
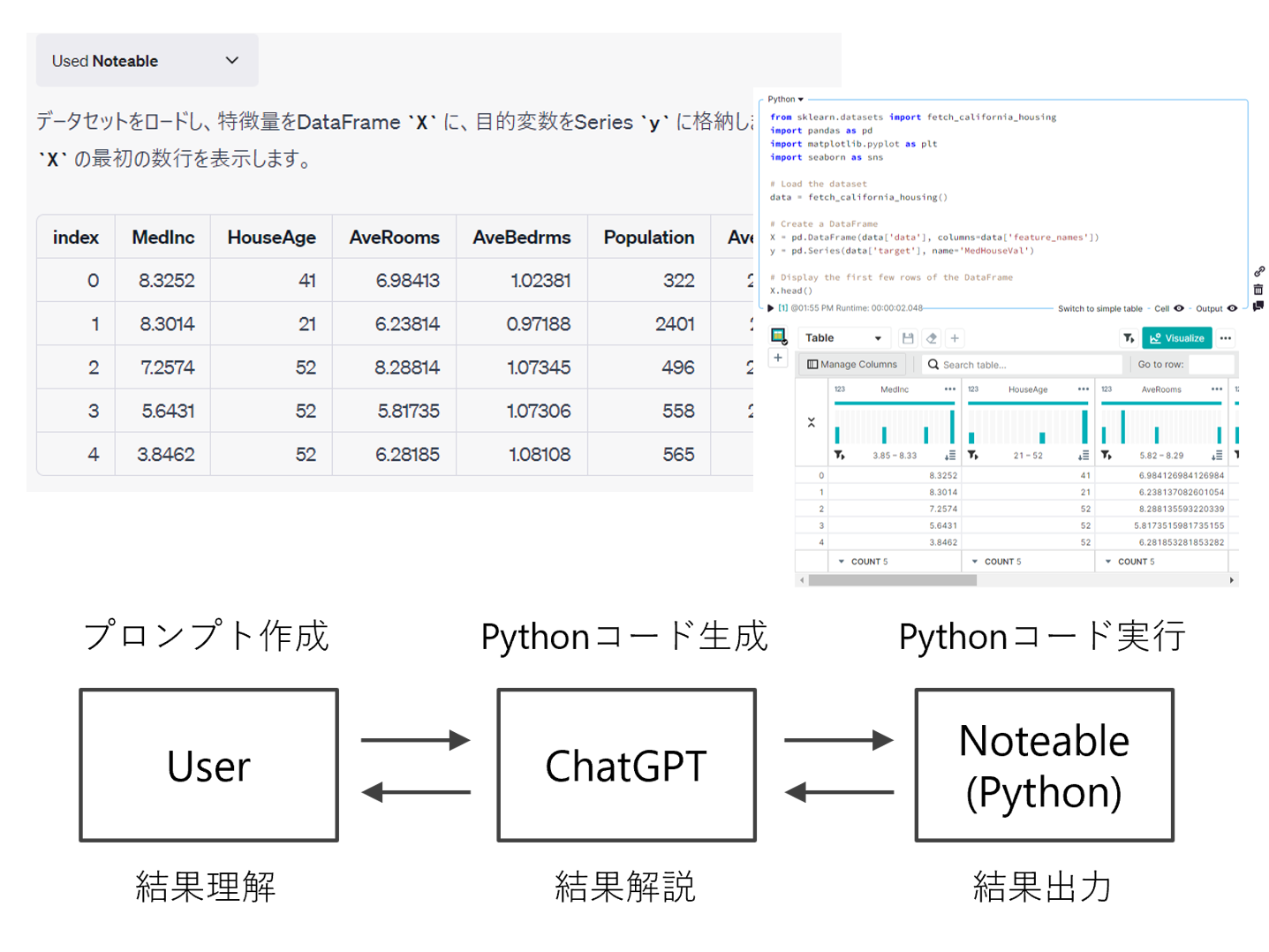
ChatGPTにお願いし、データ分析をすることができます。
いくつかやり方があります。
例えば……
- Jupyter AIで、Jupyter上で実施する方法
- Noteableプラグインで、ChatGPT上で実施する方法
- Code Interpreterで、ChatGPT上で実施する方法
……などなど。
Jupyter AIで、Jupyter上で実施する方法については、以前お話ししました。
Jupyter AIは、ChatGPT以外の生成AIとも連携することができます。Notebook上で機能します。
ChatGPT上で実施する方法としては、今現在(2023年7月12日)だと、Noteableと連携する方法か、Code Interpreterによる方法でしょう(たぶん)。
ちなみに、Noteableはクラウド上のNotebookプラットフォームです。
以前お話ししました。
ChatGPTのNoteableプラグインを使うことで、ChatGPT経由でNoteableを動かすことことができます。

似たようなPythonによるデータ分析を、Code Interpreterプラグインを使いChatGPT上ですることが可能ですが、ちょっとした違いがあります。
今現在(2023年7月12日)、NoteableプラグインとCode Interpreterプラグインには、使えるライブラリーに違いがあります。
