
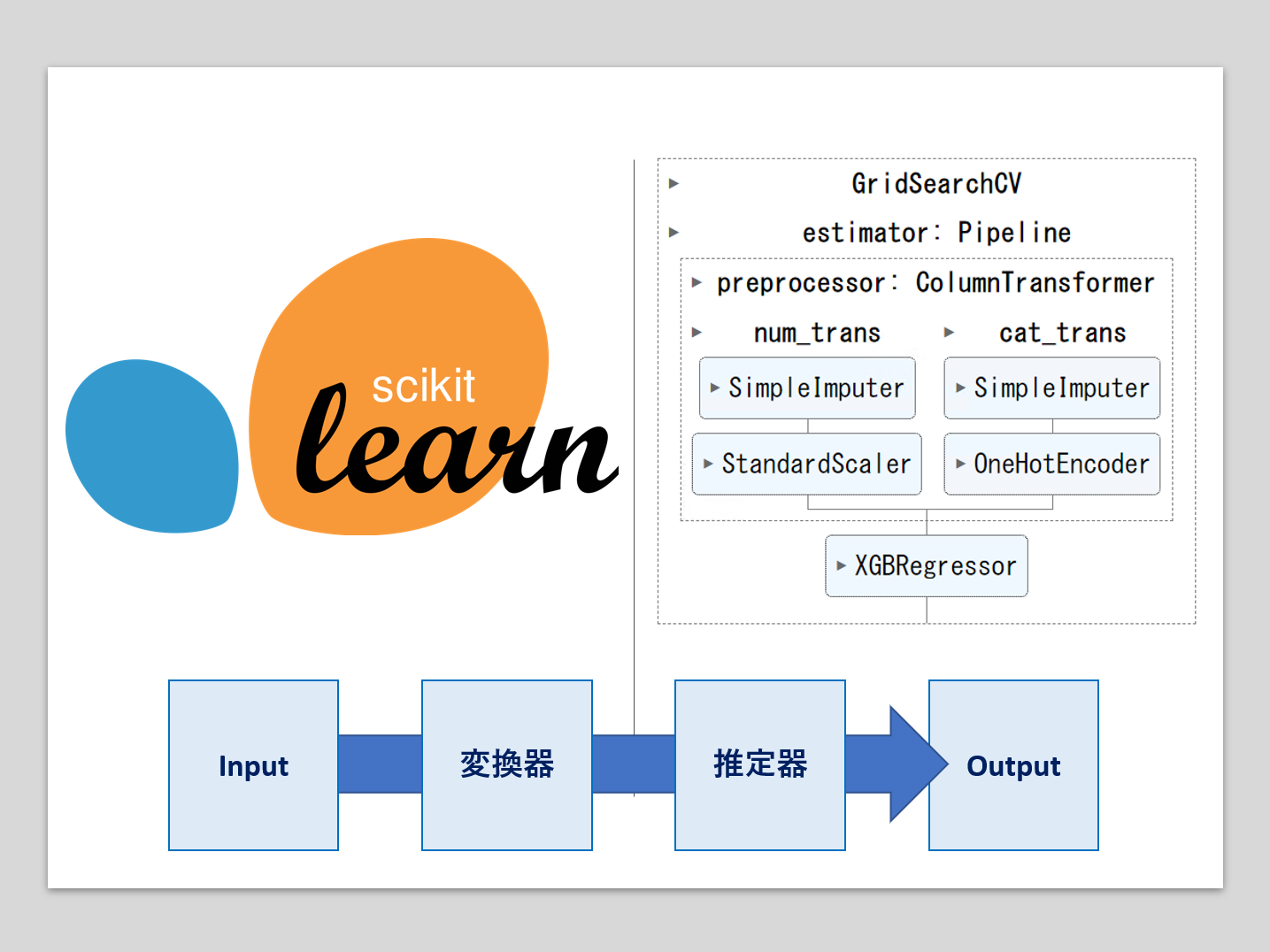
機械学習のパイプラインとは、複数の処理を直列に連結したものです。
最小構成は、1つの変換器と1つの推定器(予測器)を連結したものです。

- 変換器:特徴量X(説明変数)などの欠測値処理や変数変換などの、特徴量変換(Transformor)
- 推定器:線形回帰モデルやXGBoostなどの数理モデルを使い、目的変数yの予測を実施(Estimator)
多くの場合、Inputは特徴量(説明変数)Xで、Outputは目的変数yの予測値です。
全ての変数に対し同じ変換を施すこともあるでしょうが、いつも全ての変数に対し同じ変換を施すわけでもありません。
前回は、変数ごとにパイプラインの変換器の処理を変える方法について説明しました。
ただし、どの変換器を使うのかは、人が決めていました。
今回は、もう一歩話を進め、変数ごとに利用する変換器を自動選択する方法についてお話しします。
変換器を自動選択するとき、決定係数
ちなみに、利用するデータセットは前回と同じです。
Contents [hide]
利用するデータセット
利用するデータは、DAT8コース(2015年にワシントンDCで開催されたデータサイエンスコース)のBike Sharing Demand(CSVファイル)です。
簡単に変数について説明します。
以下、データ項目です。
- datetime – 日時
- season
- 1 = 春
- 2 = 夏
- 3 = 秋
- 4 = 冬
- holiday – その日が休日であるかどうか
- workingday – その日が週末でも休日でもない日かどうか
- weather
- 1:晴れ、雲少ない、部分的に曇り、部分的に曇り
- 2: 霧+曇り、霧+切れ落ちた雲、霧+少ない雲、霧
- 3:小雪、小雨+雷雨+雲が散らばる、小雨+雲が散らばる
- 4:大雨+氷柱+雷雨+霧、雪+霧
- temp – 気温(摂氏)。
- atemp – 体感温度
