

OpenAIのGPTなどの言語モデルを使ったWebアプリケーションをらくらく作れる、Pythonのパッケージがあります。
Chainlit(https://github.com/Chainlit/chainlit)です。

以前、ChainlitでChatGPT風のWebアプリケーションの、簡単な作り方を説明しました。
ChatGPTは今現在(2023年7月15日現在)2021年9月までの情報を元に回答するとしています。
新しい情報を与えて回答して欲しいものです。
その願望を叶えるには、どうすればいいでしょうか?
すぐできるやり方として、例えば2つの方法があります。
- ドキュメントを与えて回答してもらう
- インターネット上の情報を検索し回答してもらう
今回は、簡単なPDFドキュメントチャットボットの作り方について説明します。
ちなみに、自作するのは以下のような感じのものです。
Contents [hide]
準備
準備は……
- 必要なPythonパッケージのインストール
- OpenAIのOpenAI APIキーの取得
このコードを実行するには以下のPythonパッケージが必要です。
- os
- shutil
- PyPDF2
- chainlit
- langchain
osとshutilは、Pythonの標準ライブラリであり、Pythonそのものをインストールするときに一緒にインストールされます。
残りの3つのPythonのパッケージをインストールする必要があります。
インストールしていないのパッケージがありましたら、インストールしておいてください。
以下、コードです。
pip install PyPDF2 pip install chainlit pip install langchain
PyPDF2は、PythonでPDFファイルを処理するためのライブラリです。
chainlitは文字通りChainlitそのもので、langchainはGPT3のような大規模言語モデル(Large Language Model: LLM)を利用してサービスの開発をしたいときに便利に使えるPythonパッケージです。
また、OpenAIのOpenAI APIキーが必要となります。
以下の記事を参考に、OpenAIアカウントを作成し、OpenAI APIキーを取得しておいてください。
PDFチャットボットアプリのコード(app_pdf.py)
コード(app_pdf.py)
それでは、PDFファイルからテキストを取得し、そのテキストを使用して言語ベースのチャットボットを作成し、ユーザーとの対話を通じて質問応答を行うWebアプリを作っていきます。
以下のような、アプリの中身を記載したpyファイル(今回は、app_pdf.pyとして保存)を作ります。<OpenAI APIキー>には、あなたのOpenAI APIキーを設定してください。
# 必要なモジュールの読み込み
import os
import shutil
from PyPDF2 import PdfReader
import chainlit as cl
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.chains import RetrievalQAWithSourcesChain
from langchain.chat_models import ChatOpenAI
# 定数設定
OPENAI_API_KEY = "<OpenAI APIキー>"
TEMP_PDF_PATH = "./doc/doc.pdf"
CHUNK_SIZE = 500
CHUNK_OVERLAP = 10
DB_PATH = './.chroma'
MODEL_NAME = "gpt-4"
# OpenAI APIキーの設定
os.environ["OPENAI_API_KEY"] = OPENAI_API_KEY
# PDFファイルを開いてテキストを抽出する関数
async def process_pdf(file):
file = file[0] if isinstance(file, list) else file
with open(TEMP_PDF_PATH, 'wb') as f:
f.write(file.content)
reader = PdfReader(TEMP_PDF_PATH)
return ''.join(page.extract_text() for page in reader.pages)
# テキストを分割し、埋め込みを作成してデータベースを作成する関数
async def create_db(text):
text_splitter = RecursiveCharacterTextSplitter(chunk_size=CHUNK_SIZE, chunk_overlap=CHUNK_OVERLAP)
docs = text_splitter.split_text(text)
metadatas = [{"source": f"{i}-pl"} for i in range(len(docs))]
embeddings = OpenAIEmbeddings()
db = Chroma.from_texts(docs, embeddings, metadatas=metadatas)
return db, docs
# チャットボットの初期化処理
@cl.langchain_factory(use_async=True)
async def init():
file = None
while file is None:
file = await cl.AskFileMessage(content="PDFファイルをアップロードしてください!", accept=["pdf"]).send()
# データベースの初期化
shutil.rmtree(DB_PATH, ignore_errors=True)
# ファイルからテキストを抽出し、データベースを作成
text = await process_pdf(file)
db, docs = await create_db(text)
chain = RetrievalQAWithSourcesChain.from_chain_type(
ChatOpenAI(model=MODEL_NAME,temperature=0),
chain_type="stuff",
retriever=db.as_retriever(),
)
# テキストをユーザーセッションに保存
cl.user_session.set("texts", docs)
file_name = file[0].name if isinstance(file, list) else file.name
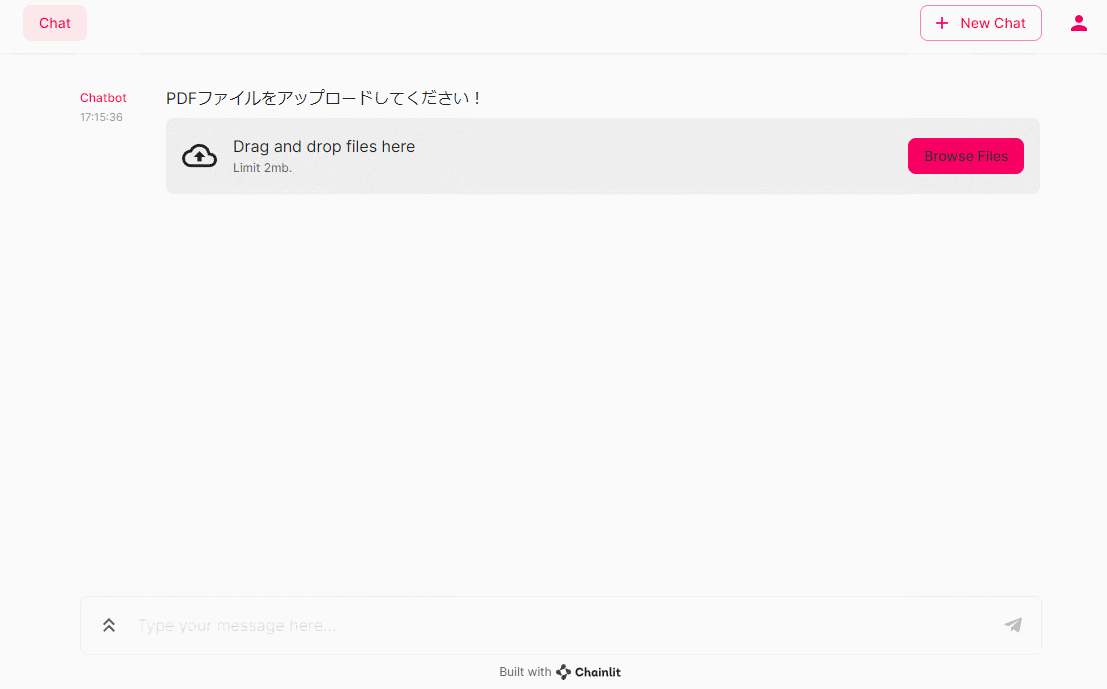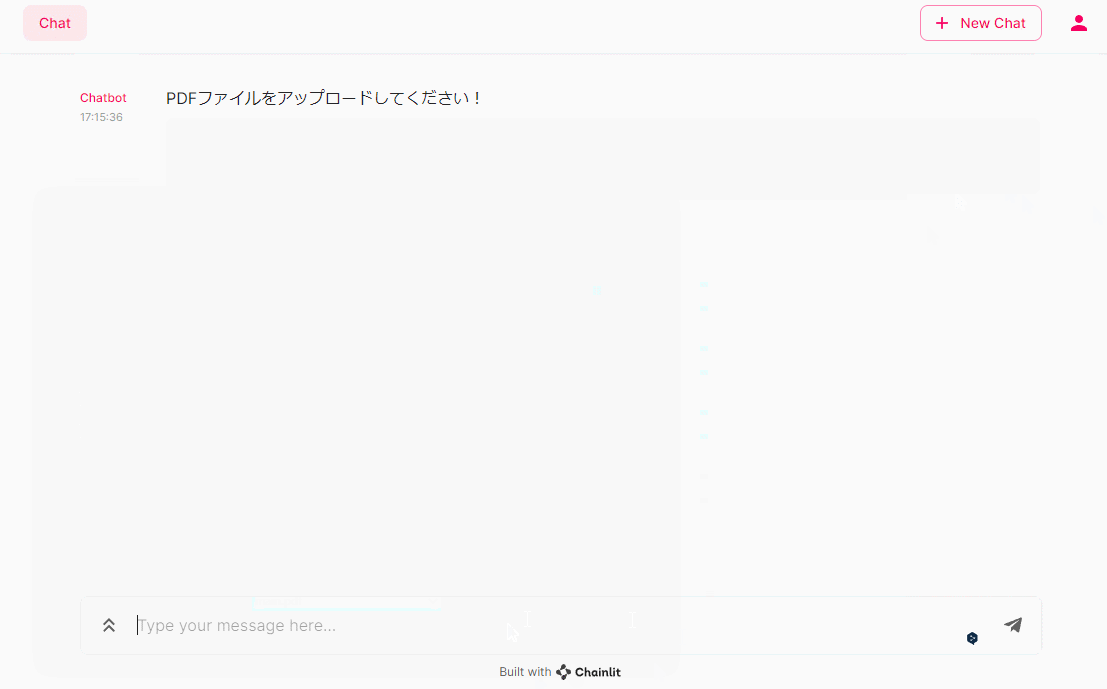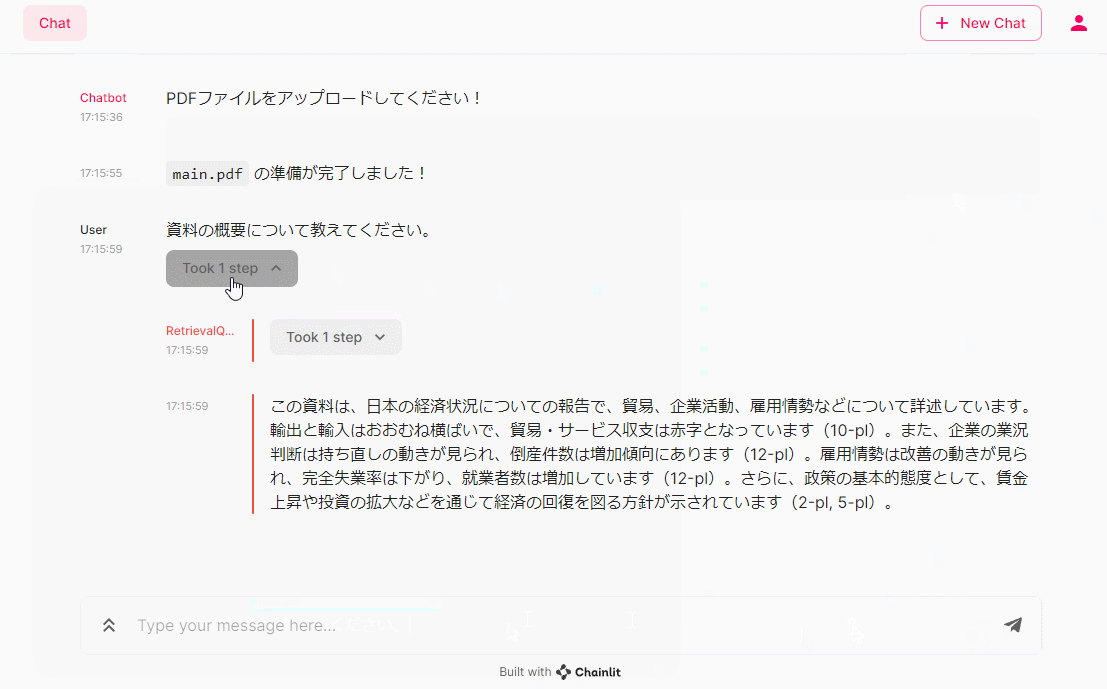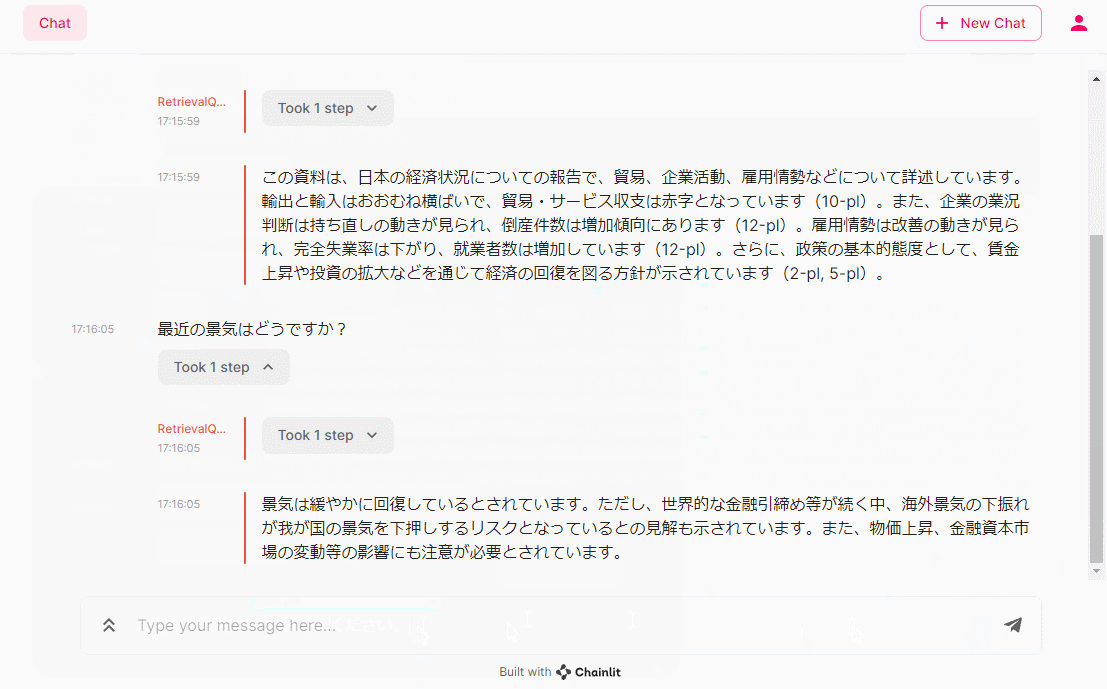
await cl.Message(content=f"`{file_name}` の準備が完了しました!").send()
return chain
# 応答を処理する関数
@cl.langchain_postprocess
def process_response(res):
texts = cl.user_session.get("texts")
sources = res["sources"].strip().split(',')
source_elements = [cl.Text(content=texts[int(s[:s.find('-pl')])], name=s) for s in sources if s]
response = f"{res['answer']} 出典: {res['sources']}"
cl.Message(content=response, elements=source_elements).send()
具体的なステップとしては以下のような流れです。
1. モジュールのインポート
コードの実行に必要な各種モジュールをインポートしています。
2. 定数の設定
次に、必要な定数を設定しています。APIキー、PDFファイルのパス、テキストの分割サイズと重複部分、データベースのパスなどが設定されています。
3. OpenAI APIキーの設定
環境変数にOpenAIのAPIキーを設定しています。
