

データが語る物語の奥深くには、単なる相関関係を超えた「因果関係」が隠されています。
企業が新たなマーケティング戦略を展開する際、医療専門家が治療法の効果を評価する時、または政策立案者が社会政策の成果を測る際に、単に「何が起こったか」ではなく、「なぜそれが起こったのか」を理解することが求められます。

この複雑な問いに答える鍵となるのが「機械学習因果推論」です。
機械学習による因果推論は、最新のデータサイエンスの進化形態であり、観測データから深い因果関係を抽出し、より賢明な意思決定を実現するための強力なツールです。
今回は、ビジネス、医療、政策立案といった様々な分野での具体的な応用事例を通じて、機械学習因果推論の簡単な活用方法を紹介します。
Contents [hide]
機械学習と因果推論の出会い
機械学習の基本とその限界
機械学習は、データからパターンや関係性を学習し、予測や分類を行う技術です。教師あり学習、教師なし学習、強化学習など、様々な手法があります。
これらの技術は、画像認識、自然言語処理、推薦システムなど、多岐にわたる分野で応用されています。
しかし、伝統的な機械学習手法は、「何が起こるか」を予測することに重点を置いていますが、「なぜそれが起こるのか」、つまり因果関係については明らかにできません。
例えば、氷が溶けることと気温の上昇との間に相関関係があると機械学習モデルが示しても、これらの現象の間の因果関係は示されません。
因果推論とは何か?
因果推論は、特定の因果関係を理解し、証明するための手法です。
「ある事象が別の事象にどのように影響を与えるか」を理解することが目的です。
これにより、ただ相関関係を見つけ出すだけでなく、ある事象が他の事象に対してどのような効果を持つのかを明らかにしようとします。

重要性が増している
ビジネスにおいても因果推論は非常に重要です。
例えば、マーケティングキャンペーンが売上にどのような影響を与えたのか、ある人事政策が従業員の生産性や満足度にどのように作用するのかを理解することができます。これにより、意思決定者はより効果的な戦略を立てることができるようになります。
従来の多くの因果推論は、ランダム化比較試験(RCT)などの実験的アプローチに基づくことが多いですが、実際には多くの場合、RCTを行うことが不可能または非現実的です。
そのため、観測データから因果関係を推定する手法が求められています。このような背景から、機械学習因果推論が注目を集めています。
従来の機械学習との違い
従来の機械学習と機械学習因果推論は、データからの学習を通じて洞察を得るという共通点がありますが、その目的とアプローチには大きな違いがあります。
従来の機械学習の目的と限界
従来の機械学習の主な目的は、データ内のパターンや相関関係を発見し、これらの知見を用いて予測モデルを構築することです。
たとえば、過去の顧客データから購買行動を予測するモデルを作成することができます。
しかし、これらのモデルは「何が起こるか」を予測するのには有用ですが、「なぜそれが起こるのか」、つまり因果関係を明らかにすることはできません。
例えば、ある商品の販売促進キャンペーンが売上の増加と相関していることをモデルが示しても、このキャンペーンが売上増加の原因であるかどうか、または他の要因(例えば、同時期に行われた他のマーケティング活動や季節的要因)が関係しているのかを判断することはできません。
機械学習因果推論が解き明かすデータの物語
機械学習因果推論は、このような限界を克服し、データから因果関係を推定しようとするアプローチです。
因果関係の理解は、ビジネス戦略や政策決定において非常に重要です。なぜなら、これにより効果的な介入(例えば、マーケティングキャンペーンや価格戦略の変更)を計画し、その結果を予測することができるからです。
機械学習因果推論は、「もしXが起こったら、Yはどう変わるか」という形式の質問に答えることを目指しています。
これには、介入がなかった場合の世界(反実仮想)と実際の介入があった場合の世界の比較を通じて、特定の因果効果を推定する技術が含まれます。例えば、あるマーケティングキャンペーンが実施された場合とされなかった場合の売上を比較することで、キャンペーンの効果を測定することができます。
機械学習因果推論の基礎のキソ
機械学習因果推論の概要