- humidity – 相対湿度
- windspeed – 風の速さ
- casual – 非登録ユーザーによるレンタル開始数
- registered – 登録ユーザーによるレンタル開始数
- count – 総レンタル数
最後の方にある「casual」「registered」「count」が目的変数で、他が特徴量(説明変数)です。
今回は、「casual」を目的変数に設定しています。
特徴量(説明変数)には、量的変数と質的変数があります。
- 量的変数:temp、atemp、humidity、windspeed
- 質的変数:season、holiday、workingday、weather
量的変数に対し、以下の欠測値補完処理を実施し、その後に変数変換を実施します。
- 平均値で欠測値補完:SimpleImputer(strategy=’mean’)
- 正規化:StandardScaler()
質的変数に対し、以下の欠測値補完処理を実施し、その後に変数変換を実施します。
- 最頻値で欠測値補完:SimpleImputer(strategy=”most_frequent”)
- ダミーコード化:OneHotEncoder
要するに、量的変数と質的変数に対し、別の前処理を施します。
その前処理後のデータを用い、目的変数(casual – 非登録ユーザーによるレンタル開始数)を予測します。推定器にはXGBoostを用います。
Optunaの概要
人為的に設定するハイパーパラメータ
Optunaとは、機械学習モデルのパラメータの1つであるハイパーパラメータをチューニング(調整)するためのライブラリーです。
- ハイパーパラメータ:モデルの学習を開始する前に設定する必要があるパラメータ
- モデルパラメータ:モデルの学習過程で自動的に学習・調整されるパラメータ
機械学習モデルは、過去のデータセットを使いモデルパラメータの値を求めます。そのことを学習と言います。
では、ハイパーパラメータの値はどうするのか?
