
データが溢れる現代社会において、情報を効果的に伝達する手段としてのデータ可視化の重要性は、ますます高まっています。
単に数字や表を並べるだけでなく、データを視覚的に表現することで、複雑な情報も直感的に理解できるようになります。
そして、この可視化の世界に革命を起こしているのが、インタラクティブな可視化技術です。
今回は、このplotlyを使用したPythonでのインタラクティブデータ可視化について、基礎的な内容を紹介します。
Contents [hide]
インタラクティブ可視化の重要性とplotly
インタラクティブ可視化は、静的なグラフやチャートの限界を超え、ユーザーがデータと対話できる環境を提供します。
- データの探索:ユーザーは自由にデータをズームイン/アウトしたり、特定の部分にフォーカスしたりすることができ、データの細部まで探索できます。
- 多次元データの理解:複雑な多次元データも、インタラクティブな要素を通じて効果的に表現できます。
- エンゲージメントの向上:動的で操作可能なグラフは、ユーザーの興味を引き、データへの理解を深めます。
- カスタマイズ可能な表示:ユーザーが自身のニーズに合わせてデータの表示方法を調整できます。
- リアルタイムデータの可視化:動的に更新されるデータも、スムーズに表現できます。
Pythonの可視化ライブラリの中でも、plotlyは特にインタラクティブ可視化に優れています。
以下は、主な特徴と利点です。
- 豊富なグラフタイプ:基本的な折れ線グラフや散布図から、3Dプロット、地理データの可視化まで、幅広いグラフタイプをサポートしています。
- 高度なインタラクティブ機能:ズーム、パン、ホバー情報の表示など、直感的な操作が可能です。