Noteableプラグインを使ったデータ分析は、裏でNoteableが動いているため、NoteableのPython環境をユーザが設定することで、ChatGPTを使ったデータ分析の環境を設定することができます。
操作できるとは、例えば使いたいPythonライブラリーをインストールしたり、最新の状態にしたり、逆に古い状態にしたりと、自由にできるということでうす。
また、Noteableプラグインを使ったデータ分析をした場合、ChatGPT経由で実施したデータ分析のNotebookファイルが生成されています。
ただ、Noteableと連携する方法とCode Interpreterによる方法のどちらも、今現在(2023年7月12日)、裏で動いているクラウドのマシンが貧弱なため、実行速度が遅いです(体感ですが……)。
何はともあれ、今回はNoteableプラグインを使い、ChatGPT上でデータ分析を実施する方法について紹介します。
Contents [hide]
Noteableの準備
以下の記事を参考に、Noteableのアカウントを作成しておいてください。
Noteable上に、ChatGPTと連結するProjectを作成しておいてください。
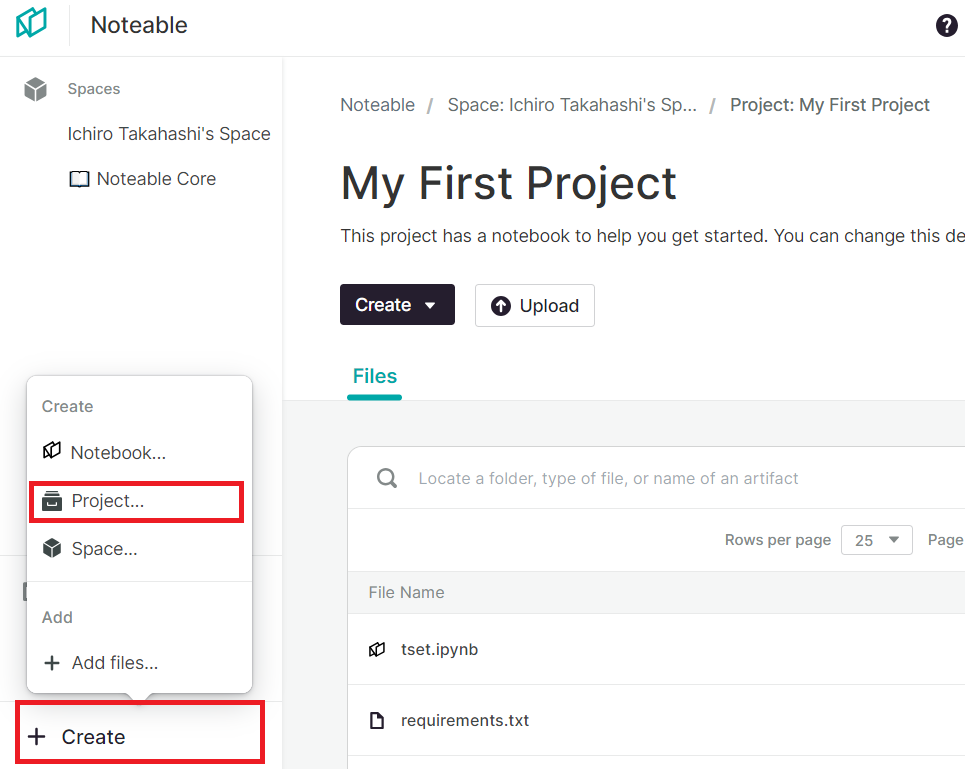
今回は、デフォルトで作成されている(最初から作成されている)プロジェクト「My First Project」を使います。
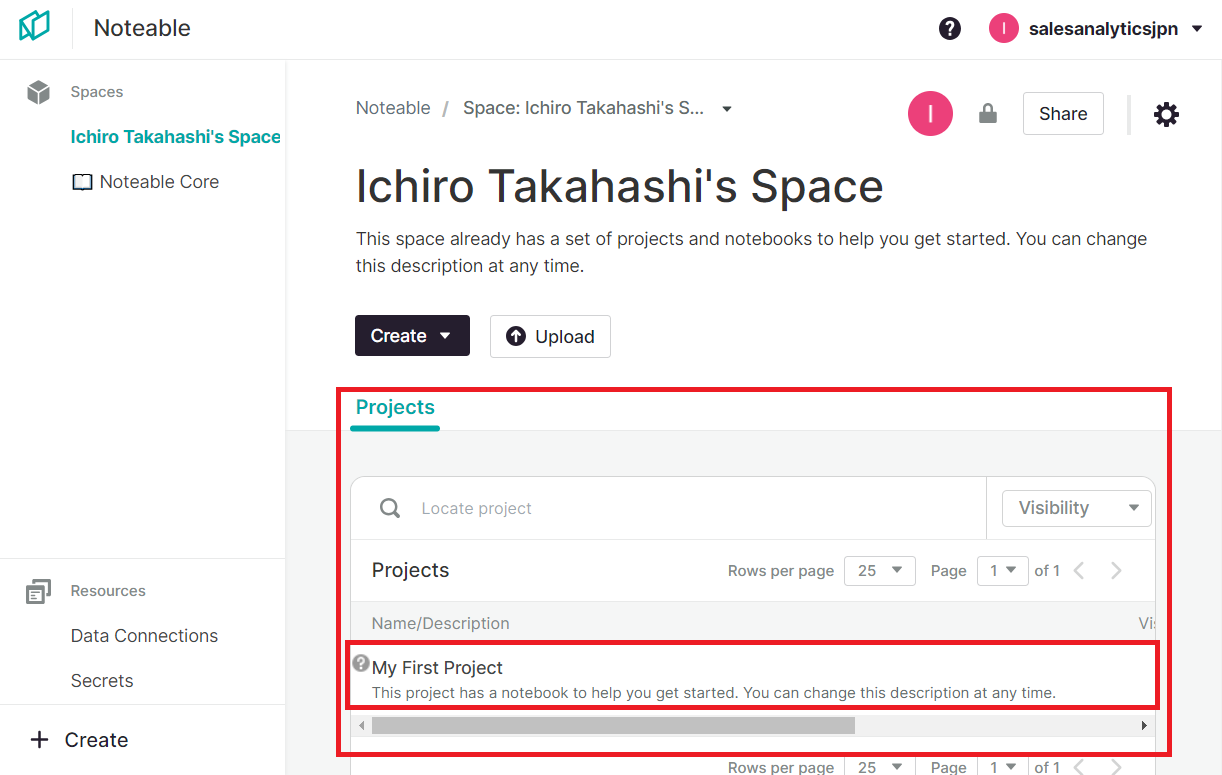
このプロジェクトのURLをコピーしておいてください。後で、ChatGPTに渡します。
始めるには?