4. PDFからテキストを抽出する関数(process_pdf)
与えられたPDFファイルからテキストを抽出するための非同期関数を定義しています。
5. テキストを分割し、埋め込みを作成しデータベースを作成する関数(create_db)
抽出したテキストを一定の長さに分割し、それぞれの部分テキスト(ドキュメント)から埋め込みを作成し、その情報を元にChromaデータベースを作成します。
6. チャットボットの初期化処理(init関数)
ユーザーからPDFファイルをアップロードしてもらい、それを用いてデータベースを作成し、チャットボット(RetrievalQAWithSourcesChain)を初期化します。初期化が完了したら、準備完了のメッセージをユーザーに送信します。
7. 応答を処理する関数(process_response)
最後に、チャットボットからの応答を適切に処理するための関数を定義しています。この関数は、チャットボットからの応答に含まれる質問への回答とその出典を整形して、ユーザーに返信する役割を果たします。
コード解説
以下、このPythonコード(app_pdf.py)の説明です。気になる方は読んでみて下さい。
それぞれ分解して説明します。
このコードブロックは、コード全体を走らせるのに必要なモジュールをインポートしています。
# 必要なモジュールの読み込み import os import shutil from PyPDF2 import PdfReader import chainlit as cl from langchain.embeddings.openai import OpenAIEmbeddings from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain.vectorstores import Chroma from langchain.chains import RetrievalQAWithSourcesChain from langchain.chat_models import ChatOpenAI
以下、各モジュールの詳細について説明します。
os: OSモジュールは、オペレーティングシステムとやり取りするためのポータブルなAPIを提供します。ここでは、環境変数にOpenAIのAPIキーを設定するために使用されます。shutil: 高レベルのファイルやディレクトリ操作のためのモジュールです。ここでは、一時データベースディレクトリの削除に使用されます。PyPDF2: PyPDF2は、PDFファイルの読み書きを行うためのライブラリです。ここでは、アップロードされたPDFからテキストを抽出するために使用されます。chainlit: chainlitは、チャットボットの開発やデプロイに使われるライブラリで、質問応答や対話の制御を行います。langchain.embeddings.openai.OpenAIEmbeddings: OpenAIの言語モデルによる埋め込みを作成するためのクラスです。langchain.text_splitter.RecursiveCharacterTextSplitter: テキストを指定したサイズに分割するためのクラスです。ここでは、PDFから抽出したテキストを一定の長さで分割するために使用されます。langchain.vectorstores.Chroma: Chromaは、ベクトルデータを保存、索引付け、検索するためのデータストアです。ここでは、テキストの埋め込みベクトルを保存し、検索するために使用されます。langchain.chains.RetrievalQAWithSourcesChain: 質問応答チェインの一種で、ユーザーからの質問に対して回答を提供し、その回答の出典を提供することができます。langchain.chat_models.ChatOpenAI: OpenAIのGPT-3やGPT-4といったモデルを使ってチャットボットを構築するためのクラスです。ここでは、質問応答チェインの初期化に使用されます。
このコードブロックは、プログラムで使用するいくつかの定数を設定しています。
# 定数設定 OPENAI_API_KEY = "<OpenAI APIキー>" TEMP_PDF_PATH = "./doc/doc.pdf" CHUNK_SIZE = 500 CHUNK_OVERLAP = 10 DB_PATH = './.chroma' MODEL_NAME = "gpt-4"
OPENAI_API_KEY: OpenAIのAPIを使用するために必要な認証キーです。OpenAIのWebサイトから取得できます。<OpenAI APIキー>には、あなたのOpenAI APIキーを設定してください。TEMP_PDF_PATH: アップロードされたPDFファイルを一時的に保存するパスを示します。ここでは、"./doc/doc.pdf"というパスにファイルが保存されます。CHUNK_SIZE:RecursiveCharacterTextSplitterがテキストを分割する際のチャンク(部分)のサイズを指定します。ここでは、500文字ごとにテキストを分割するように設定されています。CHUNK_OVERLAP: 分割されたテキストチャンク間のオーバーラップの大きさを指定します。この例では、各チャンクは前のチャンクの最後の10文字とオーバーラップします。DB_PATH: Chromaデータベースのパスを指定します。ここでは、'./.chroma'というパスにデータベースが保存されます。MODEL_NAME: 使用するOpenAIのモデル名を設定してください。このコードでは、gpt-4を設定しています。GPT3.5を設定するときは、gpt-3.5-turboとしてください。
このコードブロックは、OpenAI APIキーの設定をしています。
# OpenAI APIキーの設定 os.environ["OPENAI_API_KEY"] = OPENAI_API_KEY
このコードブロックは、PDFファイルからテキストを抽出するための非同期関数を定義しています。
# PDFファイルを開いてテキストを抽出する関数
async def process_pdf(file):
file = file[0] if isinstance(file, list) else file
with open(TEMP_PDF_PATH, 'wb') as f:
f.write(file.content)
reader = PdfReader(TEMP_PDF_PATH)
return ''.join(page.extract_text() for page in reader.pages)
非同期関数は、処理が長時間かかる可能性がある場合や他のタスクと並行して実行する必要がある場合に使用されます。ここでは、非同期関数は、PDFファイルを開き、そのテキストを抽出するために使用されます。
file = file[0] if isinstance(file, list) else file: この行は、入力されたfileがリストの場合、最初の要素を取得します。それ以外の場合は、入力されたfileをそのまま使用します。これは、ファイルが一つしかない場合でもリスト形式で受け取ることがあるため、最初の要素を取得する処理が必要です。with open(TEMP_PDF_PATH, 'wb') as f:: この行は、PDFファイルをバイナリ書き込みモード('wb')で開きます。with文を使用することで、ファイル操作が終わった後に自動的にファイルが閉じられます。f.write(file.content): この行は、PDFファイルの内容を一時ファイルに書き込みます。reader = PdfReader(TEMP_PDF_PATH): この行は、PyPDF2のPdfReaderを使用して、一時ファイルからPDFを読み込みます。return ''.join(page.extract_text() for page in reader.pages): この行は、各ページからテキストを抽出し、そのテキストをすべて連結して返します。
このコードブロックは、テキストを分割し、それぞれの部分に対して埋め込みを作成し、そしてそれらを使ってデータベースを作成する関数を定義しています。
# テキストを分割し、埋め込みを作成してデータベースを作成する関数
async def create_db(text):
text_splitter = RecursiveCharacterTextSplitter(chunk_size=CHUNK_SIZE, chunk_overlap=CHUNK_OVERLAP)