- 美しいデザイン:デフォルトでも美しいグラフが作成でき、さらに細かなカスタマイズも可能です。
- Web対応:HTML+JavaScriptベースで動作するため、ウェブブラウザ上で簡単に表示・共有できます。
- Dashboardの作成:Plotly Dashを使用することで、インタラクティブなダッシュボードを簡単に作成できます。
- 大規模データへの対応:効率的なデータ処理により、大規模なデータセットも滑らかに可視化できます。
plotlyの準備(ライブラリのインストールなど)
plotlyを使用してデータ可視化を始める前に、まずは適切な準備が必要です。
インストール方法
plotlyは、pipを使用して簡単にインストールできます。
以下、コードです。
pip install plotly
conda系を使用している場合は、以下のコマンドでインストールできます。
conda install -c plotly plotly
基本的となるモジュールなど
plotlyをインポートし、基本的な設定を行うには、以下のコードでモジュールなどを読み込みます。
import plotly.graph_objects as go import plotly.express as px from plotly.subplots import make_subplots
plotly.graph_objects(go) と plotly.express (px) は、どちらもデータの可視化に使用されます。どちらか一方だけで十分です。
凝ったグラフを作るならplotly.graph_objects (go) 、さくっと簡易的に作るなら plotly.express (px) といった感じです。
