
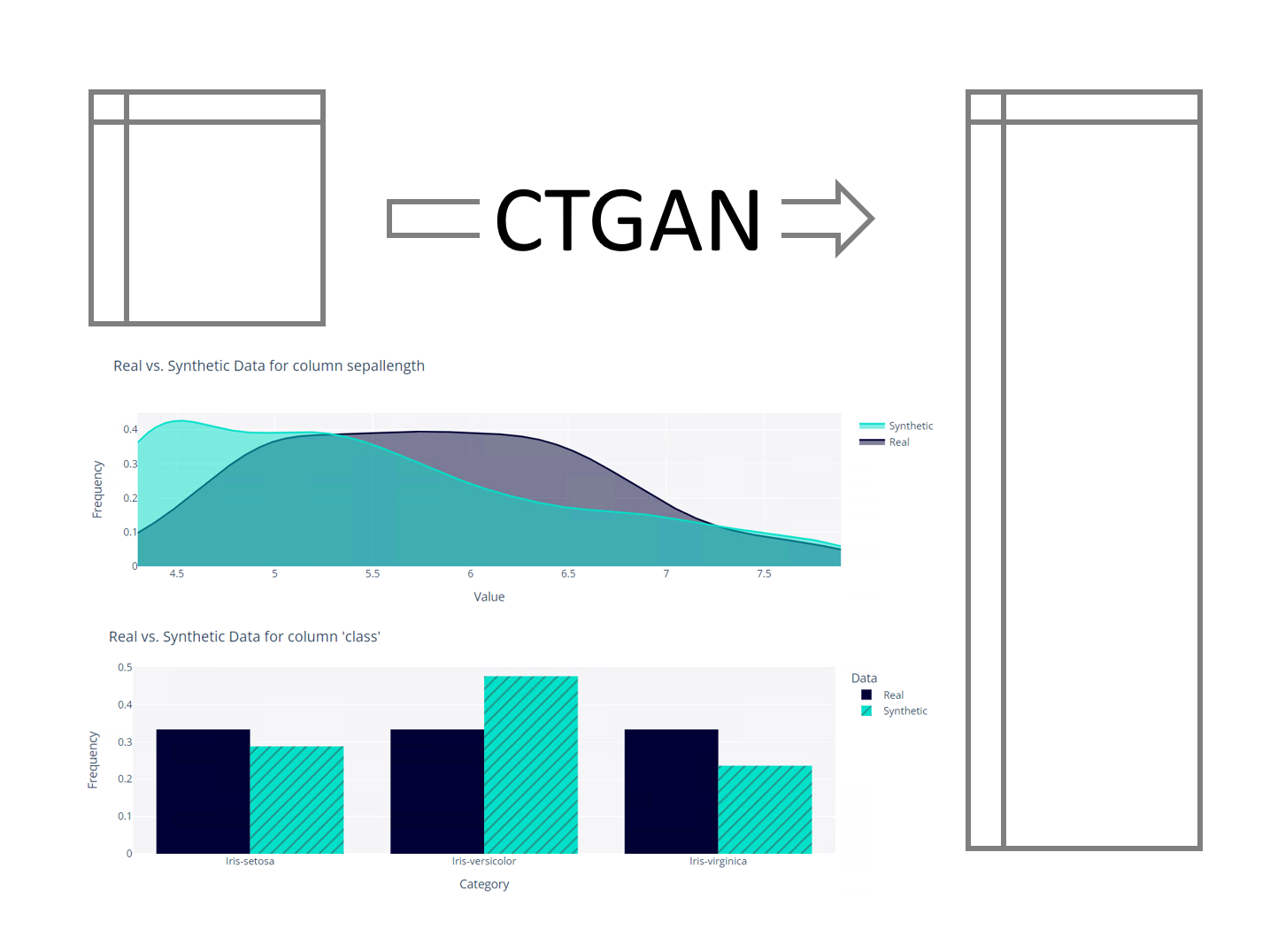
テーブルデータを生成するGANもあります。CTGAN(Conditional General Adversarial Networks)です。
あらかじめ準備されたデータをもとに、擬似的なテーブルデータを生成することができます。
CTGAN(Conditional General Adversarial Networks)で、手軽にテーブルデータを生成することができますが、無邪気に生成すると、ちょっと変なデータが生成されることがあります。
データセットのすべての行が従わなければならないルールがあるからです。
例えば……
- 非負でなければならない変数
- ある値の範囲内に収まる必要のある変数
- 他の変数よりも大きな値でなければならない変数
テーブルデータを生成するとき、このような制約を満たす必要があります。
制約の中には、よくある制約というものがあります。
よくある制約は、PythonのSDVパッケージの中で、事前に定義されています。
ただただ、その事前定義された制約を活用することで、従うべき制約を満たしたテーブルデータを生成することができます。
今回は、事前制約された制約を課しCTGANでテーブルデータを生成していきます。
事前に定義されていないような制約を課したい場合には、前回の以下の記事を参考にして頂ければと思います。
事前定義された制約クラス
事前定義された制約クラスには、2種類あります。
- シングルカラム制約
- マルチカラム制約
シングルカラム制約とは、1つの変数だけに課される制約のことです。
| 制約クラス | 説明 | 例 |
|---|---|---|
| Positive | 列のすべての値は >0 でなければならない | 価格は正でなければならない |
| Negative | 列のすべての値は <0 でなければならない | 借金は負でなければならない |
| ScalarInequality | 列のすべての値は固定の下限または上限を持つ | すべての購買日の値は2020年1月1日以降でなければならない |
| ScalarRange | 列のすべての値は固定の下限と上限を持つ | 単価のすべての値は0から1000,000の間でなければならない |
| FixedIncrements | すべての数値は全数の増分である | 給与のすべての値は1000で割り切れる必要がある |
マルチカラム制約とは、他の変数との関係性を考慮し課される制約です。
| 制約クラス | 説明 | 例 |
|---|---|---|
| FixedCombinations | データで既に観察されているもの以外のシャッフルは許可されない | 国と市の値は新たな組み合わせを作るためにシャッフルすることはできない |
| OneHotEncoding | 元のデータ列はワンホットエンコーディングスキームを表す | 曜日は次のいずれか1つが各行で1を持つ 月、火、水、木、金、土、日 |
| Inequality | 一つの列の値は常に他の列の値よりも大きくなければならない | checkout_dateは常にcheckin_dateよりも後でなければならない |
| Range | 一つの列の値は他の列の値によって制約される | parent_ageはchild_ageとgrandparent_ageの間でなければならない |
制約クラスを指定し、そのパラメータの値を設定することで、制約を課します。
構文は、以下です。
# 制約定義
my_constraint = {
'constraint_class': <制約クラス名を記載>,
'constraint_parameters': {
<パラメータの値を記載>
}
}
この制約をテーブルデータ生成モデル(例ではctgan)に追加するときは、以下のコードで追加します。
# 制約追加
ctgan.add_constraints(constraints=[
my_constraint
])
必要なモジュールとデータセットの読み込み
先ず、必要なモジュールを読み込みます。
以下、コードです。
# 基本モジュール
import pandas as pd
import numpy as np
# SVD
from sdv.single_table import CTGANSynthesizer
from sdv.metadata import SingleTableMetadata
# サンプルデータ取得用(sklearn.datasets)
from sklearn.datasets import fetch_openml
import warnings
warnings.simplefilter('ignore')
サンプルデータは、みんな大好きアヤメ(iris)のデータセットになります。

- Sepal Length: がく片の長さ
- Sepal Width: がく片の幅
- Petal Length: 花びらの長さ
- Petal Width: 花びらの幅
- Species: アヤメの種類(セトサ種・バージニカ種・バージカラー種)
データセットを読み込みます。
以下、コードです。
# データセットの読み込み dataset = fetch_openml(data_id=61, parser='auto') real_data = dataset['frame'] print(real_data) #確認
以下、実行結果です。