docs = text_splitter.split_text(text)
metadatas = [{"source": f"{i}-pl"} for i in range(len(docs))]
embeddings = OpenAIEmbeddings()
db = Chroma.from_texts(docs, embeddings, metadatas=metadatas)
return db, docs
この非同期関数create_dbは、テキストを分割し、それぞれの部分に対して埋め込みを作成し、そしてそれらを使ってデータベースを作成するというプロセスを実行します。
text_splitter = RecursiveCharacterTextSplitter(): ここで、テキスト分割オブジェクトを作成しています。このオブジェクトは、テキストを一定のサイズ(CHUNK_SIZE)のチャンクに分割するために使用されます。chunk_overlapパラメータは、チャンク間で重複する文字数を指定します。これにより、各チャンクは次のチャンクと少し重なるようになります。docs = text_splitter.split_text(text): この行では、先ほど作成したテキスト分割オブジェクトを使って、入力テキストをチャンクに分割します。その結果として得られるチャンクのリストは、docsに保存されます。metadatas = [{"source": f"{i}-pl"} for i in range(len(docs))]: ここでは、各チャンク(ドキュメント)に対してメタデータを生成しています。メタデータは、各ドキュメントに一意のID(ここではi-plという形式)を割り当てるために使用されます。embeddings = OpenAIEmbeddings(): この行では、OpenAIの埋め込みを生成するオブジェクトを作成しています。db = Chroma.from_texts(docs, embeddings, metadatas=metadatas): この行では、テキスト、埋め込み、およびメタデータを使用してChromaデータベースを作成しています。Chromaデータベースは、テキストの検索と管理に使用されます。return db, docs: 最後に、作成したデータベースと分割されたドキュメントのリストを返します。
このコードブロックは、チャットボットの初期化処理を行う関数initを定義しています。
# チャットボットの初期化処理
@cl.langchain_factory(use_async=True)
async def init():
file = None
while file is None:
file = await cl.AskFileMessage(content="PDFファイルをアップロードしてください!", accept=["pdf"]).send()
# データベースの初期化
shutil.rmtree(DB_PATH, ignore_errors=True)
# ファイルからテキストを抽出し、データベースを作成
text = await process_pdf(file)
db, docs = await create_db(text)
chain = RetrievalQAWithSourcesChain.from_chain_type(
ChatOpenAI(model=MODEL_NAME,temperature=0),
chain_type="stuff",
retriever=db.as_retriever(),
)
# テキストをユーザーセッションに保存
cl.user_session.set("texts", docs)
file_name = file[0].name if isinstance(file, list) else file.name
await cl.Message(content=f"`{file_name}` の準備が完了しました!").send()
return chain
全体的な流れは以下の通りです。
- ユーザーからPDFファイルをアップロードするまで待ちます。アップロードされたファイルは
fileに保存されます。 - データベースの初期化を行います。
shutil.rmtree(DB_PATH, ignore_errors=True)を使って指定されたディレクトリを削除し、既存のデータベースが存在した場合はそれを消去します。 - アップロードされたPDFファイルからテキストを抽出します。この処理は
process_pdf(file)関数で行います。抽出されたテキストはtextに格納されます。 - 抽出したテキストを分割し、それぞれのテキストからベクトル表現(埋め込み)を生成してデータベースを作成します。これは
create_db(text)関数で行われ、作成されたデータベースとテキストのリストがdbとdocsにそれぞれ格納されます。 RetrievalQAWithSourcesChain.from_chain_type()を使用して質疑応答チェーンを作成します。このチェーンは、ユーザーからの質問に対して、作成したデータベースから適切な回答を検索し提供する役割を果たします。- テキストのリスト
docsをユーザーセッションに保存します。これにより、後の処理で使用することができます。 - ユーザーに対してPDFファイルの準備が完了したことを通知します。
- 最後に、作成した質疑応答チェーン
chainを返します。このチェーンは後の処理で使用します。
この関数は非同期関数として定義されており、awaitを使用して非同期処理を行っています。これにより、ファイルのアップロードやテキストの抽出などの時間のかかる処理を効率的に行うことができます。
このコードブロックは、チャットボットが生成した回答を後処理するための関数を定義しています。後処理は通常、回答を整形したり、追加の情報を付加したりするために行われます。
# 応答を処理する関数
@cl.langchain_postprocess
def process_response(res):
texts = cl.user_session.get("texts")
sources = res["sources"].strip().split(',')
source_elements = [cl.Text(content=texts[int(s[:s.find('-pl')])], name=s) for s in sources if s]
response = f"{res['answer']} 出典: {res['sources']}"
cl.Message(content=response, elements=source_elements).send()
関数process_responseの引数resはチャットボットが生成した回答を含む辞書です。
全体的な流れは以下の通りです。
texts = cl.user_session.get("texts"): これはユーザーセッションから以前に保存されたテキストのリストを取得しています。sources = res["sources"].strip().split(','): この行は、回答の出典を示す文字列を取り出し、コンマで分割してリストに変換します。出典は、回答が生成されるための情報がどのテキスト部分から取られたのかを示します。source_elements = [cl.Text(content=texts[int(s[:s.find('-pl')])], name=s) for s in sources if s]: この行は、各出典に対応するテキストを取り出し、それを元にcl.Textオブジェクトのリストを作成します。出典は"-pl"の前で区切られた数値を含み、それはテキストのリストのインデックスに対応しています。response = f"{res['answer']} 出典: {res['sources']}": これはチャットボットの回答と出典を結合した新しい応答メッセージを作成します。cl.Message(content=response, elements=source_elements).send(): この行は新しい応答メッセージと出典に対応するテキストのリストを含むメッセージをユーザーに送信します。
この関数により、チャットボットは質問に対する回答だけでなく、その回答がどの部分のテキストから生成されたのかという情報もユーザーに提供することができます。
アプリを起動し使ってみよう!