機械学習因果推論は、従来の統計学に基づく因果推論の枠組みに、機械学習の技術を応用したものです。
因果推論の目的は、「ある介入が行われた場合と行われなかった場合とで、結果にどのような差が生じるか」を推定することにあります。
これは、単に相関関係を見つけ出すのではなく、ある特定の処置や政策が結果に「原因」としてどのような効果をもたらすかを明らかにしようとするものです。
機械学習の手法を因果推論に適用することで、データからより複雑なパターンを学習し、介入の効果をより正確に推定することが可能になります。
このアプローチは、特に大規模なデータセットを扱う際や、データの構造が複雑な場合に有効です。
平均処置効果(ATE)
従来の統計学に基づく因果推論の枠組みで登場するのが、平均処置効果(Average Treatment Effect, ATE)です。
平均処置効果は、全個体にわたって介入(処置)を行った場合と行わなかった場合の結果の差の平均値を表します。
式で表すと以下のようになります。
ATEを推定することで、ある処置が全体としてどの程度の効果を持つかを把握することができます。
たとえば、企業Aがメールマーケティングキャンペーンを実施し、製品の購入率に及ぼす影響を評価したいとします。
- 介入グループ: メールキャンペーンを受け取る顧客
- コントロールグループ: 通常のマーケティングのみ受け取る顧客
ここで、両グループの製品購入率を比較して、キャンペーンの効果とします。それがATEです。
この事例では、メールマーケティングキャンペーンを実施することで、顧客の購入率が平均で10%ポイント向上しました。
つまり、メールマーケティングキャンペーンが顧客の購入行動に有効であることを示す平均処置効果(ATE)を通じて明らかになったということです。
ただ、平均処置効果(ATE)は全体だけです。効果の高い顧客群を見つける、効果の高い顧客群を狙い撃ちにする、といった活用できません。
要するに、パーソナライズされた政策立案や介入計画ができません。
そのようなことをするには、特定の条件や特性を持つ個体群に対する介入の効果を評価する指標が必要になります。条件付き平均処置効果(Conditional Average Treatment Effect, CATE)です。
条件付き平均処置効果(CATE)
条件付き平均処置効果は、特定の条件や特性を持つ個体群に対する介入の効果を評価する指標です。
具体的には、特定の特性
CATEを用いることで、異なる特性を持つ群間で介入の効果にどのような違いがあるのかを評価することが可能になります。
これにより、よりパーソナライズされた政策立案や介入計画が可能になります。
たとえば、企業Bが新しいオンライン広告キャンペーンを実施し、顧客の年齢層によってキャンペーンの効果が異なるかどうかを評価したいとします。
- 介入: 新しいオンライン広告キャンペーン
- 顧客群: 年齢層に基づいて顧客を区分(例:20代、30代)
- 各年齢層でのキャンペーン前後の製品購入率を比較し、年齢層ごとのキャンペーン効果を評価
年齢層に基づいた顧客区分
CATEを用いることで、各年齢層の群間で介入の効果にどのような違いがあるのかを評価することが可能になります。
- 20代の顧客層でのCATEは0.15(15%ポイント購入率向上)。
- 30代の顧客層でのCATEは0.05(5%ポイント購入率向上)。
この例では、オンライン広告キャンペーンが20代の顧客層に対しては15%ポイント、30代の顧客層に対しては5%ポイントの購入率向上効果があることが示されました。
CATEを用いることで、特定の顧客層に対するキャンペーンの効果をより詳細に理解し、ターゲットを絞ったマーケティング戦略を立てることが可能になります。
機械学習因果推論の強み
従来の統計的因果推論に比べ幾つかの強みがあります。
機械学習による因果推論は、特に条件付き平均処置効果(CATE)の推定において顕著な強みを持っています。これは、機械学習が複雑なデータ構造や非線形関係をモデル化する能力に優れているためです。
以下に、機械学習がATEとCATEの推定において持つ強みを、従来の統計的因果推論手法と比較しながら説明します。
ATEの推定における機械学習の強み