ハイパーパラメータの値は、機械学習モデルのモデルパラメータの値を与える前に、人が人為的に与えます。
ハイパーパラメータ設定はセンスと試行錯誤
ハイパーパラメータの値をどのように設定するのかは、その人のセンスと試行錯誤の賜物です。
そこに、職人的な要素(経験値や細部へのこだわりなど)やアート的な要素(生まれ持った感性と直感など)が求められます。
機械学習モデルの構築は、壺を作ったり絵を描いたりするのに似ています。私は以前、水墨画を描いていた時期があるのですが、機械学習モデルを構築するとき、何となく似ていると感じていました。
ハイパーパラメータ探索の自動化
ハイパーパラメータの値をどのように設定するのかを考えたとき、人のセンスに依存する部分はどうしようもありませんが、試行錯誤に関しては機械的にどうにかなりそうです。
多くの場合……
- ハイパーパラメータの値を設定し、機械学習モデルを作り(モデルパラメータの学習)をし、精度指標などを見ながら良し悪しを考え……
- ダメだと思えば、再度ハイパーパラメータの値を設定し、機械学習モデルを作り(モデルパラメータの学習)をし、精度指標などを見ながら良し悪しを考え……
……ということを、納得がいくまで繰り返します。
この操作を自動化するのが、ハイパーパラメータチューニング用のライブラリーで、その中の1つがOptunaです。
探索方略
ハイパーパラメータのチューニング方法には、幾つかやり方があります。
Optunaは、ベイズ最適化でハイパーパラメータチューニングを実施します。
他にも、グリッドサーチ(総当たり法)やランダムサーチ(ランダムに探る)など、色々な方法があります。
パイプラインを最適化する
Optunaなどのハイパーパラメータチューニングライブラリーは、機械学習モデルであるXGBoostなどの推定器のハイパーパラメータだけを調整するわけではありません。
構築する機械学習モデルをパイプライン全体に広げ考え、パイプラインの中で人が人為的に与える設定すべてをハイパーパーラメータと考えます。
そうすると、パイプラインの中で利用する変数ごとの変換器を人為的に決めていた場合、当然ながらどの変換器を与えるのかどうか(=ハイパーパーラメータの値の設定)になります。
Optunaについてもって知りたいという方は、以下で記事をまとめていますので、参考にして頂ければと思います。
変換器の自動選択
今回は2種類のハイパーパラメータが存在します。
- 利用する変換器
- 推定器であるXGBoostそのものハイパーパラメータ
そのため、2種類のパイプラインハイパーパラメータチューニングのパターンを紹介します。
- 変換器の選択を自動チューニングのみのパターン
- XGBoostのハイパーパラメータ調整付きのパターン
いきなり、推定器であるXGBoostのハイパーパラメータチューニングも含めると、分かり難くなると思いましたので、最初は変換器の選択を自動チューニングのみのパターンからお話しします。
共通の設定
先ず、必要なモジュールを読み込みます。
# # モジュールの読み込み # import optuna # 基本的なモジュール import numpy as np import pandas as pd # データ分割用の関数 from sklearn.model_selection import train_test_split # 評価指標 from sklearn.metrics import r2_score # パイプライン構築のための道具 from sklearn.pipeline import make_pipeline from sklearn.pipeline import Pipeline from sklearn.compose import ColumnTransformer from sklearn.preprocessing import FunctionTransformer # 今回、変換器として利用 from sklearn.preprocessing import StandardScaler from sklearn.preprocessing import OneHotEncoder from sklearn.preprocessing import MinMaxScaler from sklearn.impute import SimpleImputer # 今回、推定器として利用 import xgboost as xgb # グラフ作成 import matplotlib.pyplot as plt
簡単に説明します。
optuna: 強力なハイパーパラメータ最適化フレームワーク。numpy: Pythonプログラミング言語用のライブラリで、大規模な多次元配列と行列をサポートし、これらの配列を操作する高水準数学関数の大規模なコレクションを追加する。pandas: データ操作と解析のためのソフトウェア・ライブラリ。特に、数値表や時系列を操作するための操作を提供する。train_test_split: データセットをtrain(学習データ)とtest(テストデータ)の2つに分割するSklearn関数。r2_score: R2(決定係数)回帰スコアを計算する Sklearn 関数。make_pipeline、Pipeline: Sklearnの関数で、異なるパラメータを設定しながら、一緒にクロスバリデーションを行うことができるいくつかのステップを組み立てるために使用されます。ColumnTransformer: この推定器は、入力の異なる列または列のサブセットを別々に変換し、各変換器によって生成された特徴を連結して1つの特徴空間を形成することができる。FunctionTransformer: 任意の callable から変換器を構築します。StandardScaler、MinMaxScaler、OneHotEncoder、SimpleImputer: スケーリング、エンコード、エンコーディングのための様々な Sklearn 前処理モジュール。