ChatGPTで、Noteableプラグインを有効にする必要があります。
すでに、ChatGPTのプラグインの使い方を知っている方は、ここは読み飛ばし、Noteableプラグインを有効にして下さい。
以下は、ChatGPTのプラグインの使い方を知らない方のための説明です。
先ず、OpenAIにログインしChatGPTに入ります。

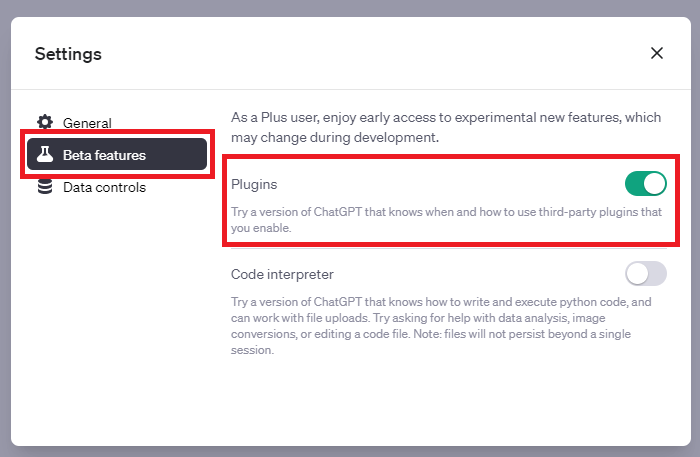
ChatGPTの画面の左下にある「…」をクリックし「Setting」を選択します。

Settingの画面が表示されますので、「Beta features」で「Plugins」を有効にします。
次に、GPT4を選択し「Plugins」をクリックします。
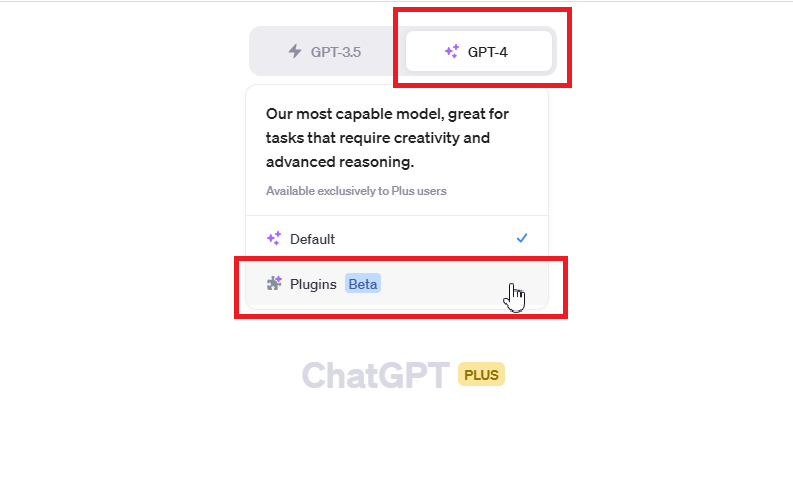
「No plugins enabled」をクリックし「Plugin store」を選択します。
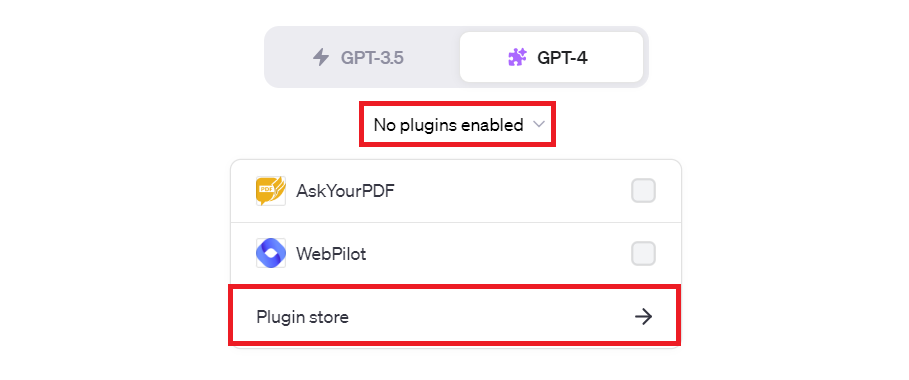
ちなみに、何かしらプラグインを選択している場合には、「No plugins enabled」ではなくプラグインのアイコンが表示されていますので、そのアイコンをクリックします。
Plugin storeが表示されましたら、「Noteable」を探し「Install」をクリックします。