sepallength sepalwidth petallength petalwidth class 0 5.1 3.5 1.4 0.2 Iris-setosa 1 4.9 3.0 1.4 0.2 Iris-setosa 2 4.7 3.2 1.3 0.2 Iris-setosa 3 4.6 3.1 1.5 0.2 Iris-setosa 4 5.0 3.6 1.4 0.2 Iris-setosa .. ... ... ... ... ... 145 6.7 3.0 5.2 2.3 Iris-virginica 146 6.3 2.5 5.0 1.9 Iris-virginica 147 6.5 3.0 5.2 2.0 Iris-virginica 148 6.2 3.4 5.4 2.3 Iris-virginica 149 5.9 3.0 5.1 1.8 Iris-virginica [150 rows x 5 columns]
どのようなデータなのか見てみます。
以下、コードです。
real_data.info()
以下、実行結果です。
<class 'pandas.core.frame.DataFrame'> RangeIndex: 150 entries, 0 to 149 Data columns (total 5 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 sepallength 150 non-null float64 1 sepalwidth 150 non-null float64 2 petallength 150 non-null float64 3 petalwidth 150 non-null float64 4 class 150 non-null category dtypes: category(1), float64(4) memory usage: 5.1 KB
「class」列は、category型の質的変数です。
現段階(2023年6月19日現在)では、質的変数はobject型でないと処理できないため、category型の質的変数をobject型の質的変数へ変換します。
以下、コードです。
# カテゴリー型をオブジェクト型に変換
category_columns = real_data.select_dtypes(include=['category']).columns
real_data[category_columns] = real_data[category_columns].astype('object')
念のため、確認します。
以下、コードです。
real_data.info()
以下、実行結果です。
<class 'pandas.core.frame.DataFrame'> RangeIndex: 150 entries, 0 to 149 Data columns (total 5 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 sepallength 150 non-null float64 1 sepalwidth 150 non-null float64 2 petallength 150 non-null float64 3 petalwidth 150 non-null float64 4 class 150 non-null object dtypes: float64(4), object(1) memory usage: 6.0+ KB
量的変数の基本統計量を見てみます。
以下、コードです。
print(real_data.describe())
以下、実行結果です。
sepallength sepalwidth petallength petalwidth count 150.000000 150.000000 150.000000 150.000000 mean 5.843333 3.054000 3.758667 1.198667 std 0.828066 0.433594 1.764420 0.763161 min 4.300000 2.000000 1.000000 0.100000 25% 5.100000 2.800000 1.600000 0.300000 50% 5.800000 3.000000 4.350000 1.300000 75% 6.400000 3.300000 5.100000 1.800000 max 7.900000 4.400000 6.900000 2.500000
各量的変数は正の値であり、ある範囲内に収まっている状況が分かります。
3つの事前制約クラスを使い、例として正の値の制約を課していきます。
- Positive制約
- ScalarInequality制約
- ScalarRange制約
似たような制約を課していきます。
データ生成その1(無制約)
先ずに、制約を課さずに、テーブルデータを生成します。
以下、コードです。
# インスタンス生成 ctgan = CTGANSynthesizer(metadata) # 学習 ctgan.fit(real_data) # データ生成 synthetic_data = ctgan.sample(1000) # 生成したデータを確認 print(synthetic_data)
以下、実行結果です。