ちなみに、make_subplotsは、複数のサブプロットを作成する際に使用します。
これらの3つを最初にインポートしておけば、大概の場合大丈夫です。
簡単なプロット例
簡単な例として散布図を作成してみます。
以下、コードです。
# サンプルデータの作成
df = px.data.iris()
# 散布図の作成
fig = px.scatter(
df,
x='sepal_width',
y='sepal_length',
color='species',
title='Iris Dataset - Sepal Width vs Length')
# プロットの表示
fig.show()
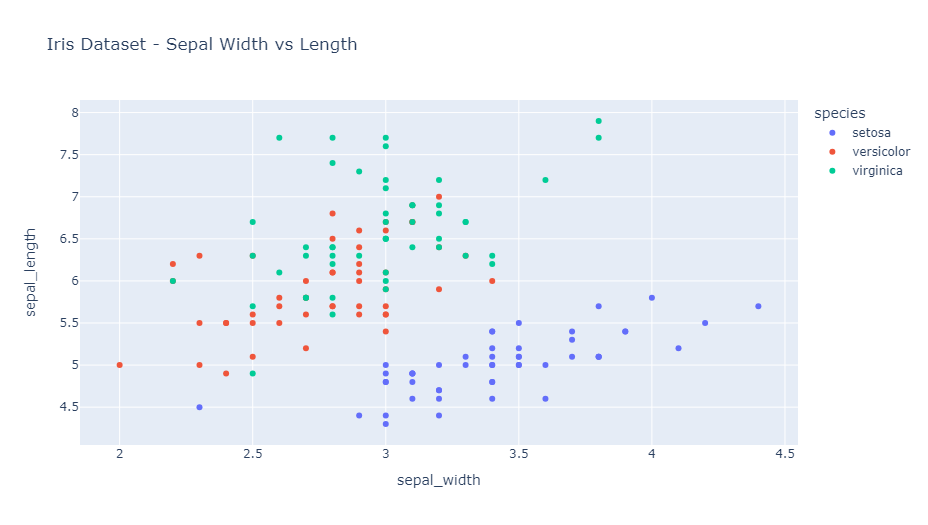
このコードは、Iris(あやめ)データセットを使用して、がく片の幅と長さの関係を示す散布図を作成します。colorパラメータにより、異なる種別が色分けされます。
以下、実行結果です。
ちょっとした注意点
- plotlyのバージョンは頻繁に更新されるため、最新のドキュメントを参照することをお勧めします。
- ウェブブラウザベースの出力を生成するため、インターネット接続が必要な場合があります。
- 大規模なデータセットを扱う場合は、メモリ使用量に注意が必要です。
基本的なプロットの作成
plotlyを使用して、データ可視化の基礎となる3つの基本的なプロットタイプ(折れ線グラフ、散布図、棒グラフ)の作成方法を紹介します。
折れ線グラフ(Line charts)
折れ線グラフは、時系列データや連続的な変化を表現するのに適しています。
以下、コードです。