- データ駆動型モデリング: 機械学習は、データから直接パターンを学習するため、モデルの仮定が少なく、従来の統計モデルで必要とされる形式の仮定に依存しません。これにより、データの真の構造をより正確に捉えることが可能となり、ATEの推定精度が向上する場合があります。
- 大規模データセットの処理能力: 現代の機械学習アルゴリズムは、大量のデータを処理する能力に優れています。従来の統計手法では扱いにくい大規模データセットにおいても、効果的に因果推論を行うことができます。
CATEの推定における機械学習の特筆すべき強み
- 高度なパーソナライゼーション: CATEの推定は、特定の個体群や条件に対する介入の効果を特定することを目的としています。機械学習は、特に個々の特徴や条件に基づいて異なる効果を捉えることに長けており、従来の統計手法よりもはるかにパーソナライズされた推論を可能にします。
- 複雑な相互作用のモデリング: 機械学習アルゴリズムは、複数の変数間の複雑な相互作用を捉える能力があります。これにより、異なる条件下での処置効果がどのように変化するかをより正確に理解することが可能になります。
従来の統計的因果推論手法も、ATEやCATEの推定において有用ですが、モデルの仮定が厳格であること、複雑なデータ構造や相互作用をモデル化するのが難しいことがあります。
機械学習による因果推論は、これらの制約を克服し、より精密な推定を可能にするため、特にCATEの推定においてその強みが発揮されます。それにより、異なるサブグループや個々の条件におけるより細かい因果効果の分析が可能となり、パーソナライズされた介入戦略や政策立案に貢献します。
機械学習因果推論の注意点
機械学習を用いた因果推論は、多くの強みを持つ一方で、従来の統計的因果推論手法と比較して注意すべき点もいくつか存在します。
これらは主に、解釈の難しさ、過剰適合のリスク、因果関係の正確な特定に関連しています。
解釈の難しさ
- モデルの複雑さ: 機械学習モデルは、しばしば「ブラックボックス」とみなされるほど複雑で、その内部の動作が理解しにくいことがあります。結果として、得られた因果関係の推定がどのようなメカニズムに基づいているのかを解釈し、説明することが難しくなります。
- 特徴量の重要性の把握: 従来の統計モデルでは、変数の係数を通じてその影響を直接評価できますが、機械学習モデルでは特徴の重要性を理解するために追加の手法(例えば、特徴重要度スコア)が必要になることがあります。
過剰適合のリスク
- データへの過剰な適合: 機械学習モデルは、訓練データに対して非常によく適合するように設計されていますが、これが過剰適合(オーバーフィッティング)を引き起こすことがあります。過剰適合したモデルは新しいデータに対する汎化能力が低く、現実世界での因果推論の精度が低下する原因となります。
- 適切な検証手法の選択: モデルの汎化能力を確認するためには、クロスバリデーションや他の検証手法を適切に用いることが重要です。しかし、因果推論の文脈では、伝統的な機械学習の評価指標が直接適用できない場合があり、因果効果の正確な推定のために特別な検証手法が必要になることがあります。
因果関係の特定
- 因果関係の特定: 機械学習モデルは相関関係を捉えるのに優れていますが、それだけでは因果関係を特定することはできません。従来の統計的因果推論では、ランダム化実験や因果推論のための統計的手法(例:工具変数法)を用いて因果関係を明確にすることがあります。機械学習を用いる場合も、因果推論を行う際には、適切なデータと仮定に基づいて因果モデルを構築することが重要です。
これらの注意点に対処するためには、機械学習モデルの選択と設定に細心の注意を払い、データの前処理、モデルの訓練、および結果の解釈において、因果推論の原則に基づいた厳密なアプローチを採用することが重要です。
また、モデルの解釈性を高める手法を積極的に採用し、過剰適合を避けるための戦略を適用することが求められます。
CausalMLを使った機械学習因果推論
CausalMLライブラリを使用して、実際のビジネスシナリオにおける因果推論分析を実行する方法について解説します。
CausalMLのインストールから始まり、データの準備と前処理、そしてCATE(条件付き平均処置効果)の推定までを含みます。
Pythonライブラリー「CausalML」とは?
