード)を得ました。
from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score # Split the data into training and testing sets X_train, X_test, y_train, y_test = train_test_split(data['data'], data['target'], test_size=0.2, random_state=42) # Create and train the random forest classifier model = RandomForestClassifier(random_state=42) model.fit(X_train, y_train) # Predict on the test set y_pred = model.predict(X_test) # Calculate the accuracy score accuracy = accuracy_score(y_test, y_pred) accuracy
このPythonコードをそのまま実行します。
以下、実行結果です。出力されているのはテストデータの正答率です。0以上1以下の値を取り、大きいほど高精度とみなされます。
0.9649122807017544
まずまずの結果ですね。
さらなる高みを目指し、予測モデルの改良をします。
取り急ぎ改良して!
以下のようなコード(プロンプト付きコード)を記載しました。
%%ai chatgpt -f code 工夫して予測モデルの精度を上げてください。
次のような回答(Pythonコード)を得ました。
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(data['data'], data['target'], test_size=0.2, random_state=42)
# Create the random forest classifier
model = RandomForestClassifier(random_state=42)
# Define the parameter grid for hyperparameter tuning
param_grid = {
'n_estimators': [10, 50, 100, 200],
'max_depth': [None, 5, 10, 20],
'min_samples_split': [2, 5, 10],
'min_samples_leaf': [1, 2, 4],
'max_features': ['sqrt', 'log2', None]
}
# Perform grid search to find the best hyperparameters
grid_search = GridSearchCV(estimator=model, param_grid=param_grid, cv=5)
grid_search.fit(X_train, y_train)
# Get the best model with optimized hyperparameters
best_model = grid_search.best_estimator_
# Predict on the test set using the best model
y_pred = best_model.predict(X_test)
# Calculate the accuracy score
accuracy = accuracy_score(y_test, y_pred)
accuracy
このPythonコードをそのまま実行します。
以下、実行結果です。出力されているのはテストデータの正答率です。
0.9736842105263158
正答率が良くなっています。
予測精度的には十分ですが、さらなる予測モデルの改良に挑みます。
AutoML(自動機械学習)で改良して!
ただ、手作業で右往左往してもつまらないので、AutoML(自動機械学習)で予測モデルの改良に挑みます。今回は、TPOTというPythonのAutoML(自動機械学習)ライブラリーを使います。
以下のようなコード(プロンプト付きコード)を記載しました。
%%ai chatgpt -f code TPOTを使い予測モデルの精度を上げてください。
次のような回答(Pythonコード)を得ました。
from sklearn.model_selection import train_test_split from tpot import TPOTClassifier from sklearn.metrics import accuracy_score # Split the data into training and testing sets X_train, X_test, y_train, y_test = train_test_split(data['data'], data['target'], test_size=0.2, random_state=42) # Create and train the TPOT classifier model = TPOTClassifier(generations=5, population_size=50, verbosity=2, random_state=42) model.fit(X_train, y_train) # Predict on the test set y_pred = model.predict(X_test) # Calculate the accuracy score accuracy = accuracy_score(y_test, y_pred) accuracy
このPythonコードをそのまま実行します。
以下、実行結果です。
Best pipeline: SGDClassifier(StandardScaler(input_matrix), alpha=0.0, eta0=0.1, fit_intercept=False, l1_ratio=0.0, learning_rate=constant, loss=hinge, penalty=elasticnet, power_t=50.0) 0.9824561403508771
さらなる改善に成功したようです。
ただ、どのような予測モデルつまりパイプライン(変換器と予測器の組み合わせ)を構築したのか、知りたいところです。
サイドパネルにあるチャットインターフェイス(プロンプトを入力する部分)で、Best pipelineがどのようなものなのかを聞いてみましょう。
チャットインターフェイス(プロンプトを入力する部分)に以下をインプットし、ChatGPTに聞いてみました。
以下のような回答を得ました。
このパイプラインは、SGDClassifierアルゴリズムを使用してデータを分類するための最適な手順を示しています。以下にパイプラインの各ステップを説明します。
StandardScaler(input_matrix):StandardScalerは、データのスケーリングを行うための前処理ステップです。input_matrixは入力データ行列です。StandardScalerは、各特徴量をその特徴量の平均値を引いてから標準偏差で割ることで、特徴量のスケールを調整します。- これにより、異なるスケールを持つ特徴量が存在する場合でも、モデルのトレーニングをより安定させることができます。
alpha=0.0, eta0=0.1, fit_intercept=False, l1_ratio=0.0, learning_rate=constant, loss=hinge, penalty=elasticnet, power_t=50.0:SGDClassifierのインスタンス化とパラメータの設定を行います。alpha=0.0は正則化の強さを制御するパラメータで、0.0に設定されているため、正則化は行われません。eta0=0.1は初期学習率を設定するパラメータで、0.1に設定されています。fit_intercept=Falseは、モデルに切片(インターセプト)を含めないことを意味します。l1_ratio=0.0は、Elastic Net正則化のL1とL2の比率を制御するパラメータで、0.0に設定されているため、L2正則化のみが使用されます。learning_rate='constant'は、学習率のスケジュールを設定するパラメータで、’constant’に設定されているため、学習率はトレーニング中に一定です。loss='hinge'は、使用する損失関数を指定するパラメータで、’hinge’に設定されています。これは線形SVMで一般的に使用される損失関数です。penalty='elasticnet'は、正則化のタイプを指定するパラメータで、’elasticnet’に設定されています。これはL1正則化とL2正則化を組み合わせた正則化です。power_t=50.0は学習率スケジュールに影響を与えるパラメータで、50.0に設定されています。
- このパイプラインでは、データは
StandardScalerを使用してスケーリングされた後、SGDClassifierにフィードされます。- データはスケーリングされ、特徴量のスケールが調整され、異なるスケールを持つ特徴量の影響を均一化します。
SGDClassifierは、指定されたパラメータに基づいてトレーニングされ、最適な分類モデルを作成します。
このパイプラインは、データのスケーリングとSGDClassifierを使用することで、高性能な分類モデルを構築するための手順を提供しています。ただし、これはあくまで一例であり、データセットや問題によって最適なパラメータや前処理手法が異なる場合があります。
まとめ
今回は、「分類問題の予測モデルをJupyter AIで作ろう!」というお話しをしました。
プロンプト(テキストによる質問や指示など)だけで、Pythonコーディングしながら、分類問題の予測モデルを構築できました。
ただ、最低限のデータサイエンスの知識がないと、プロンプト(テキストによる質問や指示など)すらかけないので、そこのお勉強はなくならないかもしれません。
興味ある方は、試してみて下さい。