sepallength sepalwidth petallength petalwidth class 0 6.3 3.9 2.2 1.9 Iris-versicolor 1 7.1 2.1 1.0 0.9 Iris-versicolor 2 4.3 2.0 3.4 1.5 Iris-setosa 3 5.2 3.2 2.7 1.7 Iris-setosa 4 5.4 2.9 1.0 1.8 Iris-versicolor .. ... ... ... ... ... 995 7.1 2.4 3.3 1.3 Iris-versicolor 996 5.6 2.1 5.5 2.0 Iris-versicolor 997 5.6 3.3 1.0 1.0 Iris-versicolor 998 4.9 3.2 3.4 0.9 Iris-versicolor 999 4.3 2.7 3.0 1.0 Iris-virginica [1000 rows x 5 columns]
データ生成その2(制約追加)
インスタンスを生成します。
以下、コードです。
# インスタンス生成 ctgan = CTGANSynthesizer(metadata)
Positive制約を’sepallength‘に課します。
以下、コードです。
# 制約定義
my_constraint = {
'constraint_class': 'Positive',
'constraint_parameters': {
'column_name': 'sepallength',
'strict_boundaries': True
}
}
# 制約追加
ctgan.add_constraints(constraints=[
my_constraint
])
my_constraintの中は以下のようになっています。
'constraint_class': これは制約の種類を表す文字列です。この場合、'Positive'という値が設定されており、これは対象となる列のすべての値が正(つまり0より大きい)であることを要求する制約を表しています。'constraint_parameters': これは制約の詳細を指定するための辞書です。この辞書には以下のキーと値が含まれています。'column_name': この制約が適用される列の名前を表す文字列です。この場合、'sepallength'という列に制約が適用されます。'strict_boundaries': この制約が厳密な境界を持つかどうかを表すブール値(真偽値)です。Trueが設定されている場合、列の値は厳密に0より大きくなければならないことを意味します。Falseが設定されている場合、列の値は0を含むことが許容されます。
したがって、このコードはsepallengthという列のすべての値が厳密に0より大きいであること」を要求する制約を定義しています。
課されている制約を確認します。
以下、コードです。
# 課されている制約の確認 ctgan.get_constraints()
以下、実行結果です。
[{'constraint_class': 'Positive',
'constraint_parameters': {'column_name': 'sepallength',
'strict_boundaries': True}}]
制約が追加されていることが分かります。
ScalarInequality制約を’ScalarInequality‘に課します。
以下、コードです。
# 制約定義
my_constraint = {
'constraint_class': 'ScalarInequality',
'constraint_parameters': {
'column_name': 'sepalwidth',
'relation': '>',
'value': 0
}
}
# 制約追加
ctgan.add_constraints(constraints=[
my_constraint
])
my_constraintの中は以下のようになっています。
'constraint_class': これは制約の種類を表す文字列です。この場合、'ScalarInequality'という値が設定されており、これは対象となる列のすべての値が特定の値より大きい(または小さい)であることを要求する制約を表しています。'constraint_parameters': これは制約の詳細を指定するための辞書です。この辞書には以下のキーと値が含まれています。'column_name': この制約が適用される列の名前を表す文字列です。この場合、'sepalwidth'という列に制約が適用されます。'relation': 列の値と指定した値との関係を表す文字列です。この場合、'>'が設定されているので、列の値は指定した値より大きくなければならないことを意味します。'value': 列の値と比較される値です。この場合、列の値はこの値(0)より大きくなければならないことを意味します。
したがって、このコードはsepalwidthという列のすべての値が0より大きいであること」を要求する制約を定義しています。
課されている制約を確認します。
以下、コードです。
# 課されている制約の確認 ctgan.get_constraints()
以下、実行結果です。
[{'constraint_class': 'Positive',