今回読み込むPDFファイル
2種類のPDFファイルを使います。
1つは、内閣府の月例経済報告資料です。
内閣府 月例経済報告
https://www5.cao.go.jp/keizai3/getsurei/getsurei-index.html今現在(2023年7月15日現在)の最新の2023年6月版のPDFファイル
https://www5.cao.go.jp/keizai3/getsurei/2023/0622getsurei/main.pdf
このPDFファイル(main.pdf)をダウンロードし、作成したAIアプリに読み込ませ、日本経済などについて聞いてみたいと思います。
もう1つが、私の周辺で何かと話題のPatchTSTという時系列トランスフォーマーの論文です。
Y. Nie, N. H. Nguyen, P. Sinthong, and J. Kalagnanam. A Time Series is Worth 64 Words: Long-term Forecasting with Transformers (2023). International Conference on Learning Representations, 2023.
https://arxiv.org/abs/2211.14730こちらからダウンロード
https://www.salesanalytics.co.jp/PatchTST
このPDFファイル(PatchTST.pdf)をダウンロードし、作成したAIアプリに読み込ませ、論文の内容について聞いてみたいと思います。こちらは、論文が英語なので英語で聞いていきます。
アプリ起動
コマンドプロンプトに、以下のコードを入力し実行します。
chainlit run app_pdf.py
ローカルで実行されるので、URLはhttp://localhost:8000/です。
PDFファイルのアップロードが促されます。ちなみに、アップロードできすPDFは2MBまでです。
内閣府の月例経済報告資料(main.pdf)
先ず、PDFファイルをアップロードします。アップロード後にしばらくすると「準備が完了しました」というメッセージが表示されたらOKです。
色々質問していきます。
先ず概要を聞いて、続いて日本国内の景気について、色々と質問を投げかけてみます。
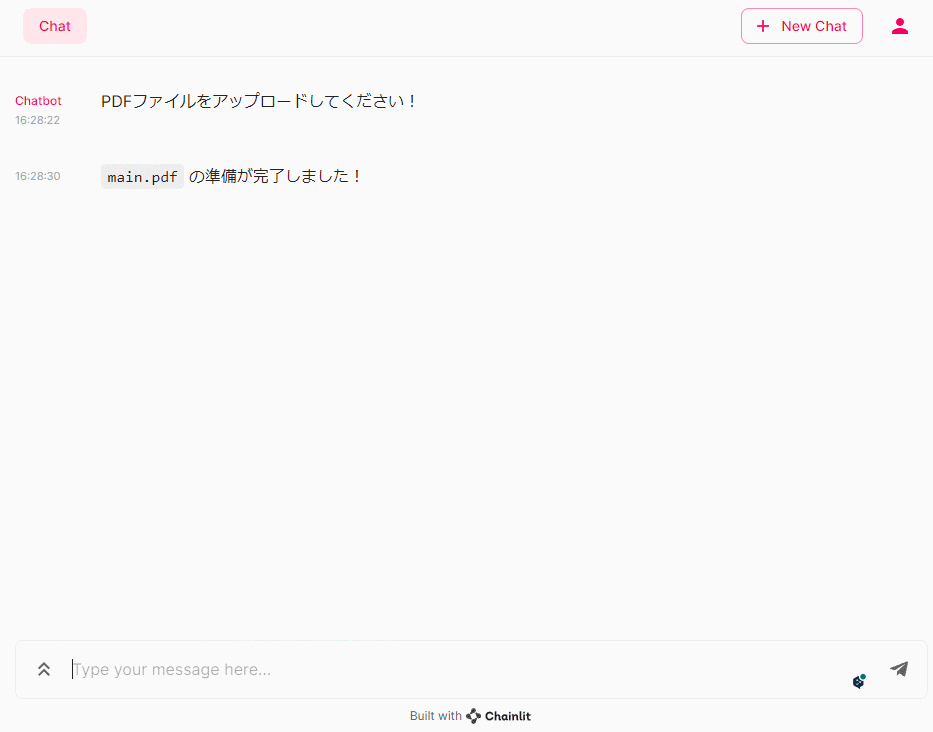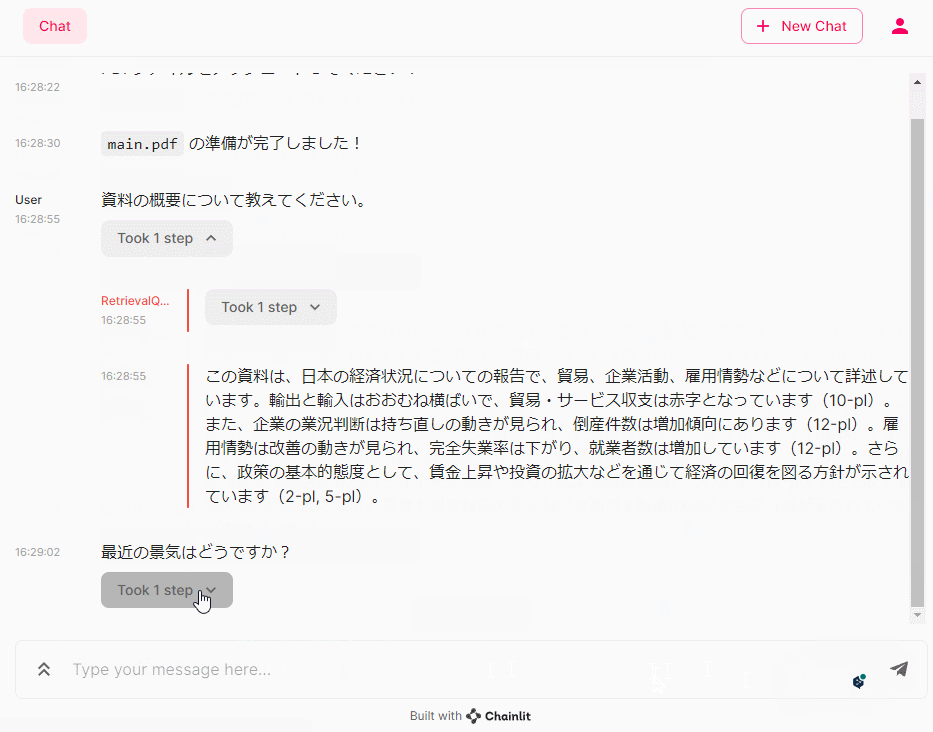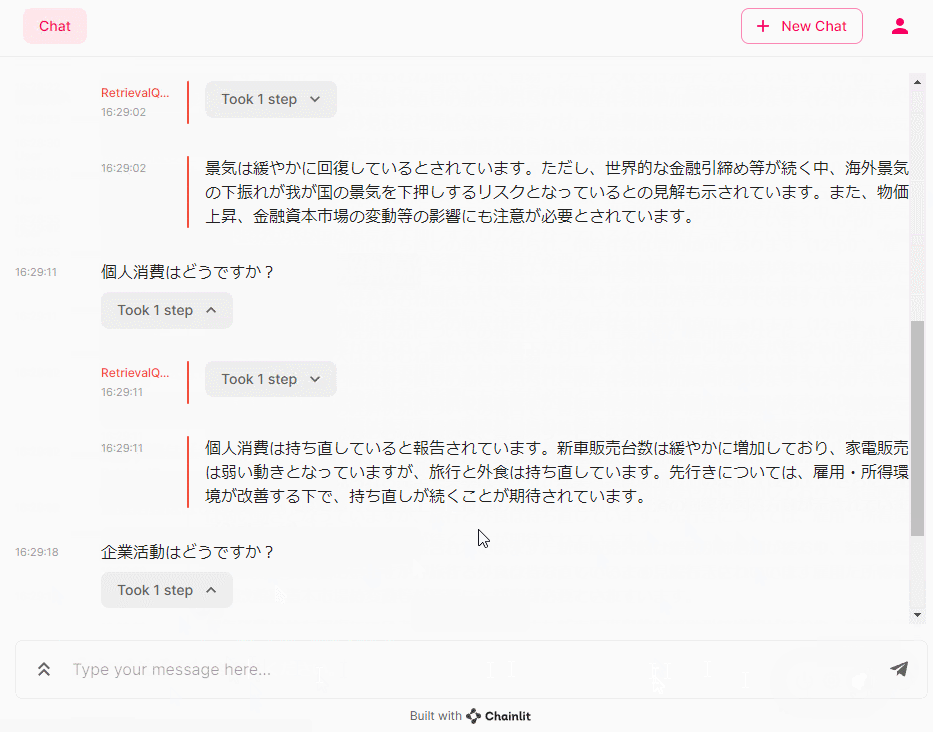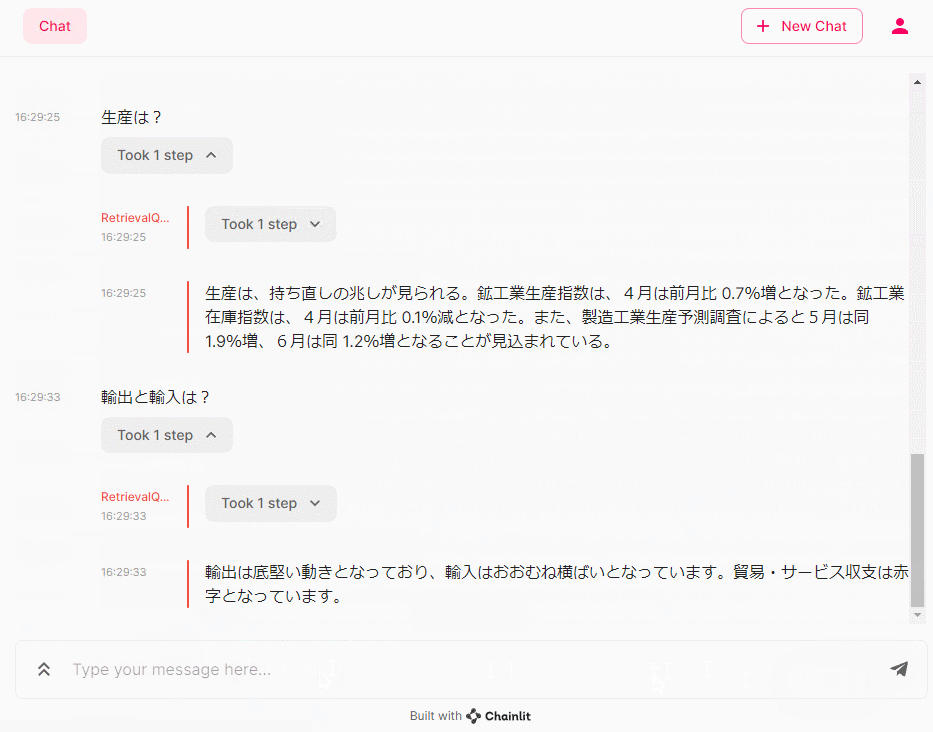
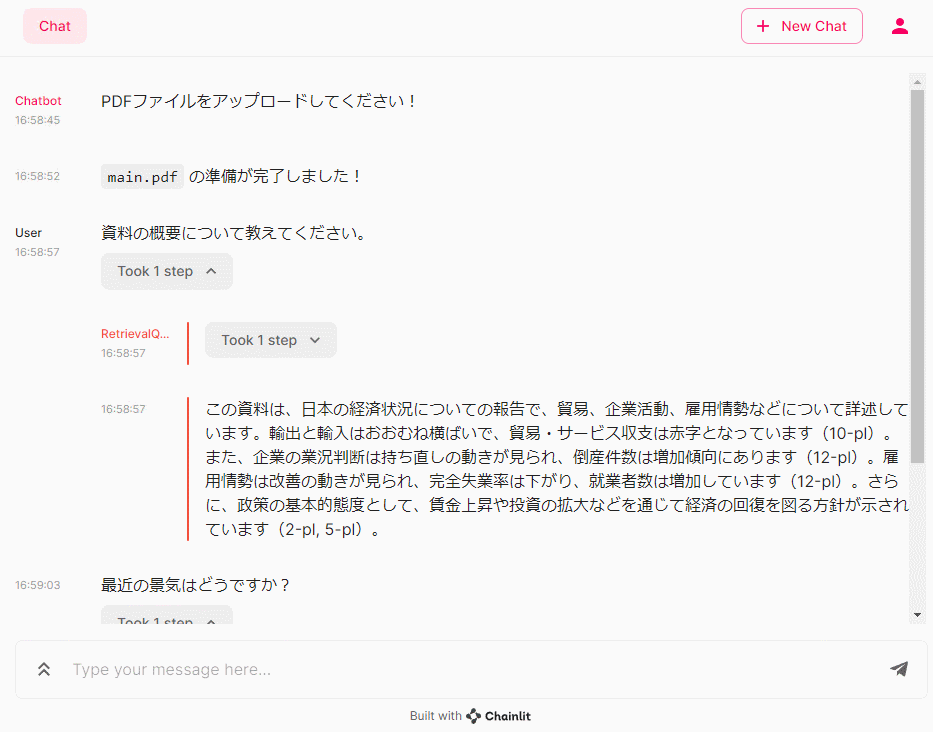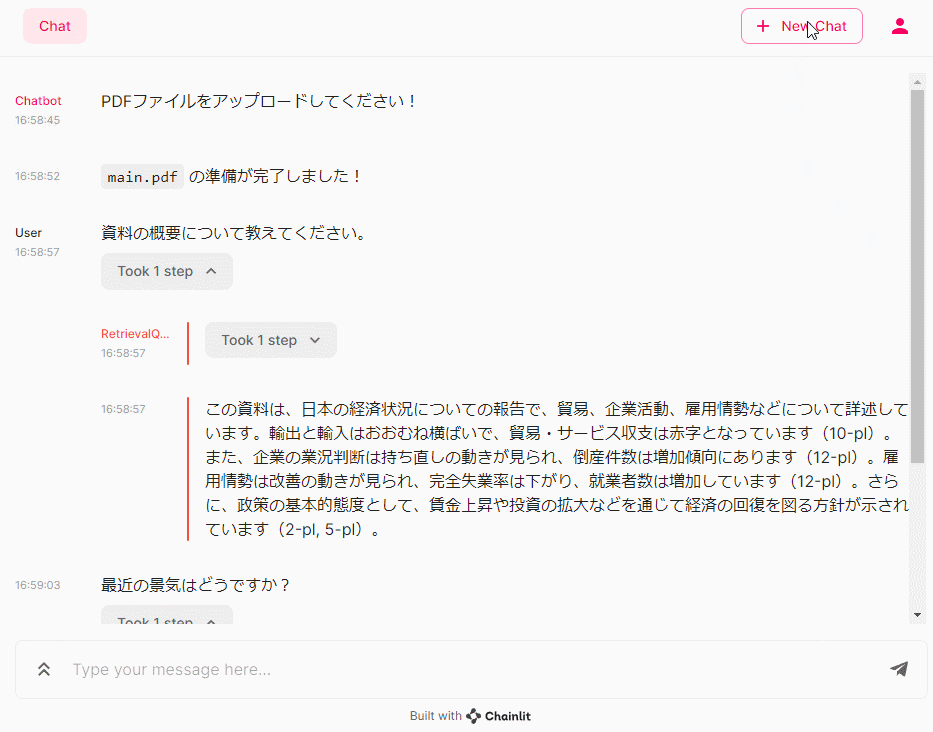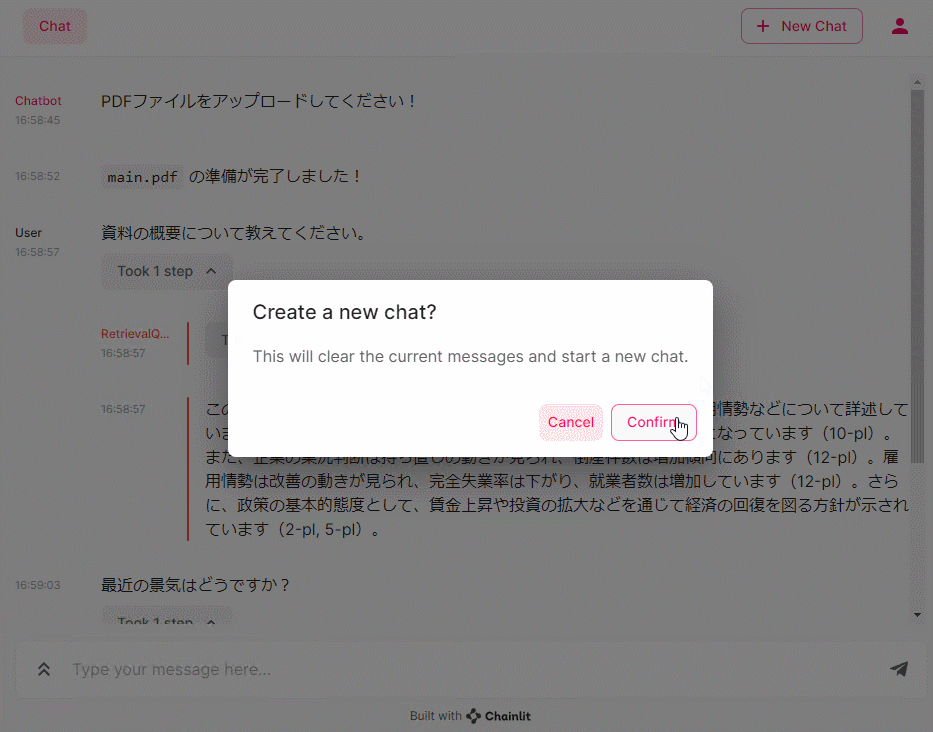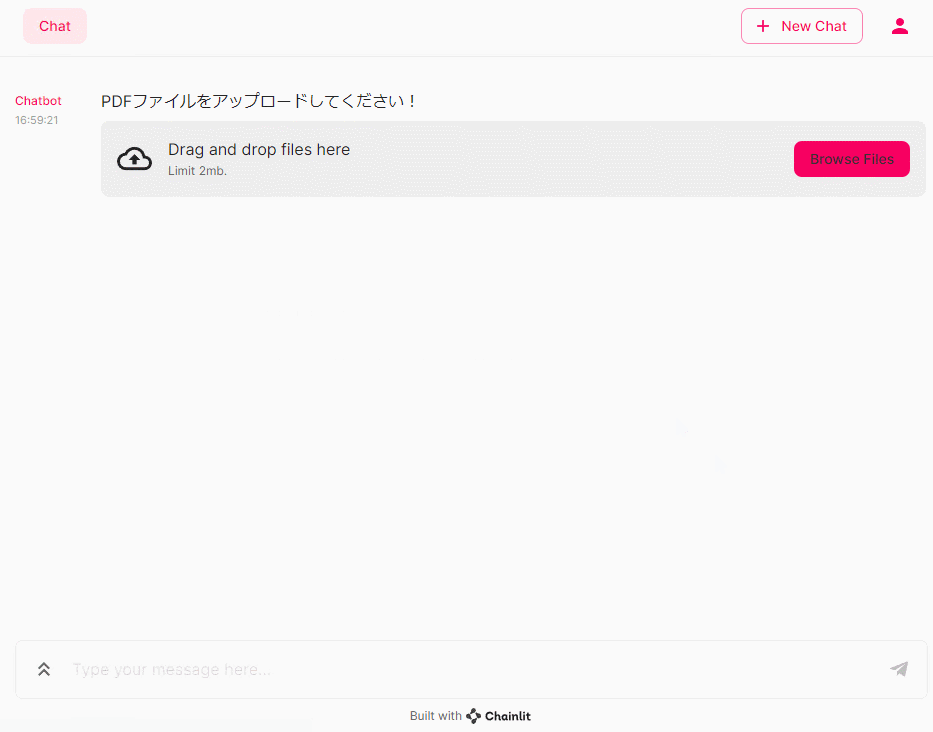
- 資料の概要について教えてください。
- 最近の景気はどうですか?
- 個人消費はどうですか?
- 企業活動はどうですか?
- 生産は?
- 輸出と輸入は?