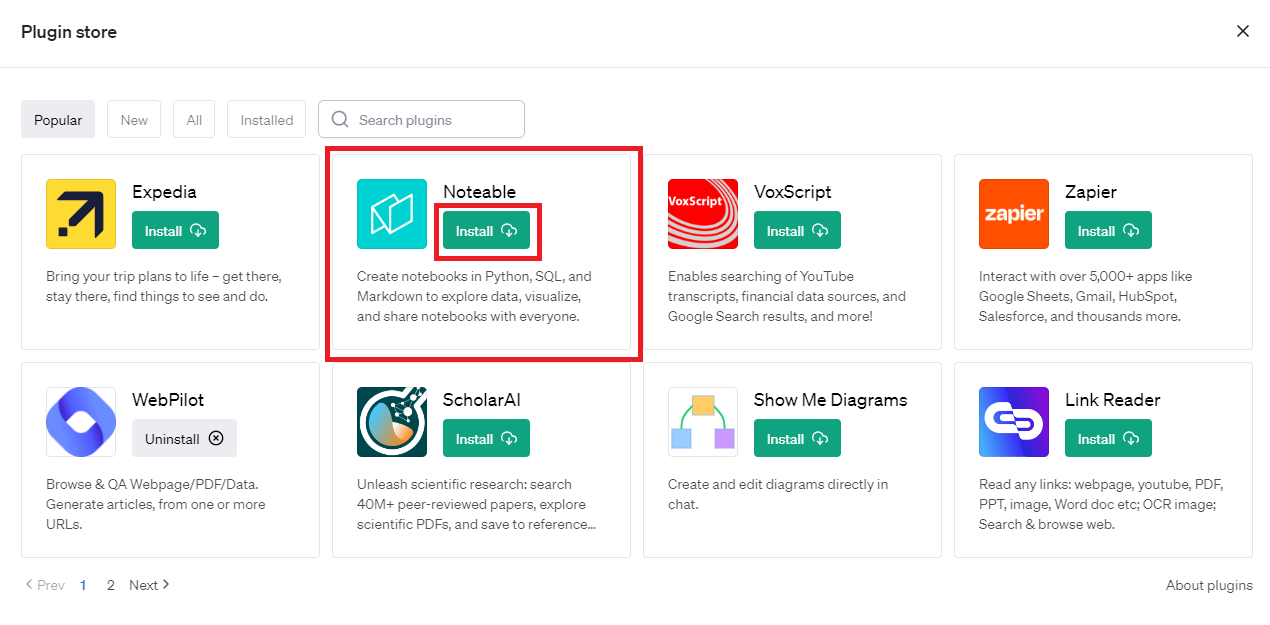
以上で準備は終了です。
今回利用するデータセット
今回はscikit-learnから提供されているカリフォルニアの住宅価格データセットを使います。
【今回使用】
scikit-learnから提供されているサンプルデータセット
https://scikit-learn.org/stable/datasets/index.html#california-housing-dataset
データ数は20640件です。
目的変数は、カリフォルニアの区画ごとの住宅価格の中央値です。
特徴量(説明変数)は、以下の8個です。
| 項目名 | 詳細 |
| MedInc | 区画の収入の中央値 |
| HouseAge | 区画の築年数 |
| AveRoom | 区画の家の部屋数の平均値 |
| AveBedrms | 区画の寝室の平均値 |
| Population | 区画の人口 |
| AveOccup | 区画の平均入居率 |
| Latitude | 区画の緯度 |
| Longitude | 区画の経度 |
ChatGPTでデータ分析する
Noteableプロジェクトの指定
NoteableプロジェクトのURLをChatGPTへ渡します。