CausalMLは因果推論と因果機械学習のためのPythonライブラリです。
CausalMLは、次のような主要な機能があります。
- 因果効果の推定: 処置群と対照群の比較、傾向スコアマッチング、二重ロバスト推定量など、因果効果を推定するための様々な手法を実装しています。
- 交絡因子の調整: 交絡因子の存在下で因果効果を推定するための手法、例えば傾向スコアを用いた調整などを提供します。
- 反実仮想推論: 反実仮想推論を行うためのツールを提供します。これにより、「もし処置が異なっていたら、結果はどうなっていたか」といった質問に答えることができます。
- 因果機械学習: 因果推論の原理を機械学習モデルに組み込むことで、予測モデルの解釈性や頑健性を向上させることができます。
このライブラリーを使用することで、因果推論のための最先端の手法を簡単に適用することができます。
CausalMLのインストール
まず、Python環境にCausalMLライブラリをインストールする必要があります。以下のコマンドを実行してインストールします。
以下、コードです。
pip install causalml
データ準備と前処理
まず、今回利用するサンプルデータを生成します。その後、簡単な前処理(特徴量のスケーリング)、そしてデータの分割(訓練データとテストデータ)します。
前処理として、通常はデータのクリーニング、欠損値の処理、カテゴリ変数のエンコーディングなどを実施しますが、今回はスケーリング(標準化)のみ実施します。
以下、コードです。
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# データの読み込み(例として仮想的なデータセットを使用)
# 実際の分析では、pd.read_csvなどを用いてデータを読み込む
data = pd.DataFrame({
'age': np.random.randint(18, 65, size=1000),
'income': np.random.normal(50000, 15000, size=1000),
'treatment': np.random.binomial(1, 0.5, size=1000),
'outcome': np.random.normal(10000, 1000, size=1000)
})
# アウトカムの修正
data['outcome'] = data['outcome'] \
+ data['treatment'] * (1000 - data['age']*100 + data['income']*0.1)
# 前処理:特徴量のスケーリング
scaler = StandardScaler()
features = ['age', 'income']
data[features] = scaler.fit_transform(data[features])
# データを訓練用とテスト用に分割
train_data, test_data = train_test_split(
data,
test_size=0.2,
random_state=42)
このコードの概要を説明します。
ライブラリのインポート
pandas(データの操作と分析に使われる)、numpy(数値コンピューティングに使われる)、train_test_split(データの分割に使われる)とStandardScaler(特徴量のスケーリングに使われる)をインポートしています。
データ生成
年齢(age)、収入(income)、介入(treatment)、結果(outcome)という4つの変数を持つサンプルデータセットを作成しています。
- 年齢(age)は18から65の間のランダムな整数
- 収入(income)は平均50000、標準偏差15000の正規分布からサンプリングされる値
- 介入(treatment)は1の確率0.5の二項分布からサンプリングされる値(つまり0か1のどちらかの整数)
- 結果(outcome)は平均10000、標準偏差1000の正規分布からサンプリングされる値
ちなみに、結果(outcome)が目的変数です。