つづけて、海外の景気について、以下の質問を投げかけてみます。
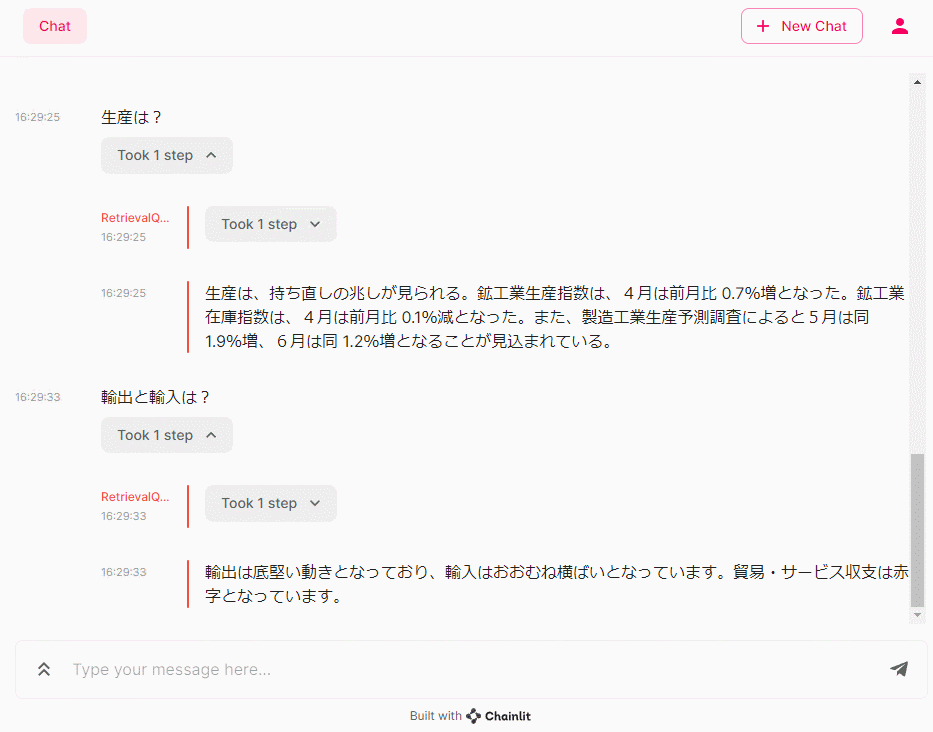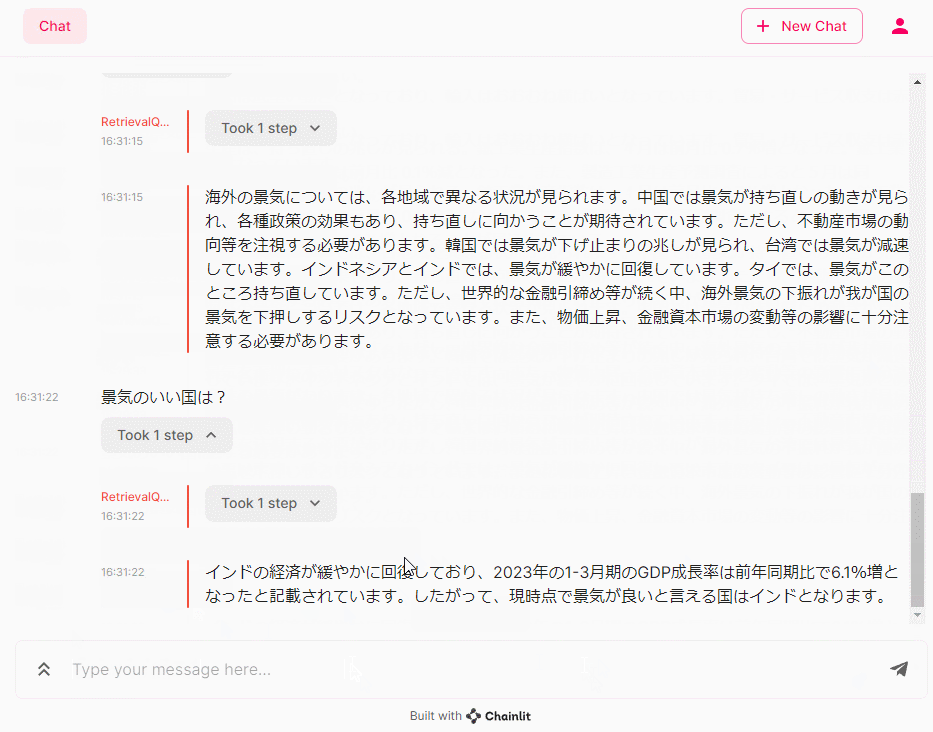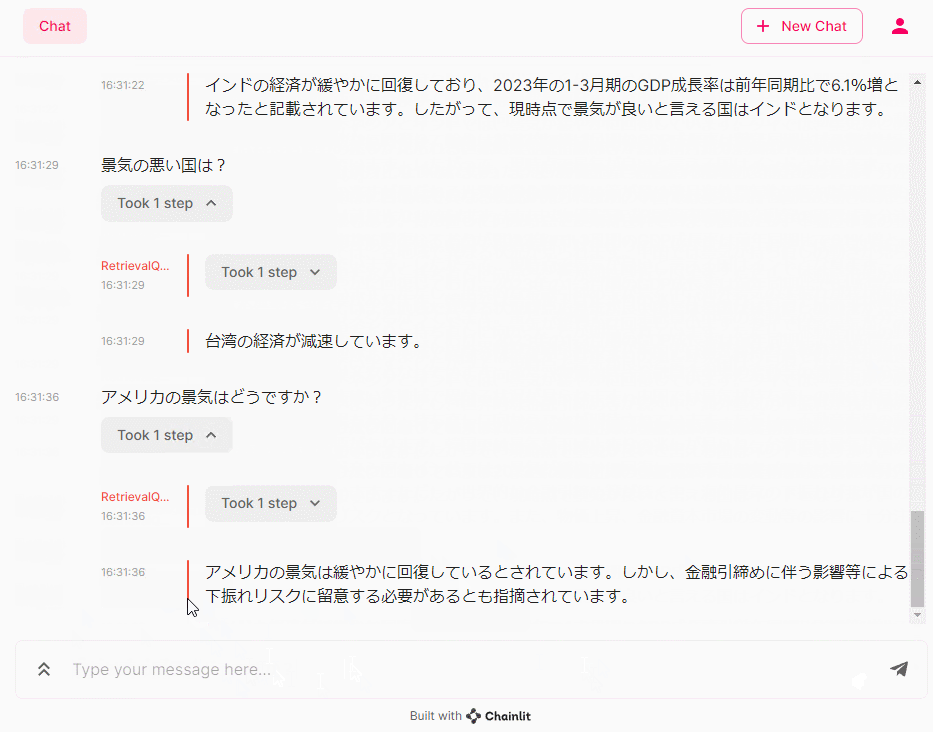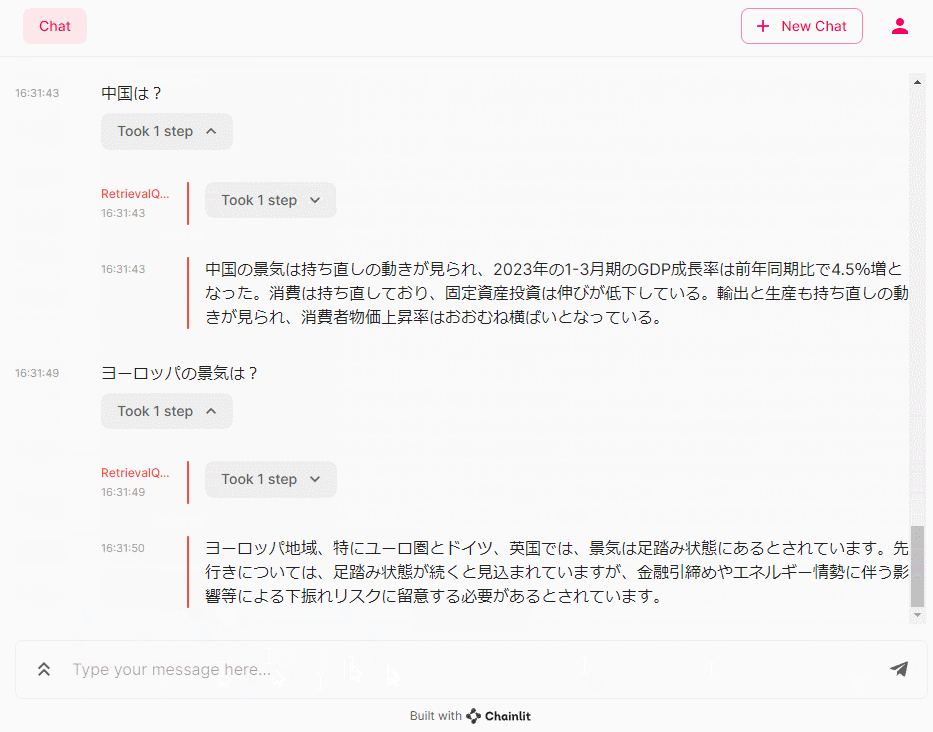
- 海外の景気について教えてください。
- 景気のいい国は?
- 景気の悪い国は?
- アメリカの景気はどうですか?
- 中国は?
- ヨーロッパの景気は?
新しい会話を始めるときは、右上の「New Chat」をクリックします。
PatchTSTの論文(PatchTST.pdf)
先ず、PDFファイルをアップロードします。アップロード後にしばらくすると「準備が完了しました」というメッセージが表示されたらOKです。
色々質問していきます。
先ず概要を聞いて、続いて論文の内容について、色々と質問を投げかけてみます。
- Please summarize the content of this paper. (この論文の内容を要約してください。)
- What are the major differences from other TSTs? (他のTSTとの大きな違いは何ですか?)
- Why have you been able to significantly improve the accuracy of your long-term forecasts? (なぜ長期予測の精度を大幅に向上させることができたのですか?)