次に、今回利用するデータセットを読み込みます。
以下、コードです。
#
# データセットの読み込み
#
url = 'https://raw.githubusercontent.com/justmarkham/DAT8/master/data/bikeshare.csv'
df = pd.read_csv(url, index_col='datetime', parse_dates=True)
X = df.drop(['casual','registered','count'],axis=1)
y = df['casual']
# 学習データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size=0.3,
random_state=123
)
このコードは、bikeshareという名のデータセットをインターネットからダウンロードし、データ分析や機械学習の準備を行っています。
url = 'https://raw.githubusercontent.com/justmarkham/DAT8/master/data/bikeshare.csv'
bikeshareという名前のデータセットへのURLリンクを設定します。
df = pd.read_csv(url, index_col='datetime', parse_dates=True)
pandasの`read_csv`関数を使用してデータをダウンロードし、データフレームにする操作を行います。`index_col=’datetime’`はdatetime列をインデックスとして設定します。`parse_dates=True`は日付文字列をPythonのdatetimeオブジェクトに変換するオプションです。
X = df.drop(['casual','registered','count'],axis=1)
bikeshareデータセットから特徴量を抽出する操作を行います。’casual’, ‘registered’, ‘count’という3つの列を削除し、残りの列を特徴量とします。
y = df['casual']
‘casual’という名前の列を目的変数として指定します。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=123)
ここでは、データサンプルを学習用とテスト用データセットに分割します。分割はランダムに行われ、テストデータセットのサイズは全体の30% (test_size=0.3)とされます。また、random_stateは乱数ジェネレータのシードを指定し、これにより分割結果が再現可能になります。
データの前処理やハイパーパラメータ調整など、機械学習の作業を簡便化するために、今回もいくつかのリストをあらかじめ作成します。
以下、コードです。
#
# リスト
#
# 変数のタイプに関するリスト
nums = ['temp','atemp','humidity','windspeed'] #量的変数
cats = ['season','holiday','workingday','weather'] #質的変数
# 欠測値の補完に関するリスト
imputers = {
'nums': SimpleImputer(),
'cats': SimpleImputer(strategy='most_frequent'),
}
# 変数変換に関するリスト
transformers = {
'none': FunctionTransformer(lambda x: x),
'log': make_pipeline(
MinMaxScaler(),
FunctionTransformer(np.log1p)
),
'exp': make_pipeline(
MinMaxScaler(),
FunctionTransformer(np.exp)
),
'onehot': OneHotEncoder(handle_unknown='ignore'),
}
# 推定器のハイパーパラメータに関するリスト
xgb_param_names = [
"learning_rate",
"n_estimators",
"max_depth",
"subsample",
"colsample_bytree",
]
簡単に説明します。
- 変数のタイプに関するリスト: 変数を量的変数(数値変数)と質的変数(カテゴリ変数)に分けています。量的変数は`[‘temp’, ‘atemp’, ‘humidity’, ‘windspeed’]`の4つ、質的変数は`[‘season’, ‘holiday’, ‘workingday’, ‘weather’]`の4つと定義しています。