以下、プロンプト文です。※URLは、今回の例のURLなので人によって異なります。
以下のプロジェクトを使います。 https://app.noteable.io/p/2de0c6fa-145e-40bb-835c-3893d6b399f1/My-First-Project
以下、ChatGPTのやり取りです。
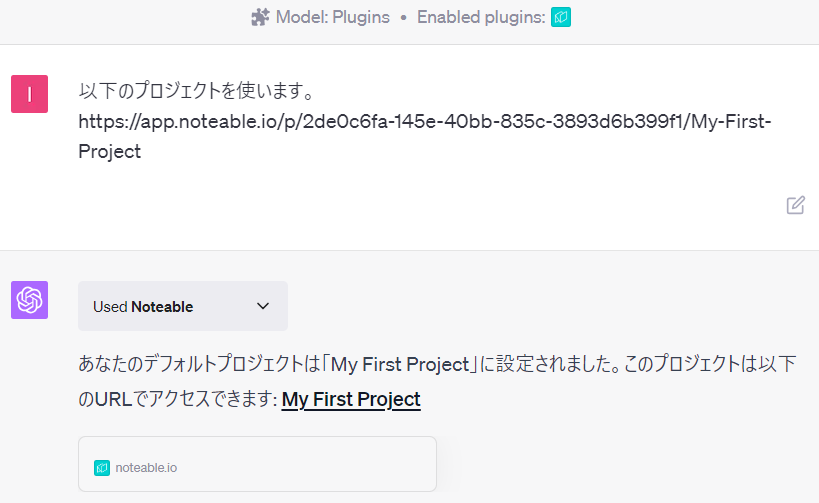
指定したNoteableのプロジェクト内に、Notebookが作られそこでデータ分析が行われ記録されます。
そのNotebookは、Noteableで見ることも別途実行することもできます。
データセットの読み込みとEDA
先ず、利用するデータセットを読み込み、簡単なEDA(探索的データ分析)を実施します。
以下、プロンプト文です。
scikit-learnから提供されているカリフォルニアの住宅価格データセット(fetch_california_housing)を使います。 目的変数はyに、特徴量はXに格納して下さい。 データ理解のために、データの可視化と探索的データ分析をして下さい。
以下、ChatGPTとのやり取りです。
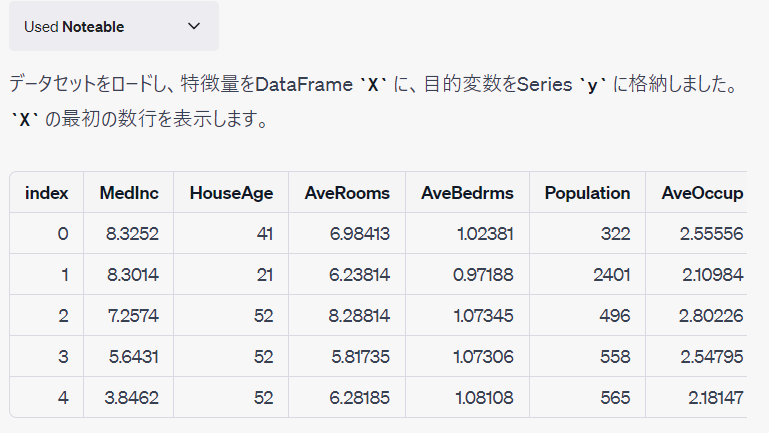
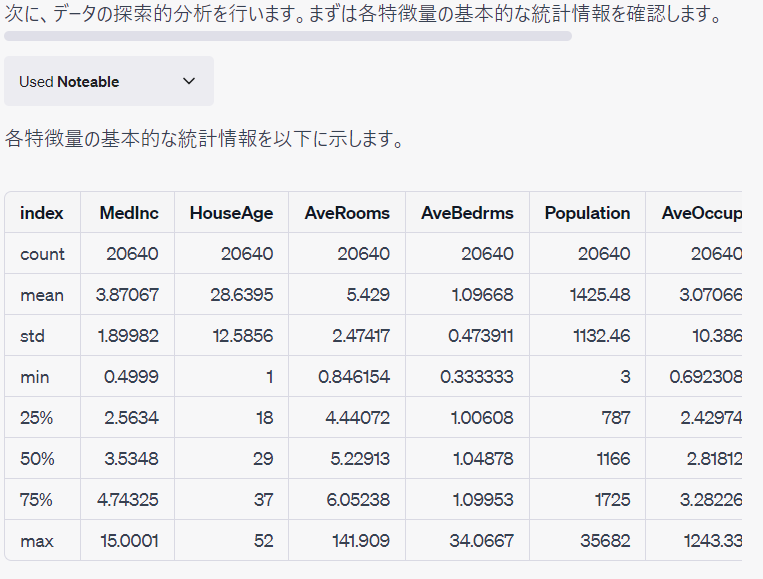