アウトカムの修正
結果(outcome)は、介入(treatment)が1である場合に年齢(age)に依存した効果と収入(income)に依存した効果が加わるとしてアウトカム結果が調整されています。
前処理
続いて特徴量のスケーリングが行われます。年齢(age)と収入(income)という二つの特徴量が標準化されます。これは、データが一般的に使われるモデル(例えば、SVMやロジスティック回帰など)により良く適用され、結果としてモデルのパフォーマンスが向上するためです。
データを訓練用とテスト用に分割
データセットは訓練セットとテストセットに分割されます。この特定のケースでは、テスト用に全体の20%(0.2)が割り当てられ、訓練用には残りの80%が使われます。
CATEの推定方法と解釈
データの準備ができたら、CausalMLを使用してCATEを推定します。ここでは、XGBoostをベースとした推定器XGBTRegressorを使用します。
以下、コードです。
from causalml.inference.meta import XGBTRegressor
# CATE推定器のインスタンスを作成
cate_estimator = XGBTRegressor()
# CATEを推定
X_train = train_data[features]
treatment_train = train_data['treatment']
y_train = train_data['outcome']
cate_estimator.fit(
X=X_train,
treatment=treatment_train,
y=y_train)
# テストデータでCATEを推定
X_test = test_data[features]
cate_estimates = cate_estimator.predict(X_test)
# 推定されたCATEの平均値を表示
print("Estimated CATE:", np.mean(cate_estimates))
このコードはCausalMLライブラリを用いて因果関係を推定するものです。
介入(treatment)の効果(CATE: Conditional Average Treatment Effect)をひとりひとりの個体で評価します。
CausalMLからXGBTRegressorをインポート
XGBTRegressorで、ひとりひとりの個体に対する介入(treatment)の効果(CATE: Conditional Average Treatment Effect)を推定します。
CATE推定器のインスタンス作成
CATE推定器としてXGBTRegressorのインスタンスを作成します。
CATEの推定
作成したインスタンスに対し、fitメソッドを用いてCATEを推定します。引数として訓練データの特徴量(X_train)、treatment(treatment_train)、アウトカム(y_train)を入力します。
テストデータに対するCATEの推定
推定器の学習が終了した後、テストデータに対してpredictメソッドを用いてCATEを推定します。
推定されたCATEの平均値の表示
推定されたCATEの平均値を表示します。ただし、この結果だけで最終的な結論を導くことはできず、さらに詳細な解析が必要になることが一般的です。
cate_estimatesは、個々の特徴量が持つ介入の平均的な効果(CATE)です。要するに、今回の場合ですと個人単位で効果が推定される、ということです。
年齢や収入などの特性を持つ人々が同じ介入(例:メールキャンペーンなど)を受けても、その効果は人によって異なる可能性があります。
CATEを用いると、これらの個別の特性(特徴量)の違いを考慮した上で、各特性が介入効果(例:メールキャンペーンなどによる効果)にどのように影響するかを推定できます。
この情報は、特定の特性を持つ個体に対して最も効果的な介入を特定し、データ駆動型の意思決定を支援するのに役立ちます。
次に、年齢(age)と収入(income)ごとにCATEを出力します。単に、個々に出力されたCATEを集計するだけです。