- 欠測値の補完に関するリスト: 変数タイプに応じて、欠測値を補完するための`imputers`が定義されています。欠測値は`SimpleImputer`を使用して補完します。量的変数には平均値を、質的変数には最頻値を使用します。
- 変数変換に関するリスト: 変数の変換に使用する`transformers`が定義されています。ここでは’done’, ‘log’, ‘exp’, ‘onehot’の4つの変換器が定義されており、それぞれ何もしない、対数変換(且つ最小最大スケーリング)、指数変換(且つ最小最大スケーリング)、ワンホットエンコーディングの変換をします。
- 推定器のハイパーパラメータに関するリスト: XGBoostのハイパーパラメータ調整に使用するパラメータを`xgb_param_names`としてリスト化しています。このリストに含まれるパラメータは、”学習率(learning_rate)”, “決定木の数(n_estimators)”, “決定木の深さ(max_depth)”, “サブサンプリングの割合(subsample)”, “列採用の割合(colsample_bytree)”といった重要なハイパーパラメータを示しています。
共通の設定の最後に、変数が量的変数なのか質的変数なのかを判別する簡単な関数をあらかじめ作っておきます。
以下、コードです。
# 変数のタイプを返す関数
def get_vartype(col):
if col in cats:
return 'cats' # 質的変数
else:
return 'nums' # 量的変数
この関数 `get_vartype(col)` は、入力された列 `col` のタイプ(質的変数か量的変数か)を判断します。
- 引数 `
col` がリスト `cats` の中にあれば、`cats`を返します。ここで `cats` は質的変数の変数名が格納されたリストです。 - もし `
col` が `cats` に存在しなければ、つまり量的変数であれば、`nums` を返します。
したがって、この関数は特定の列(変数)が質的変数か量的変数かを知りたいときに使用します。
変換器の選択を自動チューニングのみのパターン
先ず、変換器を自動選択するための、Optunaの目的関数を作ります。
以下、コードです。
# Optunaの目的関数
def objective(trial):
column_trans = []
for colname in X_train.columns:
vartype = get_vartype(colname)
if vartype == 'nums':
vartrans = trial.suggest_categorical(
f"vartrans_{colname}",
['none', 'log', 'exp']
)
else:
vartrans = 'onehot'
column_trans.append((
colname,
make_pipeline(
imputers[vartype],
transformers[vartrans]),
[colname]
))
ct = ColumnTransformer(
column_trans,
remainder='drop'
)
pipe = Pipeline([
("preprocessor", ct),
("regressor", xgb.XGBRegressor())
])
pipe.fit(X_train, y_train) # 学習
pred = pipe.predict(X_test) # 予測
return r2_score(y_test, pred) # 戻り値はR2スコア
このコードで定義されている`objective`関数を使い、Optunaは最適化を行います。`objective`関数を使い色々なハイパーパラメータでモデルを学習し、テストデータによるモデルの性能をR2スコア(決定係数)で評価します。
今回は、限られた試行回数の中で、テストデータのR2スコアが最大化するハイパーパラメータを見つけるために利用します。
`objective`関数のコードの流れを簡単に説明します。
- 関数内で、`X_train`のすべての変数をループします。これは、各変数(列)に最適な変換を見つけるためです。
- 各列のタイプをチェックします。この例では、列は2種類のタイプ(’nums’またはその他)に分類されます。’nums’は量的変数であることを表します。
- 列のタイプに基づいて、可能な変換のリスト([‘none’, ‘log’, ‘exp’]または’onehot’)から最適な変換を見つけます。このステップでOptunaの`trial.suggest_categorical`メソッドが使用され、パラメータ空間の範囲を定義します。
- 決定された変換を、欠損値の処理(`imputers`)と変換処理用のパイプライン(`transformers`)に追加します。
- すべての列の変換が決定されたら、`ColumnTransformer`を作成します。このステップでは、適用する変換を各列に指定します。`remainder=’drop’`パラメータにより、変換が指定されていない列は削除されます。
- `ColumnTransformer`を前処理ステップとして組み込んだパイプラインを作成します。最終ステップはXGBoostの回帰モデルです。