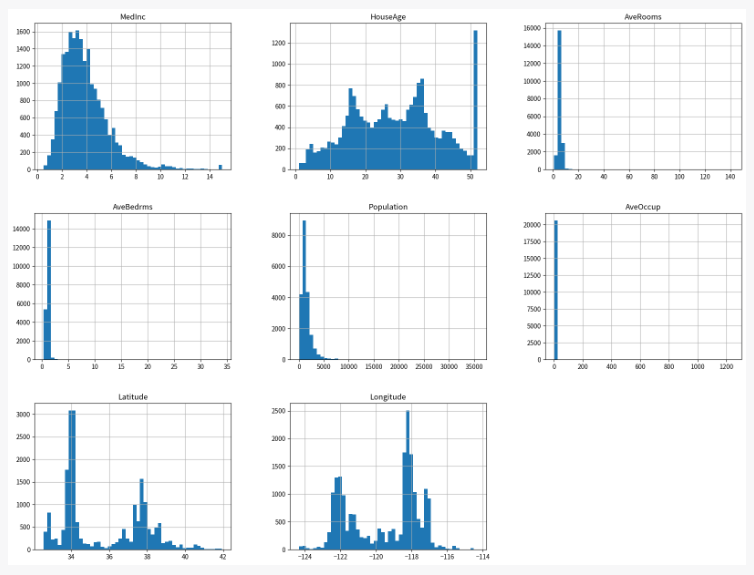

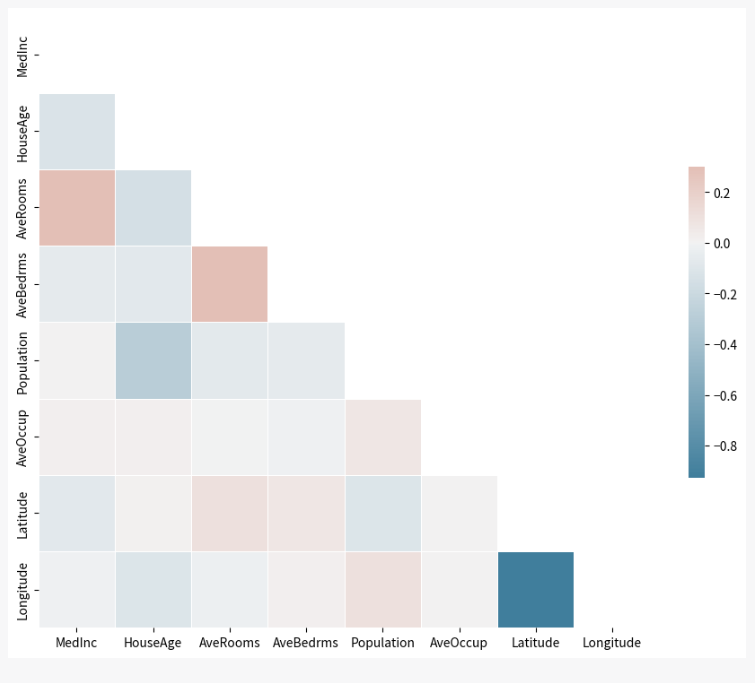

予測モデルの構築
次に、予測モデルを構築していきます。
以下、プロンプト文です。
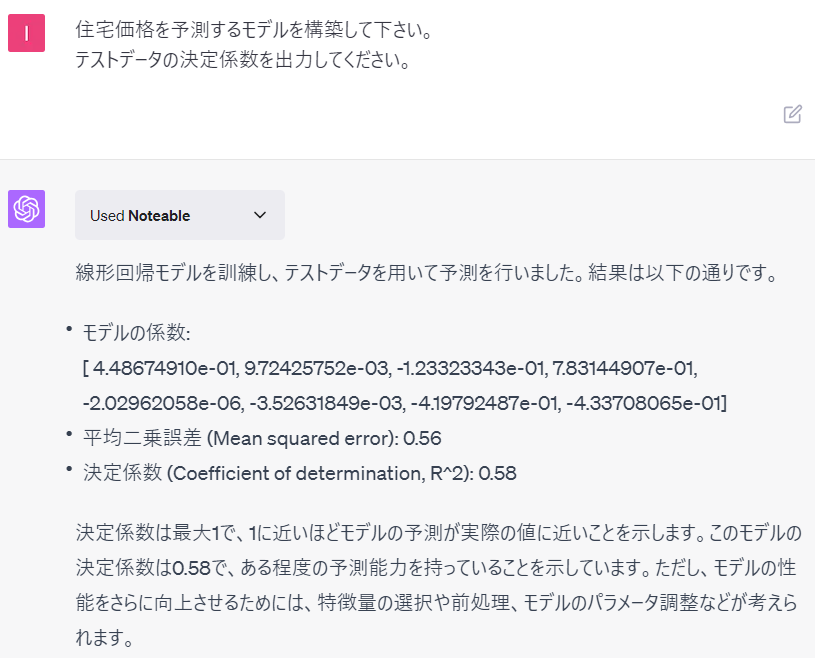
住宅価格を予測するモデルを構築して下さい。 テストデータの決定係数を出力してください。
以下、ChatGPTとのやり取りです。
予測値と実測値の散布図を見てみます。
以下、プロンプト文です。
予測値と実測値の散布図を描いてください。
以下、ChatGPTとのやり取りです。
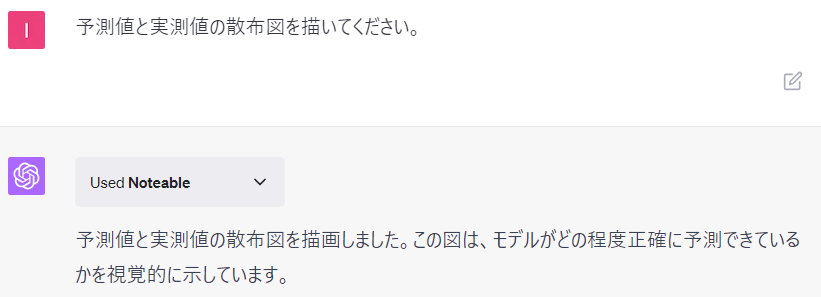
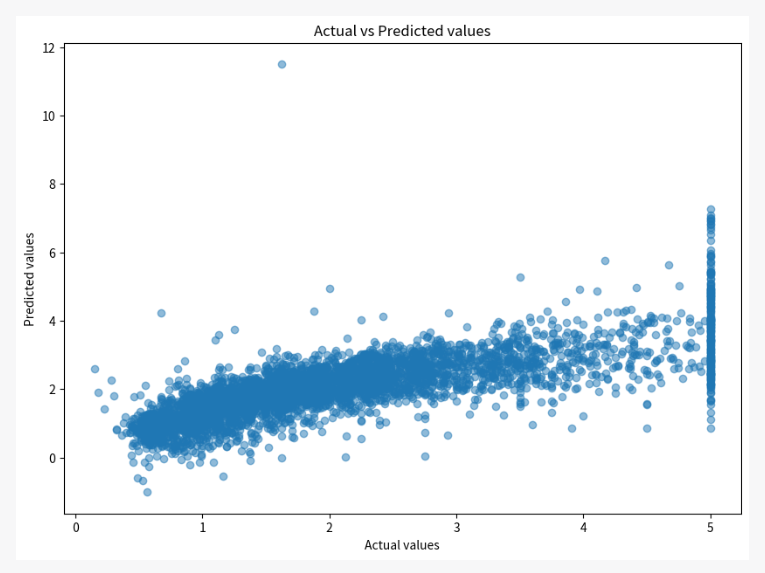

もう少し高い予測精度が欲しいところなので、再度依頼します。
以下、プロンプト文です。
工夫して予測モデルの精度を上げてください。
以下、ChatGPTとのやり取りです。
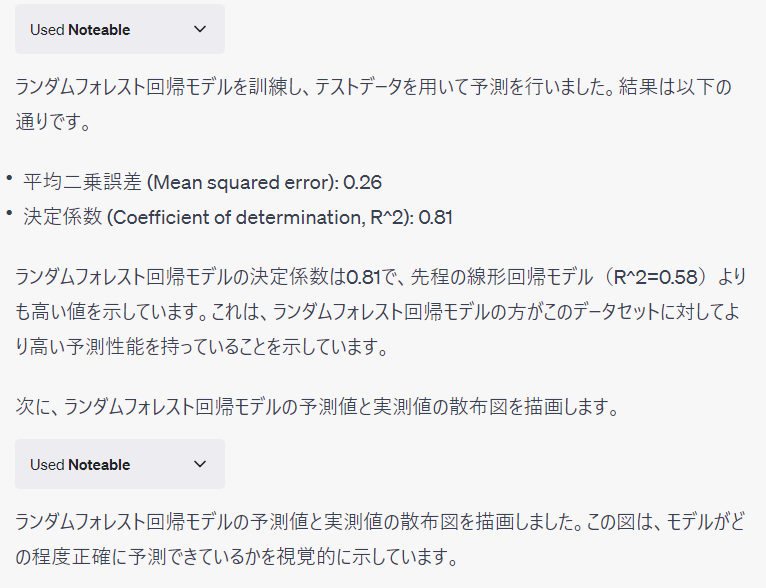
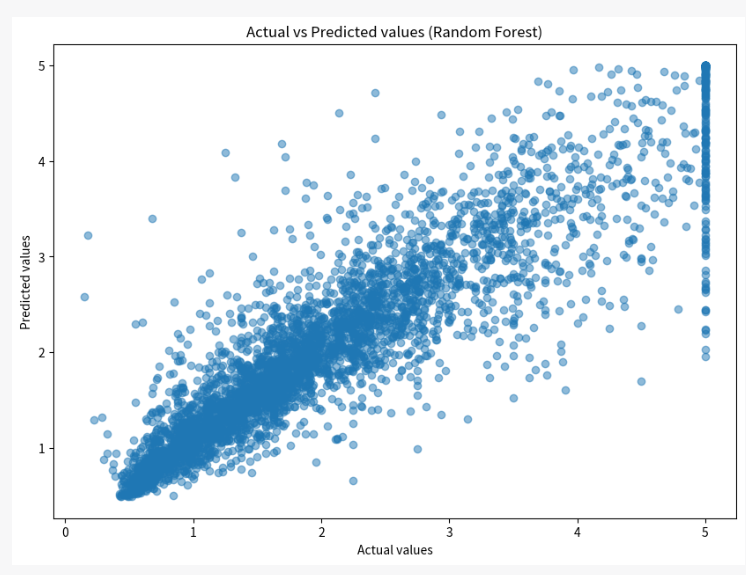