import plotly.express as px
import pandas as pd
# サンプルデータの作成
df = pd.DataFrame({
'x': range(10),
'y1': [i**2 for i in range(10)],
'y2': [10*i for i in range(10)]
})
# 折れ線グラフの作成
fig = px.line(
df,
x='x',
y=['y1', 'y2'],
title='Basic Line Chart')
fig.show()
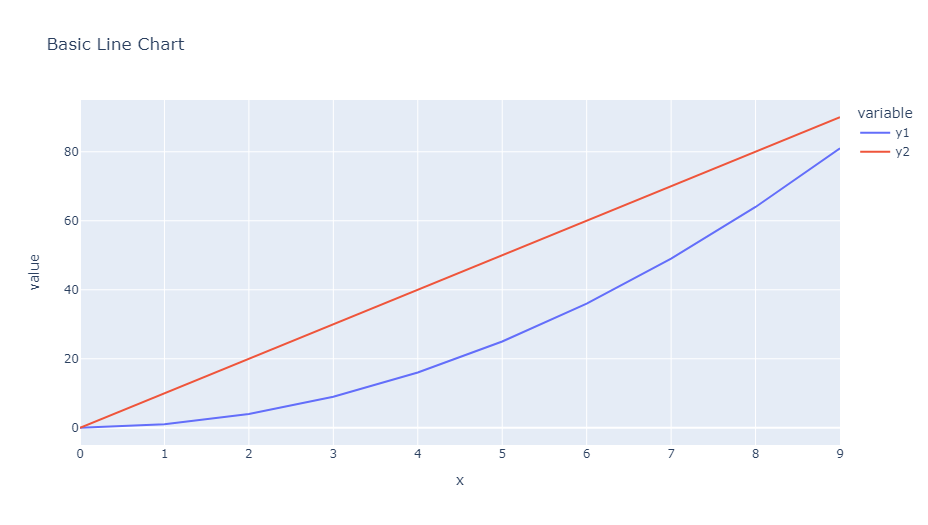
このコードでは、2つの異なる系列(y1とy2)を同じグラフ上に描画しています。px.line関数を使用することで、簡単にマルチライングラフを作成できます。
以下、実行結果です。
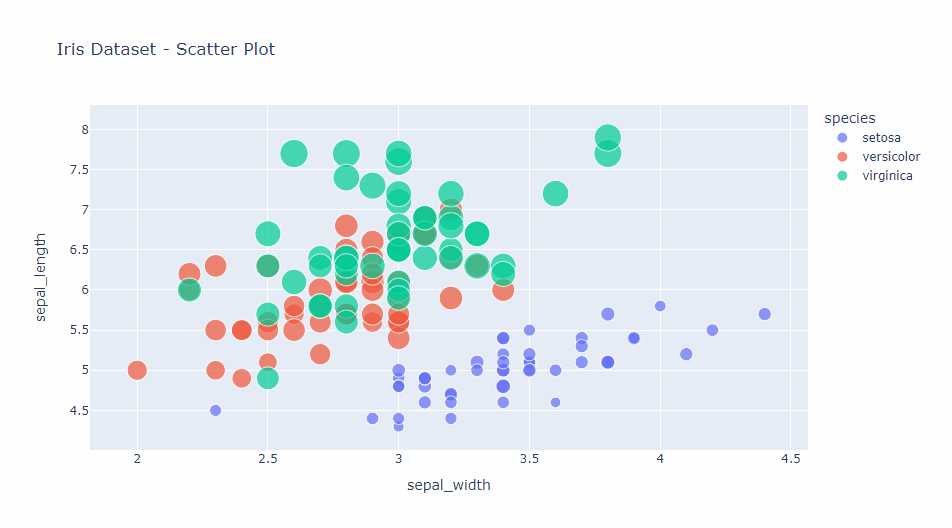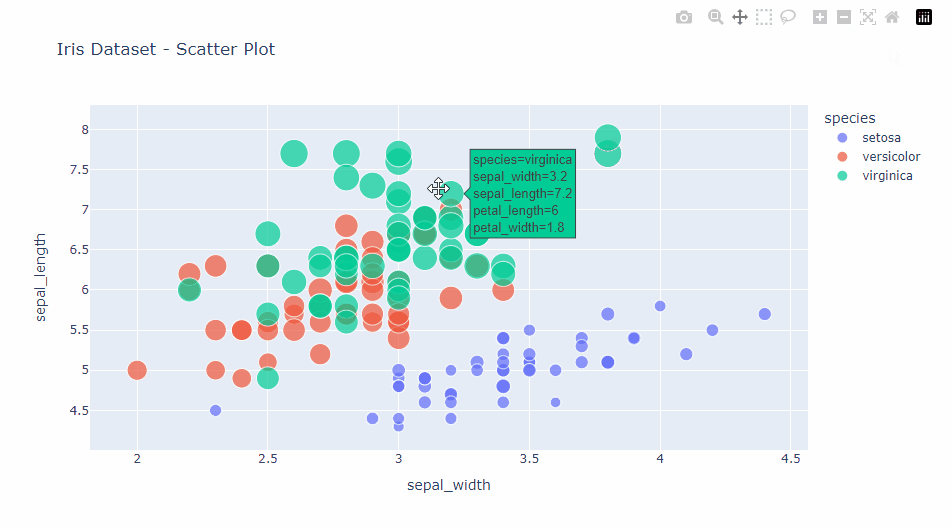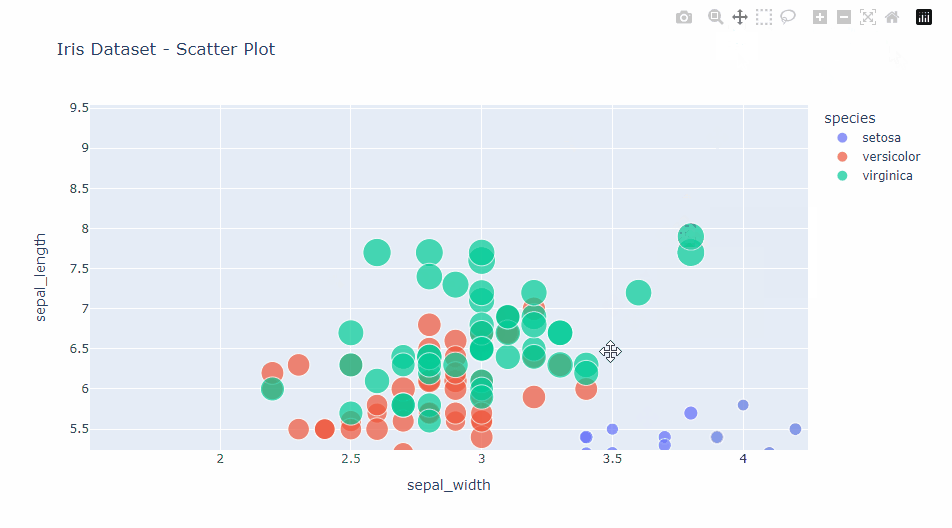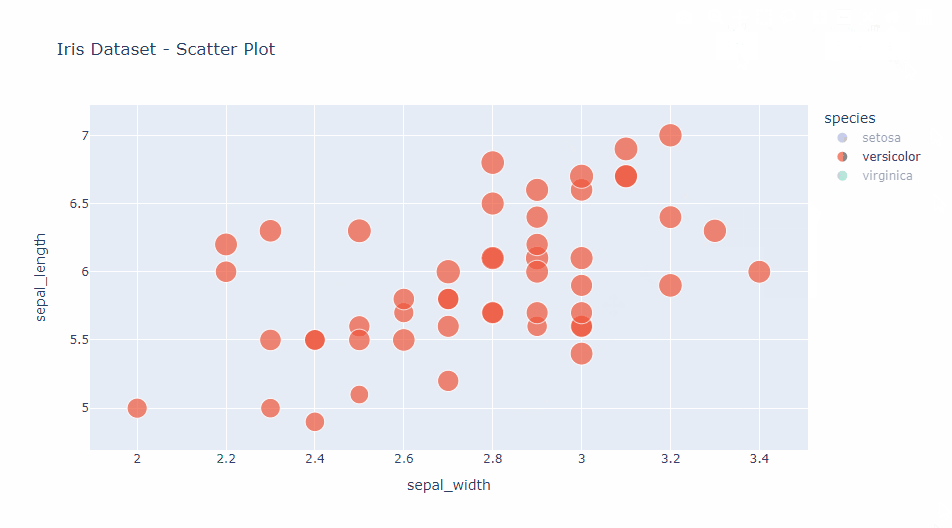
散布図(Scatter plots)
散布図は、2つの変数間の関係を可視化するときに利用します。
以下、コードです。
import plotly.express as px
# Irisデータセットの読み込み
df = px.data.iris()
# 散布図の作成
fig = px.scatter(
df,
x="sepal_width",
y="sepal_length",
color="species",