- パイプラインを学習データ`X_train`と`y_train`で訓練(フィッティング)し、テストデータ`X_test`で予測を行います。
- 最後に、予測と実際の値`y_test`を比較します。評価指標としてR2スコアを計算し、これがOptunaによって最大化されます。
では、Optunaの`objective`関数を使いハイパーパラメータチューニングを実施します。
以下、コードです。
study = optuna.create_study(direction='maximize') study.optimize(objective, n_trials=1000) trial = study.best_trial
このコードは目的関数に対する最適なハイパーパラメータのセットを見つけるためのプロセスを実行します。
study = optuna.create_study(direction='maximize')
OptunaのStudyオブジェクトを生成します。Studyは、特定の目標関数に対してハイパーパラメータチューニングを行うための全体的なセッションを表します。’direction’引数は最適化の目的を定義します。ここでは、’maximize’が指定されているため、目的関数を最大化することが目標となります。
study.optimize(objective, n_trials=1000)
この関数は、指定された目的関数’objective’について、指定された試行回数’n_trials’で最適化を行います。ここでは、1,000回の試行が行われ、その中から最良のハイパーパラメータが選ばれます。
trial = study.best_trial
全試行のうち、目的関数が最も良い値を示した試行を取得します。この試行は最適なハイパーパラメータのセットと共に保持されます。
今回は試行回数が1,000回です。試行回数を増やせば増やすほど、より良いハイパーパラメータの値を見つけ出す可能性が高まります。ただし、非常に時間がかかります。
試行回数分の探索が終了したら、見つけた最適なハイパーパラメータの値と決定係数
以下、コードです。
print('Best trial:')
print(trial.params)
print(trial.value)
簡単に説明します。
print('Best trial:'): 「Best trial」という文字列を表示します。print(trial.params): 最良の試行のハイパーパラメータを表示します。これにより、最良の評価を得たときのハイパーパラメータの値を確認できます。print(trial.value): 最良の試行時の評価指標
以下、実行結果です。
Best trial:
{'vartrans_temp': 'none', 'vartrans_atemp': 'exp', 'vartrans_humidity': 'log', 'vartrans_windspeed': 'exp'}
0.6462211873498558
この最適なハイパーパラメータの値を設定し、パイプラインを構築します。
以下、コードです。
# Optunaが見つけた最適なパラメータ
optimal_params = study.best_trial.params
# パラメータの値をもとに各変数の変換を定義
column_trans = []
for colname in X_train.columns:
vartype = get_vartype(colname)
if vartype == 'nums':
vartrans = optimal_params[f"vartrans_{colname}"]
else:
vartrans = 'onehot'
column_trans.append((
colname,
make_pipeline(
imputers[vartype],
transformers[vartrans]),
[colname]
))
# これらの変換を利用してColumnTransformerを設定
ct = ColumnTransformer(
column_trans,
remainder='drop'
)
# パイプラインの設定
pipe = Pipeline([
("preprocessor", ct),
("regressor", xgb.XGBRegressor()),
])
このコードの流れを簡単に説明します。
- `
optimal_params = study.best_trial.params`で、Optunaの学習の結果である最適化されたパラメーターを取得し、optimal_paramsに代入します。以後、optimal_paramsを使います。 - 次に、各変数について、量的変数(’nums’)か質的変数かどうかを判断し、それに応じて特定の変換方法を適用します。量的変数は、「none」、「log」、「exp」のいずれかです。「none」は変換なし、’log’は自然対数を取る変換、’exp’は指数関数を適用する変換です。質的変数は、「onehot」が適用され0と1のバイナリ変数に変換します。
- `ColumnTransformer`は、各変数に適切な変換を施します。それぞれの変数に適用すべき変換がリスト化され、指定に従って各変数に施されます。ここでは、量的でも質的でもない余剰の変数はドロップされます。