PythonのAutoML(自動機械学習)パッケージであるTPOTを使い、より高精度な予測モデルを作ってもらいます。
以下、プロンプト文です。
TPOTを使い予測モデルの精度を上げてください。
以下、ChatGPTとのやり取りです。そこそこというか、かなり実行時間がかかります。
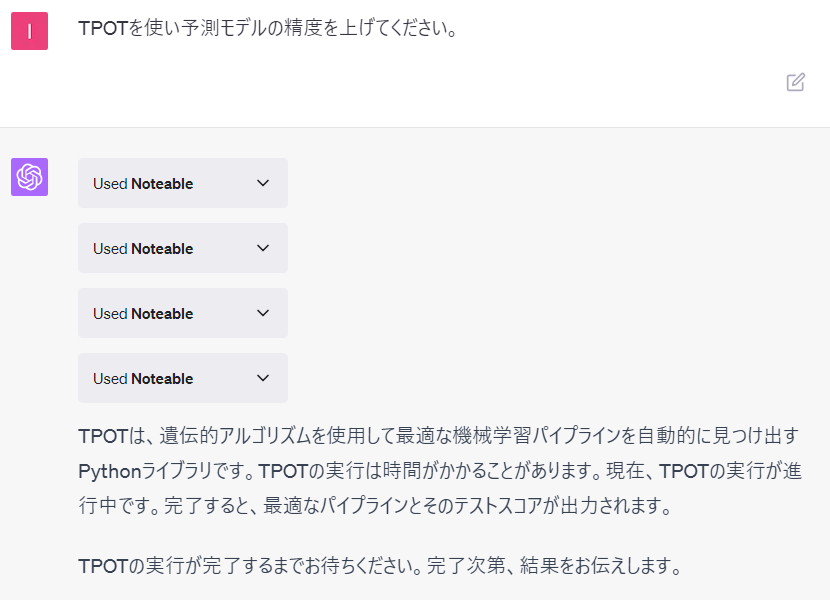
処理が終わったころに、予測精度を聞いてみます。
以下、プロンプト文です。
テストデータを用いて予測を行い、以下の結果を教えてください。 平均二乗誤差 (Mean squared error) 決定係数 (Coefficient of determination, R^2)
以下、ChatGPTとのやり取りです。
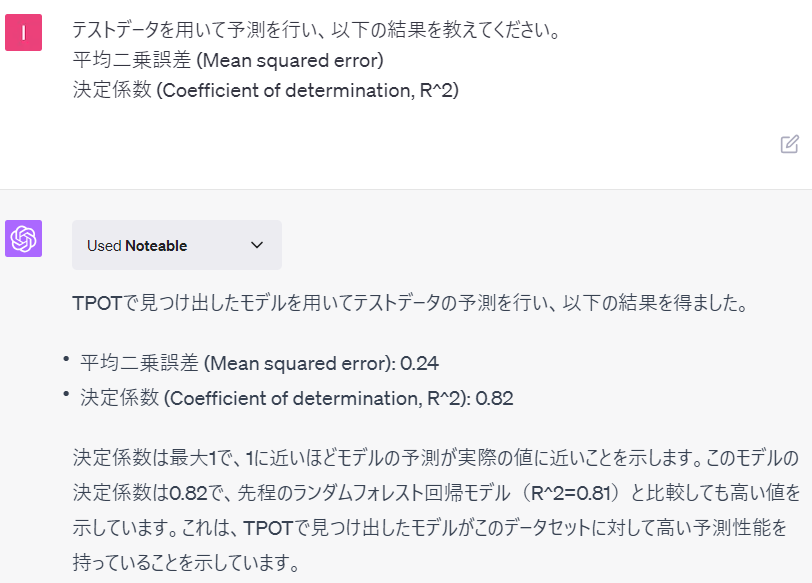
予測精度は良くなっていますが、計算コストと見合うかどうかは判断が分かれるところです。
どのようなモデル(パイプライン)を作ったのか聞いてみます。
以下、プロンプト文です。
TPOTで見つけ出したモデルを説明して下さい。
以下、ChatGPTとのやり取りです。
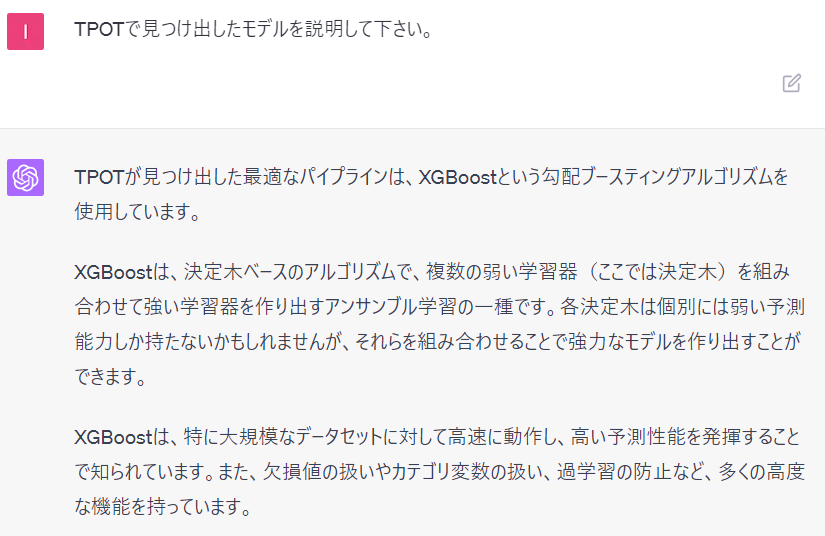

Notebookを見てみる
ChatGPTの裏で、Noteableが実行されデータ分析が行われています。