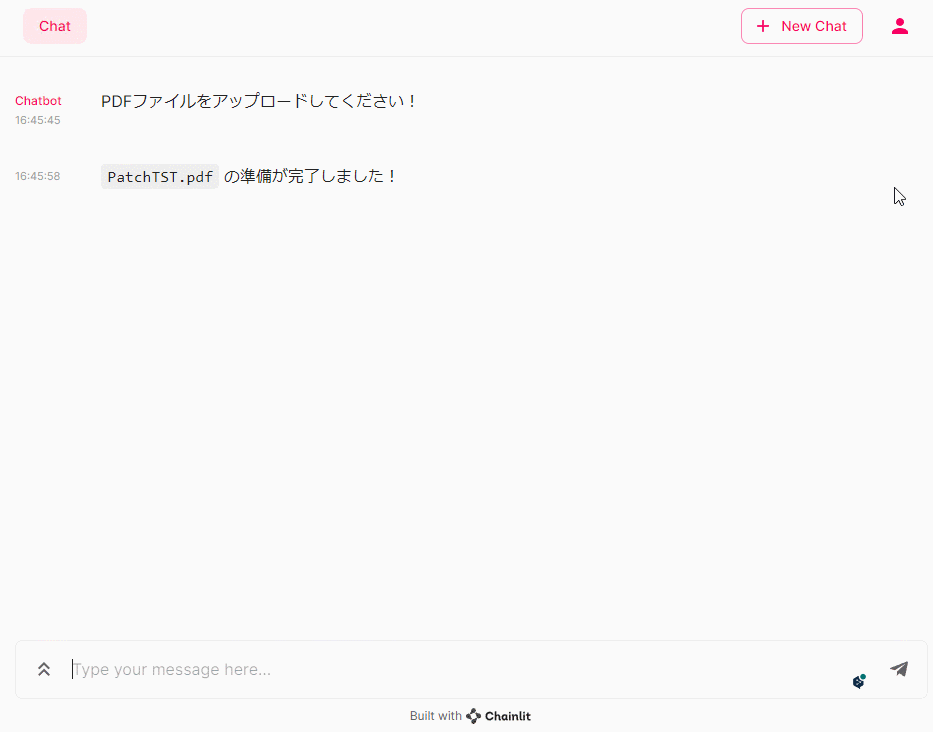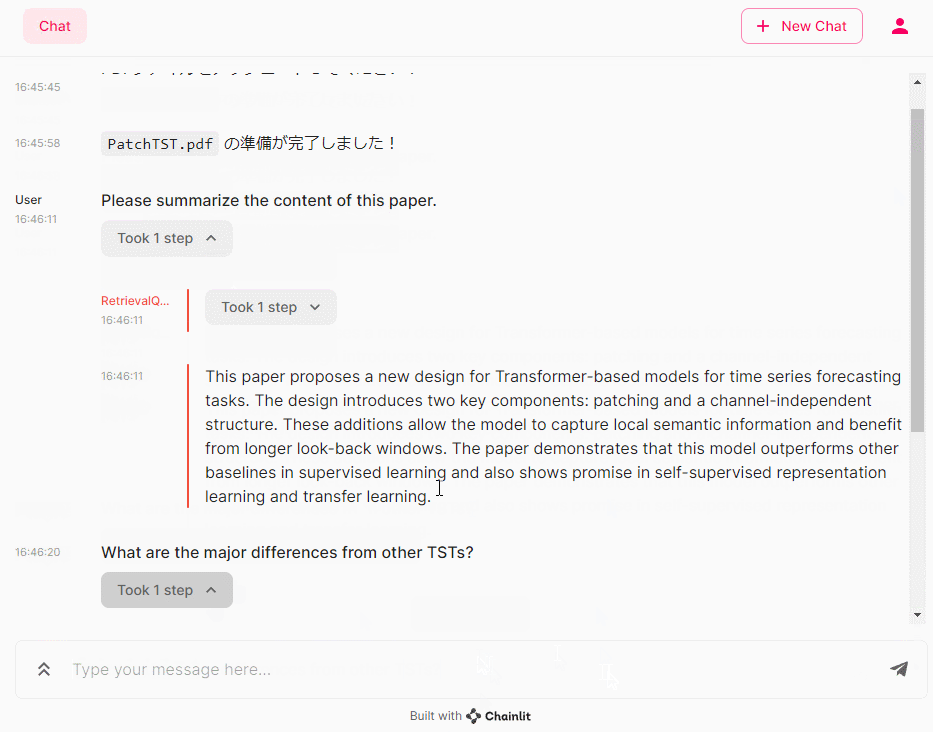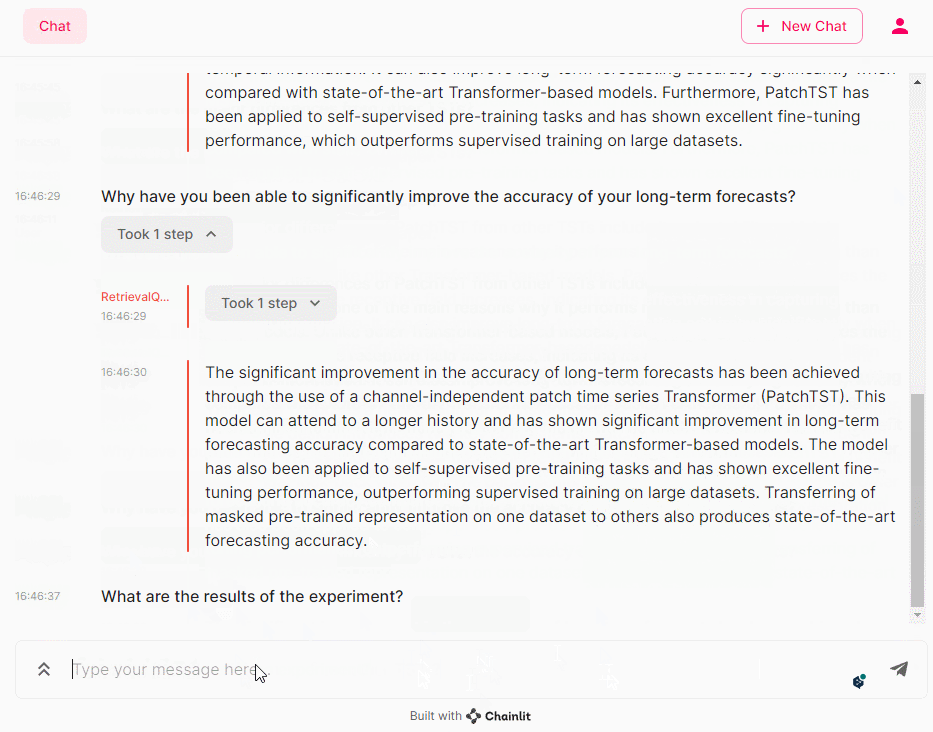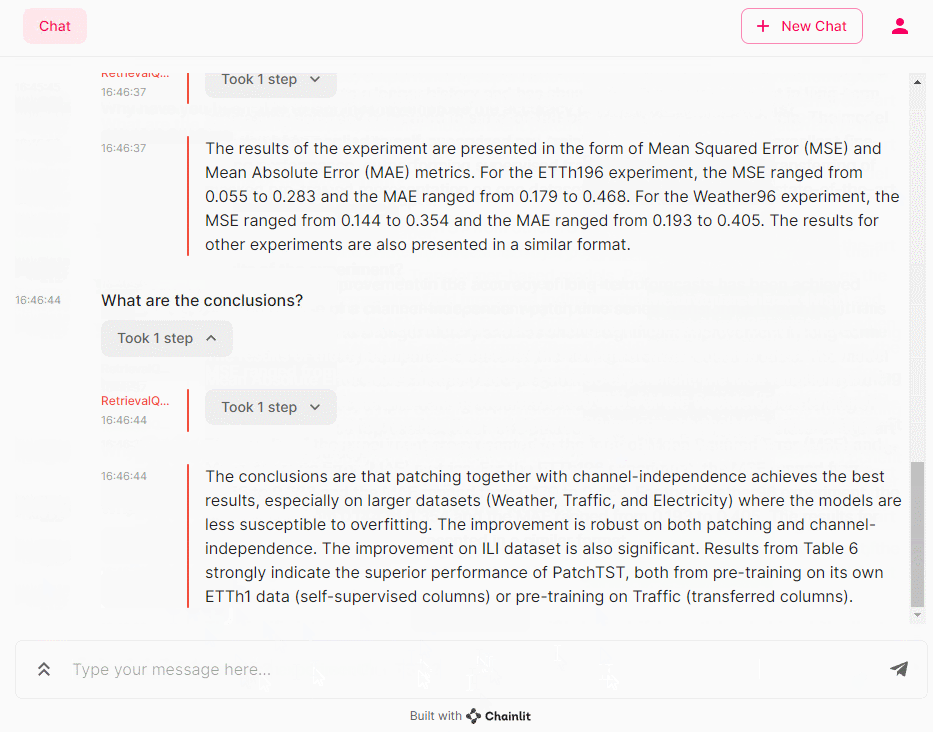
- What are the results of the experiment? (実験結果は?)
- What are the conclusions? (結論は?)