- 最後に、この全処理をScikit-learnのパイプラインにまとめます。パイプラインは、「前処理」と「回帰」の2つの主要ステージからなります。前処理ステージでは、作成した`ColumnTransformer`が適用され、各変数に設定した変換が行われます。その後の回帰ステージでは、XGBoostの回帰モデルが設定されます。後続のコードでこのパイプラインを学習し、新たなデータに対して予測を行うことができます。
このパイプラインを学習データで学習し、テストデータで検証します。
以下、コードです。
# このパイプラインを利用して学習 pipe.fit(X_train, y_train) # テストデータに対する予測 pred_y = pipe.predict(X_test) # R2スコア(決定係数)で評価 score = r2_score(y_test, pred_y) score
簡単に説明します。
pipe.fit(X_train, y_train)
事前に作成したパイプライン`pipe`を学習します。ここでは`X_train`と`y_train`データを使っています。`X_train`は学習データの説明変数、`y_train`は学習データの目的変数です。
pred_y = pipe.predict(X_test)
学習後のパイプラインを使用して、テストデータの説明変数`X_test`に対する予測を行います。これにより、学習したパイプラインがどの程度未知のデータを予測できるかを確認することができます。
score = r2_score(y_test, pred_y)
予測結果を評価します。特に、`r2_score`関数を用いて、実際の値`y_test`と予測値`pred_y`の間のR2スコア(決定係数)を計算します。R2スコアは、予測モデルがデータの変動性をどの程度説明できるかを示す指標で、1に近いほど良い予測性能を示します。
score
最後に計算されたscore(R2スコア)を出力します。これにより、モデルの性能を定量的に評価することができます。
以下、実行結果です。
0.6462211873498558
最後に、予測値(Predicted)と実測値(Actual)の散布図を描きます。
以下、コードです。
# 散布図作成
plt.figure(figsize=(8, 8))
plt.scatter(y_test, pred_y, alpha=0.5)
plt.plot(
[min(y_test), max(y_test)],
[min(y_test), max(y_test)],
color='red',
lw=2.0
)
plt.xlabel('Actual')
plt.ylabel('Predicted')
plt.title('Scatter plot of Actual vs Predicted')
plt.grid(True)
plt.show()
以下、実行結果です。
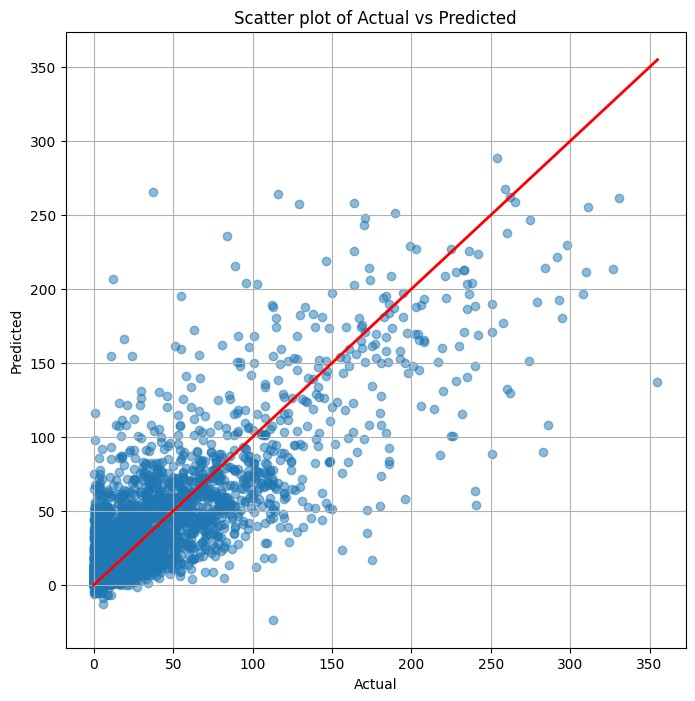
XGBoostのハイパーパラメータ調整付きのパターン
先ず、変換器を自動選択するための、Optunaの目的関数を作ります。
以下、コードです。
# Optunaの目的関数
def objective(trial):
column_trans = []
for colname in X_train.columns:
vartype = get_vartype(colname) # 変数のタイプを取得
if vartype == 'nums': # 量的変数の場合
vartrans = trial.suggest_categorical(
f"vartrans_{colname}",
['none', 'log', 'exp'] # 変換方法を指定
)
else: # カテゴリ変数の場合
vartrans = 'onehot' # ワンホットエンコーディングを選択
column_trans.append(
(
colname, # 変数名
make_pipeline(
imputers[vartype], # 変数のタイプに応じたImputerを適用
transformers[vartrans] # 変換方法に応じたTransformerを適用
),
[colname] # 変換を適用する列を指定
)
)
ct = ColumnTransformer(
column_trans,
remainder='drop' # 指定されていない列は削除
)
# XGBoostのハイパーパラメータ
xgb_params = {
"learning_rate": trial.suggest_loguniform("learning_rate", 1e-8, 1.0),
"n_estimators": trial.suggest_int("n_estimators", 10, 1000),
"max_depth": trial.suggest_int("max_depth", 1, 20),
"subsample": trial.suggest_discrete_uniform("subsample", 0.1, 1.0, 0.01),
"colsample_bytree": trial.suggest_discrete_uniform("colsample_bytree", 0.1, 1.0, 0.01),