以下、コードです。
import matplotlib.pyplot as plt
# テストデータを元のスケールに戻す
X_test_original = X_test.copy()
X_test_original[features] = scaler.inverse_transform(X_test[features])
# グループ化
X_test_original['age_bin'] = pd.cut(X_test_original['age'], bins=6)
X_test_original['income_bin'] = pd.cut(X_test_original['income'], bins=10)
# CATEを集計
X_test_original['cate'] = cate_estimates
cate_by_age_bin = X_test_original.groupby('age_bin')['cate'].mean()
cate_by_income_bin = X_test_original.groupby('income_bin')['cate'].mean()
#
# グラフを描画
#
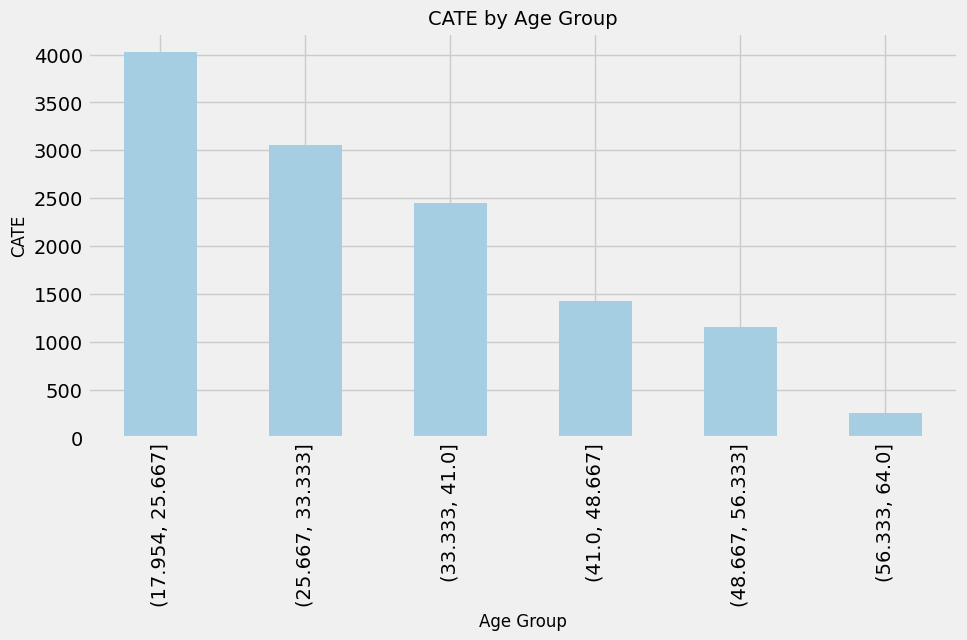
# 年齢毎のCATE
plt.figure(figsize=(10, 5))
cate_by_age_bin.plot(kind='bar')
plt.title('CATE by Age Group', fontsize=14)
plt.xlabel('Age Group', fontsize=12)
plt.ylabel('CATE', fontsize=12)
plt.grid(True)
plt.show()
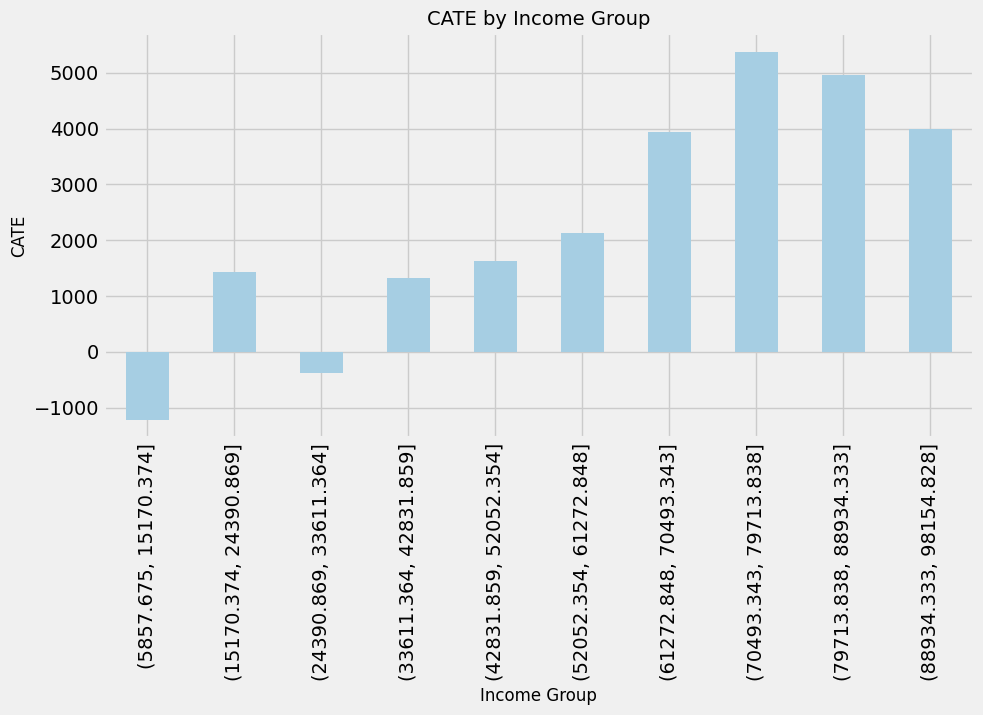
# 収入毎のCATE
plt.figure(figsize=(10, 5))
cate_by_income_bin.plot(kind='bar')
plt.title('CATE by Income Group', fontsize=14)
plt.xlabel('Income Group', fontsize=12)
plt.ylabel('CATE', fontsize=12)
plt.grid(True)
plt.show()
このコードは、「年齢」および「収入」グループごとに状態条件付き平均処置効果(CATE)を計算し、それらを棒グラフで視覚化します。
テストデータを元のスケールに戻す
scaler.inverse_transform()を用いることで特徴量(年齢と収入)を元のスケールに戻しています。
グループ化
pd.cut関数を用いて年齢と収入のデータをそれぞれ6グループと10グループに分けています。これにより、各特性(年齢と収入)ごとにCATEを計算するグループが生成されます。
CATE集計
既存のCATE推定値(cate_estimates)を用いて、各年齢グループと収入グループでのCATEの平均値を計算しています。具体的には、groupbyメソッドとmeanメソッドを用いてグループごとの平均CATEを算出しています。
グラフの描画
年齢や収入の各グループについてCATEの棒グラフを描画しています。これにより、年齢や収入の各グループにおける処置効果が一目でわかります。カスタムタイトル、ラベル、およびグリッドラインを含む標準的なmatplotlibのプロット定義が行われています。
このコードによって、CausalMLを用いて算出されたCATEの結果を特性(この場合は年齢と収入)ごとにグループ化し、視覚化することで、具体的な介入が特定の特性を持つ個体にどのように影響する可能性があるか、わかりやすく示されます。
以下、実行結果です。
まとめ
今回は、機械学習による因果推論を簡単に実施することのできるPythonライブラリー CausalML を紹介しました。
次回以降、幾つかの事例などを紹介していきます。
特別難しいことはありませんが、イメージが付きやすいかと思います。