つづけて、PatchTSTのキーとなるpatching(パッチング)とchannel independence(チャンネル独立性)について、もう少し聞いてみます。
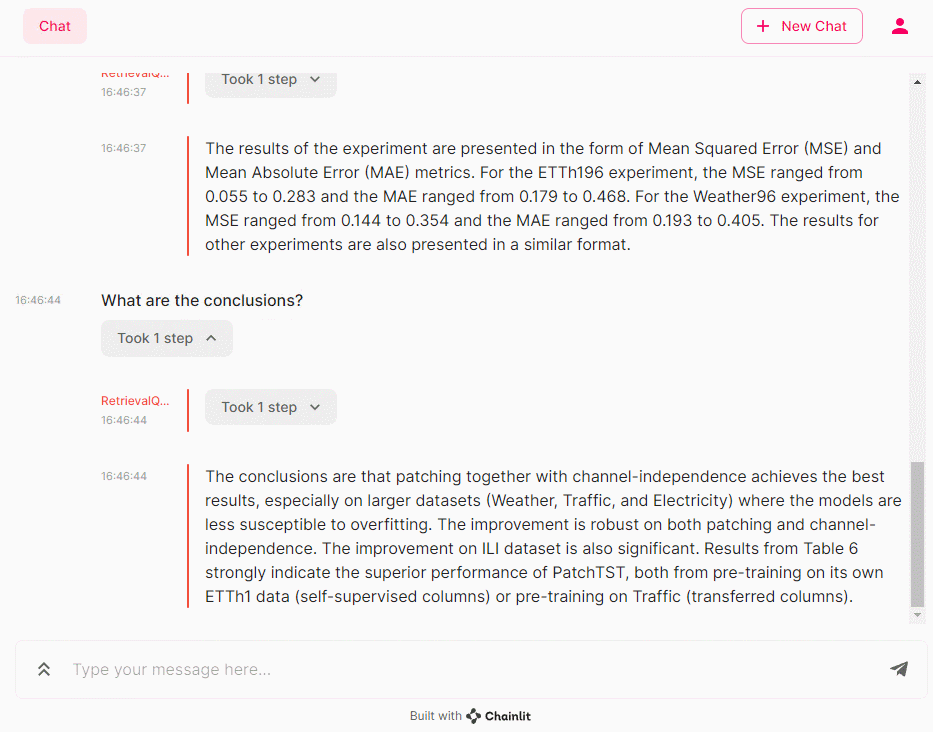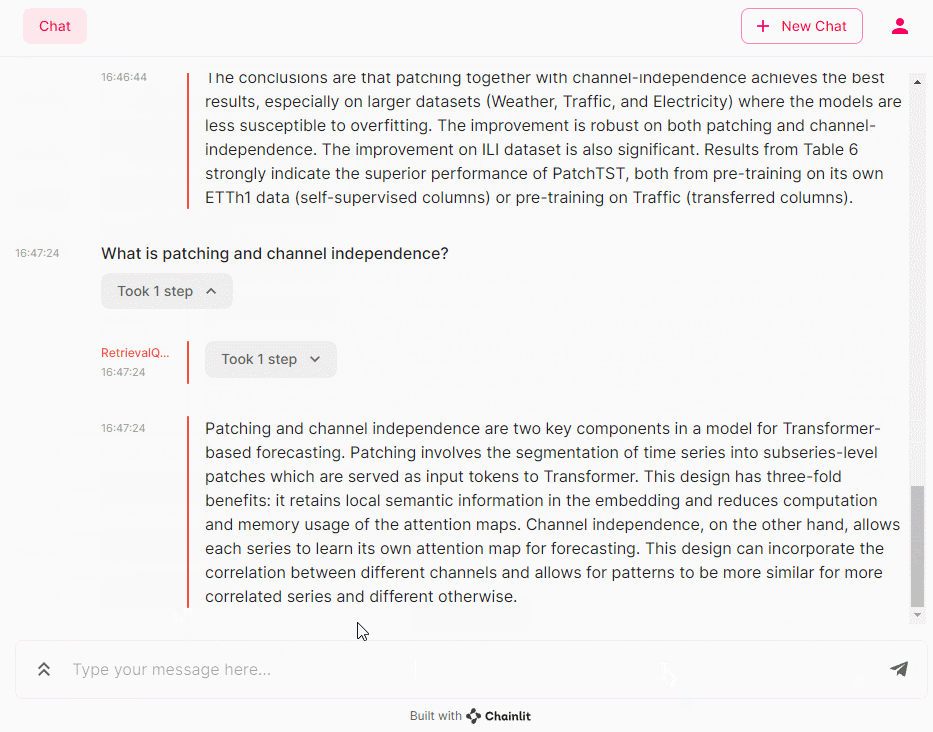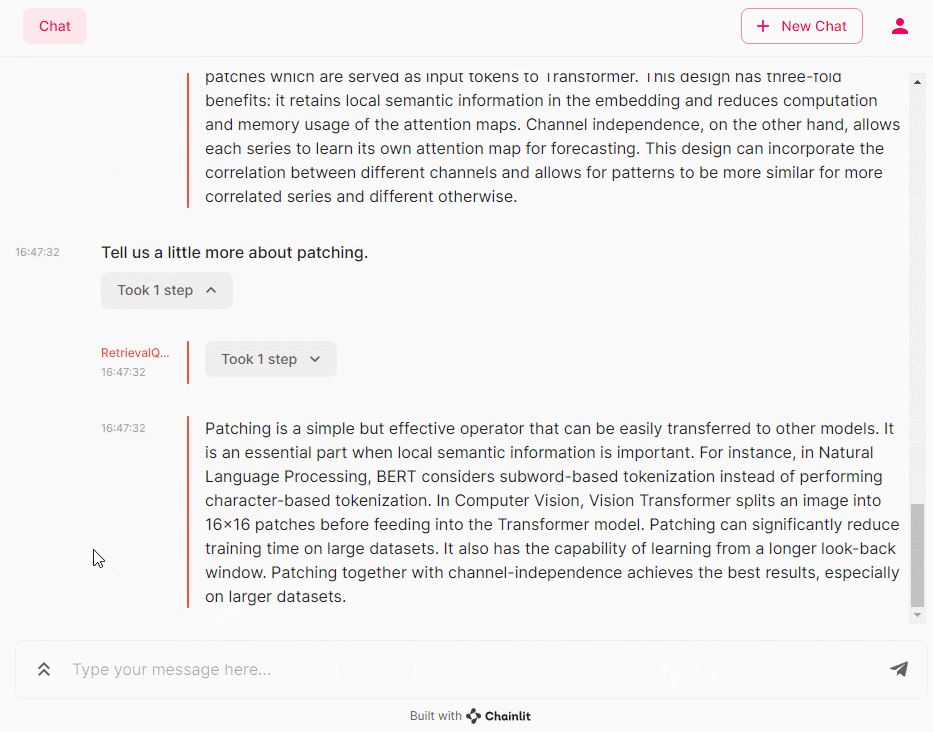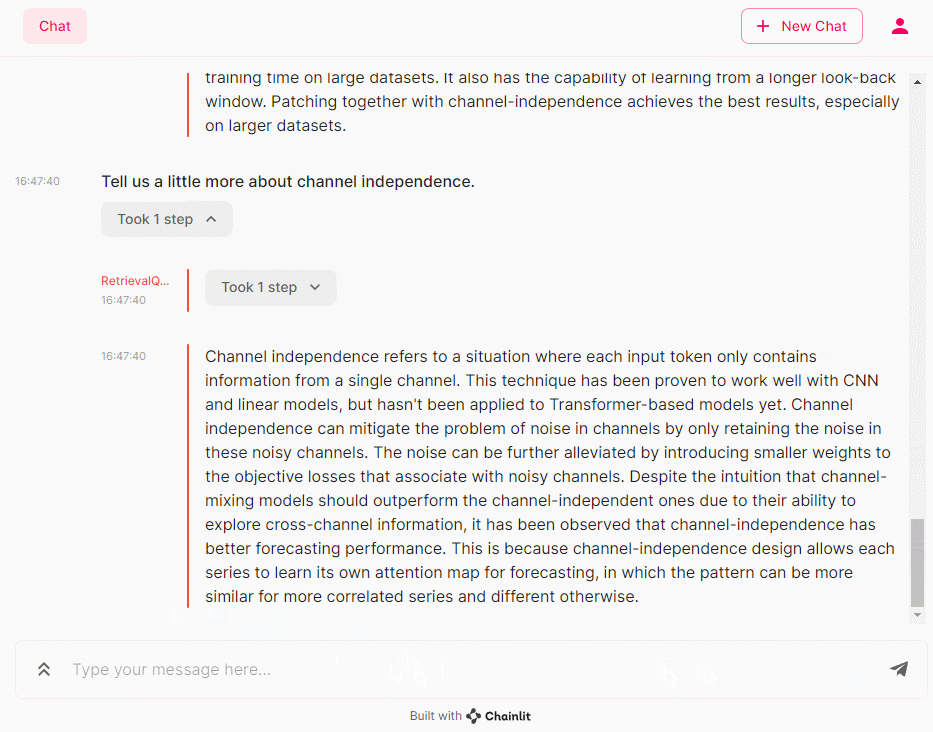
- What is patching and channel independence? (パッチングとチャンネル独立性とは何ですか?)
- Tell us a little more about patching. (パッチングについてもう少し詳しく教えてください。)
- Tell us a little more about channel independence. (チャンネル独立性についてもう少し教えてください。)
まとめ
今回は、簡単なPDFドキュメントチャットボットの作り方について説明しました。
冒頭で、新しい情報を与えて回答して欲しいとき、すぐできるやり方として、例えば2つの方法を示しました。
- ドキュメントを与えて回答してもらう
- インターネット上の情報を検索し回答してもらう
今回は「ドキュメントを与えて回答してもらう」という方法の実装例を示しましたので、次回は「インターネット上の情報を検索し回答してもらう」という方法の実装例を示します(時間的余裕があるときにですが……)。