'constraint_parameters': {'column_name': 'sepallength',
'strict_boundaries': True}},
{'constraint_class': 'ScalarInequality',
'constraint_parameters': {'column_name': 'sepalwidth',
'relation': '>',
'value': 0}}]
制約が追加されていることが分かります。
ScalarRange制約を’ScalarRange‘に課します。
以下、コードです。
# 制約定義
my_constraint = {
'constraint_class': 'ScalarRange',
'constraint_parameters': {
'column_name': 'petallength',
'low_value': 0.0,
'high_value': 10.0,
'strict_boundaries': False
}
}
# 制約追加
ctgan.add_constraints(constraints=[
my_constraint
])
my_constraintの中は以下のようになっています。
'constraint_class': これは制約の種類を表す文字列です。この場合、'ScalarRange'という値が設定されており、これは対象となる列のすべての値が特定の範囲内にあることを要求する制約を表しています。'constraint_parameters': これは制約の詳細を指定するための辞書です。この辞書には以下のキーと値が含まれています。'column_name': この制約が適用される列の名前を表す文字列です。この場合、'petallength'という列に制約が適用されます。'low_value'と'high_value': 列の値が存在すべき範囲の下限と上限を表す値です。この場合、列の値はこの範囲(0.0から10.0)内に存在しなければならないことを意味します。'strict_boundaries': この制約が厳密な境界を持つかどうかを表すブール値(真偽値)です。Trueが設定されている場合、列の値は厳密に指定した範囲内に存在しなければならないことを意味します。Falseが設定されている場合、列の値は範囲の境界を含むことが許容されます。
したがって、このコードはpetallengthという列のすべての値が0.0から10.0の範囲内に存在すること(ただし、範囲の境界は含まれる)」を要求する制約を定義しています。
課されている制約を確認します。
以下、コードです。
# 課されている制約の確認 ctgan.get_constraints()
以下、実行結果です。
[{'constraint_class': 'Positive',
'constraint_parameters': {'column_name': 'sepallength',
'strict_boundaries': True}},
{'constraint_class': 'ScalarInequality',
'constraint_parameters': {'column_name': 'sepalwidth',
'relation': '>',
'value': 0}},
{'constraint_class': 'ScalarRange',
'constraint_parameters': {'column_name': 'petallength',
'low_value': 0.0,
'high_value': 10.0,
'strict_boundaries': False}}]
制約が追加されていることが分かります。
3つの制約が課された状態で、テーブルデータを生成します。
以下、コードです。
# 学習 ctgan.fit(real_data) # データ生成 synthetic_data = ctgan.sample(1000) # 生成したデータを確認 print(synthetic_data)
以下、実行結果です。
sepallength sepalwidth petallength petalwidth class 0 6.3 2.9 4.2 1.3 Iris-versicolor 1 5.9 2.4 2.3 0.3 Iris-virginica 2 6.3 2.4 1.0 0.4 Iris-versicolor 3 6.5 2.2 4.6 0.1 Iris-versicolor 4 4.7 2.6 4.2 2.3 Iris-virginica .. ... ... ... ... ... 995 6.3 3.8 2.1 0.7 Iris-virginica 996 4.9 2.4 2.5 2.0 Iris-versicolor 997 5.5 2.7 2.7 0.3 Iris-setosa 998 6.6 2.4 2.7 0.4 Iris-versicolor 999 5.6 2.3 2.5 0.3 Iris-versicolor [1000 rows x 5 columns]
まとめ
今回は、事前制約された制約を課しCTGANでテーブルデータを生成する方法を、例を使い説明しました。
PythonのSDVパッケージの中に、CTGAN以外のテーブルデータを生成できるアルゴリズムが実装されています。
次回説明します。