size='petal_length',
hover_data=['petal_width'],
title="Iris Dataset - Scatter Plot")
fig.show()
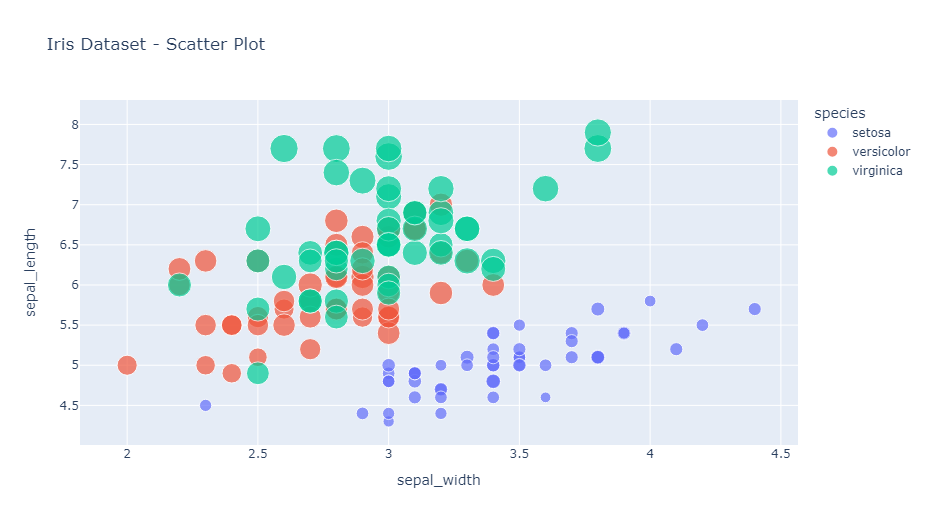
この例では、Irisデータセットを使用して、がく片の幅と長さの関係を示しています。
colorパラメータで種別を色分けし、sizeパラメータで花弁の長さを点の大きさで表現しています。
また、hover_dataパラメータにより、マウスオーバー時に花弁の幅も表示されます。
以下、実行結果です。
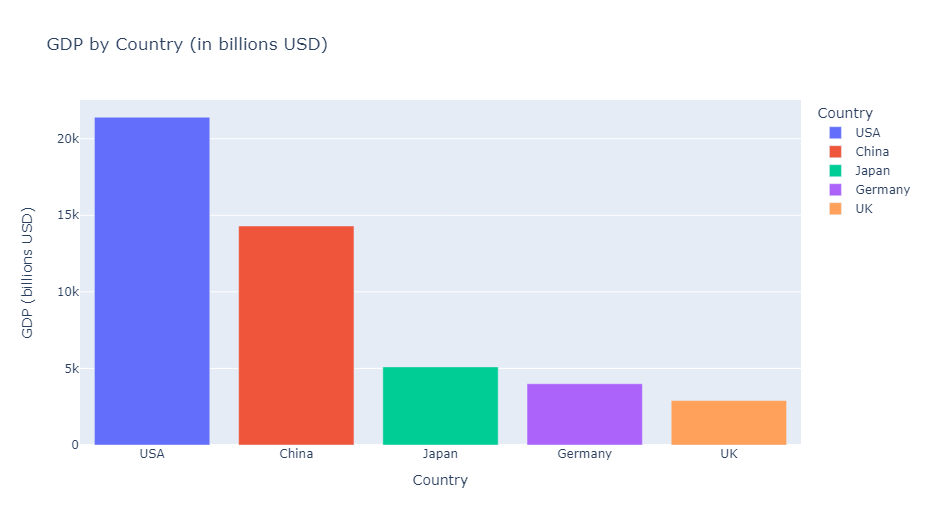
棒グラフ(Bar charts)
棒グラフは、カテゴリ間の比較や時系列での変化を表現するときに利用します。
以下、コードです。
import plotly.express as px
import pandas as pd
# サンプルデータの作成
df = pd.DataFrame({
'Country': ['USA', 'China', 'Japan', 'Germany', 'UK'],
'GDP': [21400, 14300, 5100, 4000, 2900]
})
# 棒グラフの作成
fig = px.bar(
df,
x='Country',
y='GDP',
title='GDP by Country (in billions USD)',
labels={'GDP': 'GDP (billions USD)'},
color='Country')
fig.show()
この例では、国別のGDPを棒グラフで表現しています。