}
pipe = Pipeline(
[
("preprocessor", ct), # 前処理
("regressor", xgb.XGBRegressor(**xgb_params)) # 予測モデル
]
)
pipe.fit(X_train, y_train) # 学習
pred = pipe.predict(X_test) # 予測
return r2_score(y_test, pred) # 戻り値はR2スコア
では、Optunaの`objective`関数を使いハイパーパラメータチューニングを実施します。
以下、コードです。
study = optuna.create_study(direction='maximize') study.optimize(objective, n_trials=1000) trial = study.best_trial
試行回数分の探索が終了したら、見つけた最適なハイパーパラメータの値と決定係数
以下、コードです。
study = optuna.create_study(direction='maximize') study.optimize(objective, n_trials=1000) trial = study.best_trial
以下、実行結果です。
Best trial:
{'vartrans_temp': 'log', 'vartrans_atemp': 'log', 'vartrans_humidity': 'exp', 'vartrans_windspeed': 'none', 'learning_rate': 0.004984254050964274, 'n_estimators': 844, 'max_depth': 9, 'subsample': 0.44000000000000006, 'colsample_bytree': 0.8}
0.6699382633957319
この最適なハイパーパラメータの値を設定し、パイプラインを構築します。
以下、コードです。
# Optunaが見つけた最適なパラメータを使用
optimal_params = study.best_trial.params
# ハイパーパラメータの設定
xgb_params = {
param_name:
optimal_params.get(param_name)
for param_name in xgb_param_names
}
# パラメータの値をもとに各変数の変換を定義
column_trans = []
for colname in X_train.columns:
vartype = get_vartype(colname)
if vartype == 'nums':
vartrans = optimal_params.get(f"vartrans_{colname}")
else:
vartrans = 'onehot'
column_trans.append((
colname,
make_pipeline(
imputers[vartype],
transformers[vartrans]),
[colname]
))
# これらの変換を利用してColumnTransformerを設定
ct = ColumnTransformer(
column_trans,
remainder='drop'
)
# パイプラインの設定
pipe = Pipeline([
("preprocessor", ct),
("regressor", xgb.XGBRegressor(**xgb_params)),
])
このパイプラインを学習データで学習し、テストデータで検証します。
以下、コードです。
# このパイプラインを利用して学習 pipe.fit(X_train, y_train) # テストデータに対する予測 pred_y = pipe.predict(X_test) # R2スコア(決定係数)で評価 score = r2_score(y_test, pred_y) score
以下、実行結果です。
0.6699382633957319
最後に、予測値(Predicted)と実測値(Actual)の散布図を描きます。
以下、コードです。
# 散布図作成
plt.figure(figsize=(8, 8))
plt.scatter(y_test, pred_y, alpha=0.5)
plt.plot(
[min(y_test), max(y_test)],
[min(y_test), max(y_test)],
color='red',
lw=2.0
)
plt.xlabel('Actual')
plt.ylabel('Predicted')
plt.title('Scatter plot of Actual vs Predicted')
plt.grid(True)
plt.show()
以下、実行結果です。
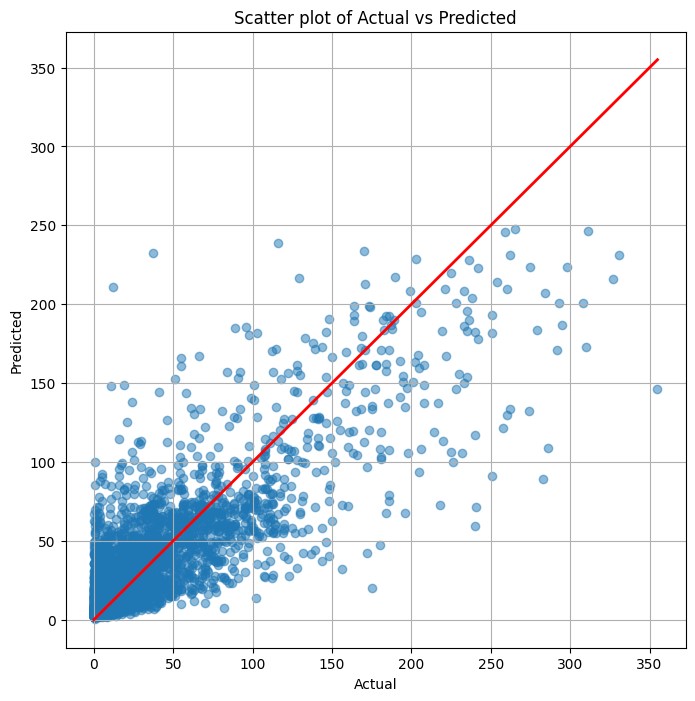
まとめ
今回は、変数ごとに利用する変換器を自動選択する方法についてお話ししました。
実務では、変数の特性の応じ変換する処理を変えることは多いです。
そういう意味でも、自動で適切な変換器をきめ細やかに設定するアプローチは非常に有意義です。