Notebookが作成されています。
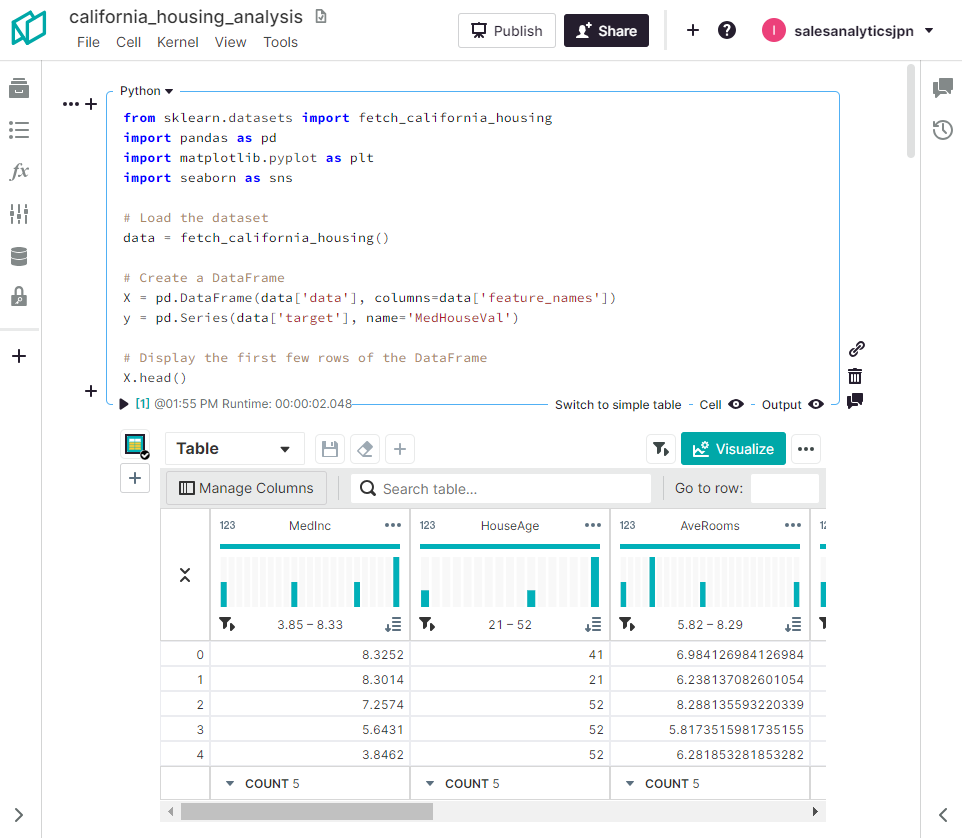
今回は、「california_housing_analysis.ipynb」という名称で作成されていました。
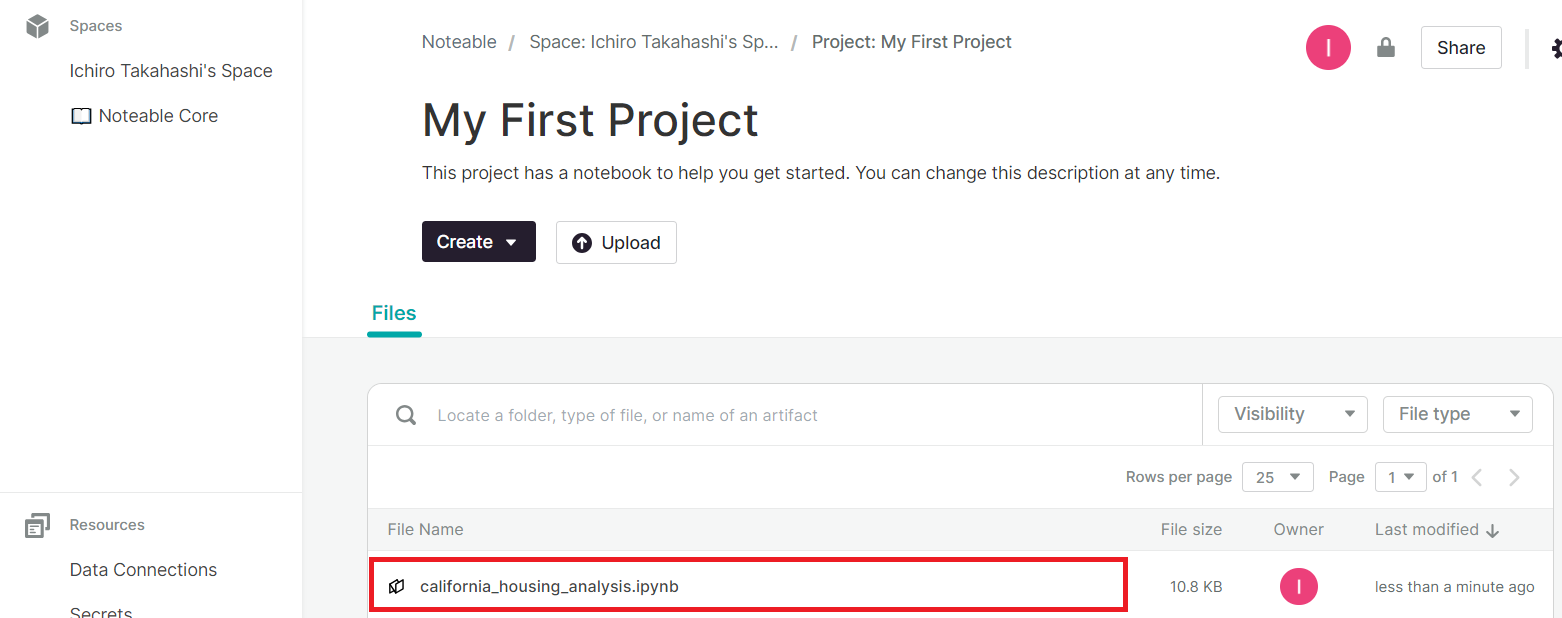
クリックしNotebookの中を見てみると、ChatGPTで実施していたデータ分析のPythonコードやその実行結果を見ることができます。
まとめ
今回は、Noteableプラグインを使い、ChatGPT上でデータ分析を実施する方法について紹介しました。
思ったよりもよくできていると感じました。
ただ、Noteableのマシンが今現在(2023年7月12日現在)やや貧弱なため、処理速度が遅いのが難点です。
そのうち改善されるのかもしれません。
クラウド上のNotebookプラットフォームは他にもあるので、似たようなプラグインがでるのではないかと楽しみです。
また、そもそもプロンプトにどのようなお願いをするのかは、結局のところ、データ分析やデータサイエンス、機械学習などの知識がないと、適切に指示できないのではないかとも感じました。
さらなるそもそも論になりますが、プロンプトにどのようなお願いをするのか以前に、データを使って何をしたいのかを人が考える必要があります。