colorパラメータを使用することで、各棒に異なる色を割り当てています。
以下、実行結果です。
インタラクティブ機能の活用
plotlyの強みは、これらの基本的なグラフに豊富なインタラクティブ機能が標準で組み込まれていることです。
例えば、以下の機能を試してみてください。
- ズームイン/アウト:グラフ領域をドラッグして特定の領域にズームインできます。
- パン:ズームイン後、グラフをドラッグして表示領域を移動できます。
- ホバー情報:データポイントにマウスを乗せると、詳細情報が表示されます。
- 凡例のクリック:凡例をクリックすることで、特定のデータ系列の表示/非表示を切り替えられます。
- ダブルクリックでリセット:グラフ領域をダブルクリックすると、元の表示に戻ります。
これらの基本的なプロットタイプとインタラクティブ機能を組み合わせることで、データの洞察を得るための強力なツールを手に入れることができます。
インタラクティブ機能の活用
plotlyの大きな特徴の一つは、豊富なインタラクティブ機能です。
これらの機能を活用することで、ユーザーがデータと対話し、より深い洞察を得ることができます。
ズームとパン
ズームとパン機能は、plotlyのグラフでデフォルトで有効になっています。
ここでは、これらの機能をカスタマイズする方法を紹介します。
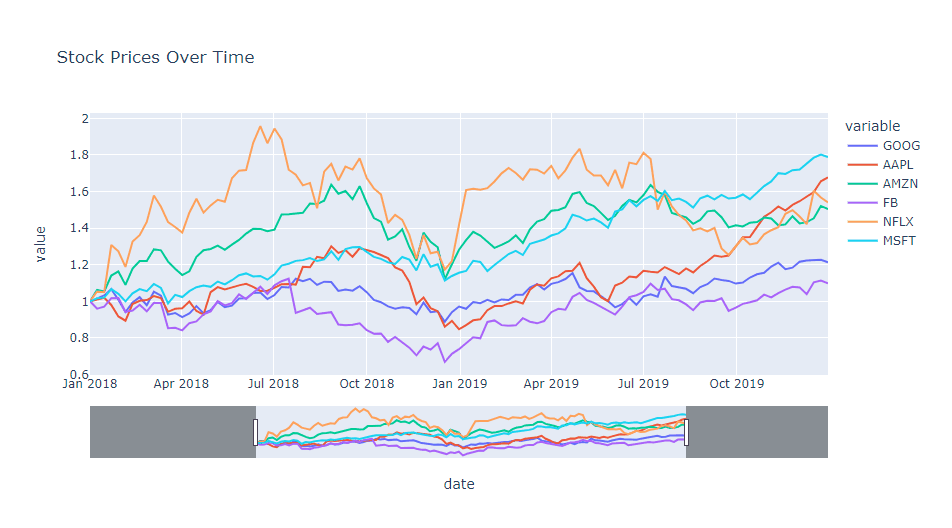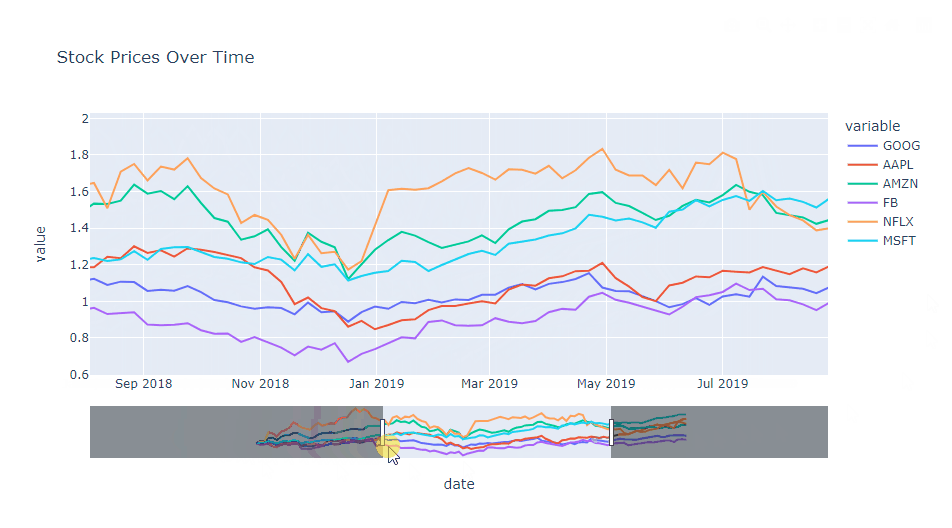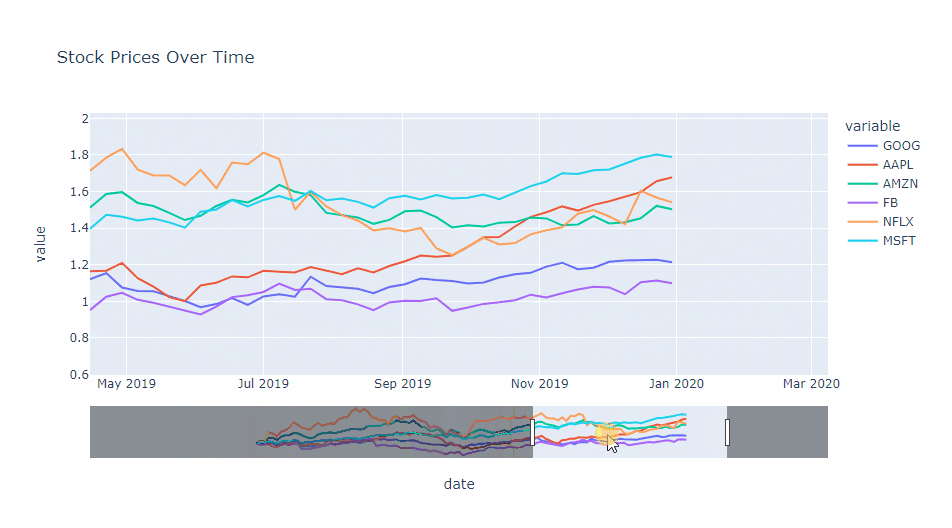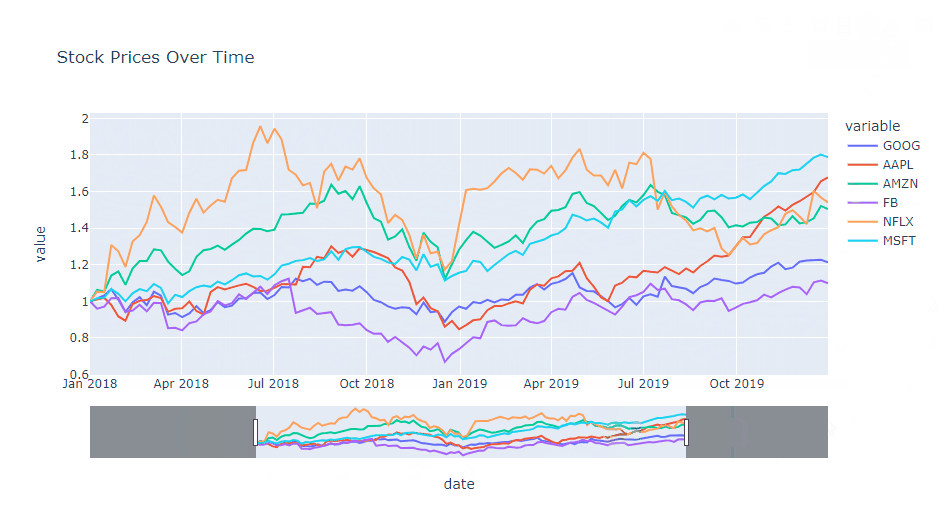
x軸にレンジスライダーを追加し、デフォルトの操作モードをパンに設定します。これでユーザーは簡単に表示範囲を変更できます。
以下、コードです。
import plotly.express as px
# サンプルデータの作成
df = px.data.stocks()
# 折れ線グラフの作成
fig = px.line(
df,
x='date',
y=['GOOG', 'AAPL', 'AMZN', 'FB', 'NFLX', 'MSFT'],
title='Stock Prices Over Time')
# ズームとパンの設定
fig.update_layout(
xaxis=dict(
rangeslider=dict(visible=True), # x軸にレンジスライダーを追加
type="date"), # x軸を日付型に設定
dragmode="pan", # デフォルトの操作モードをパンに設定
)
fig.show()
以下、実行結果です。
ホバー情報の設定
ホバー情報は、データポイントにマウスを乗せたときに表示される追加情報です。
これをカスタマイズすることで、より豊富な情報を提供できます。
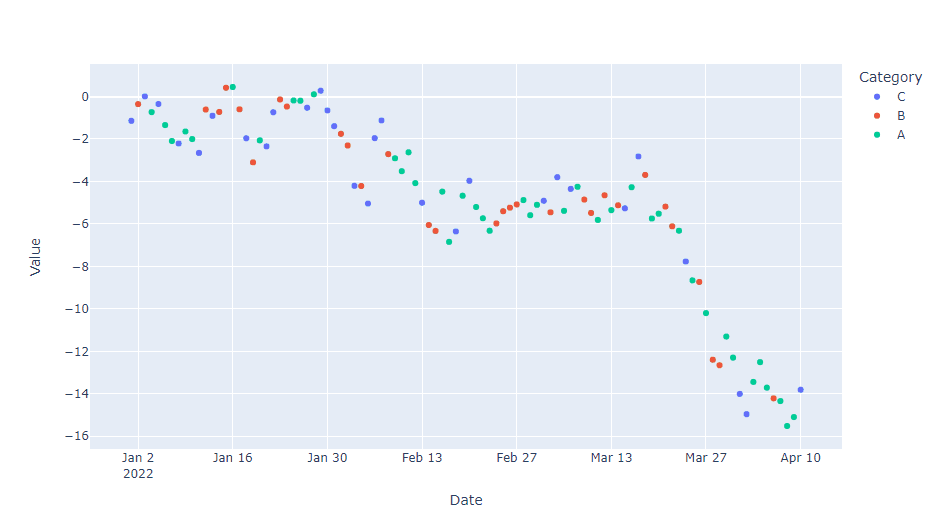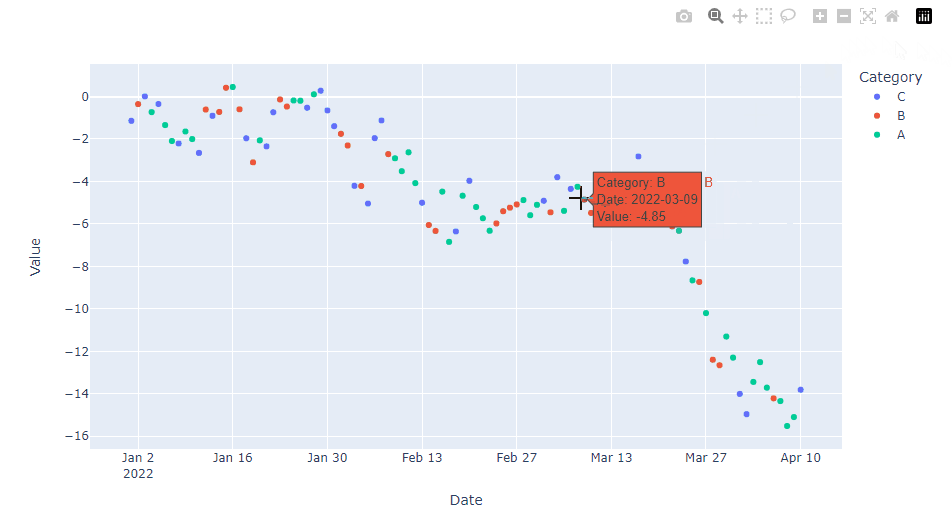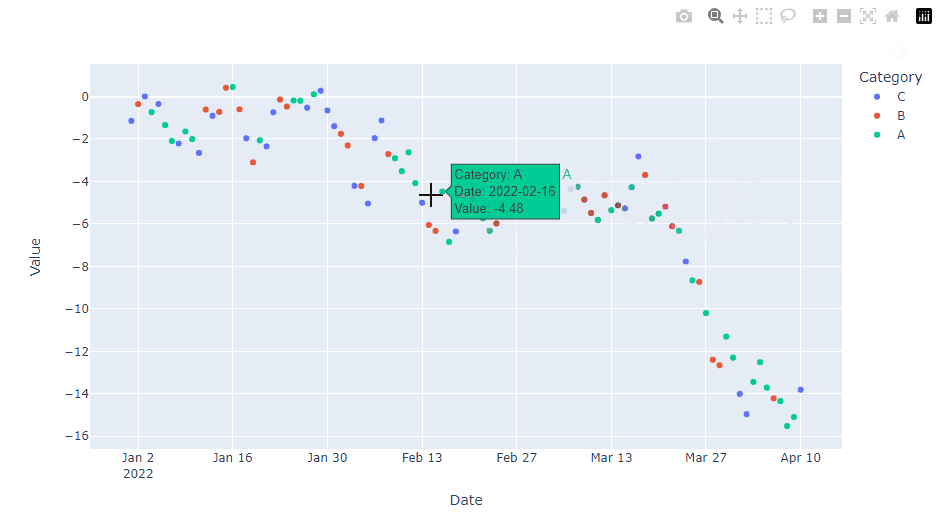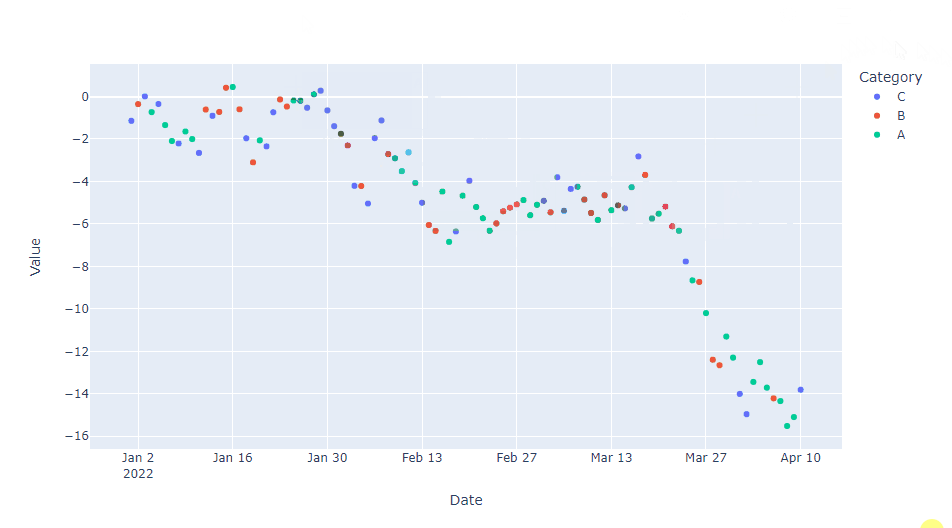
hover_dataパラメータを使用しホバー情報を選択し、hovertemplateでその表示形式のカスタマイズをします。hover_dataパラメータのみでも、ある程度のカスタマイズはできます。
以下、コードです。
import plotly.express as px
import pandas as pd
import numpy as np
# サンプルデータの作成
df = pd.DataFrame({
'Date': pd.date_range(start='2022-01-01', periods=100),
'Value': np.random.randn(100).cumsum(),
'Category': np.random.choice(['A', 'B', 'C'], 100)
})
# 散布図の作成
fig = px.scatter(
df,
x='Date',
y='Value',
color='Category',
hover_data={
'Date': True,
'Value': True,
'Category': True},
custom_data=['Date', 'Value', 'Category']
)
# update_tracesでhovertemplateをカスタマイズ
fig.update_traces(hovertemplate="<br>".join([
"Category: %{customdata[2]}",
"Date: %{customdata[0]|%Y-%m-%d}",
"Value: %{customdata[1]:.2f}"
]))
fig.show()
以下、実行結果です。
アニメーションコントロール
時系列データや複数のカテゴリを持つデータでは、アニメーションを使用することで時間の経過や変化を効果的に表現できます。
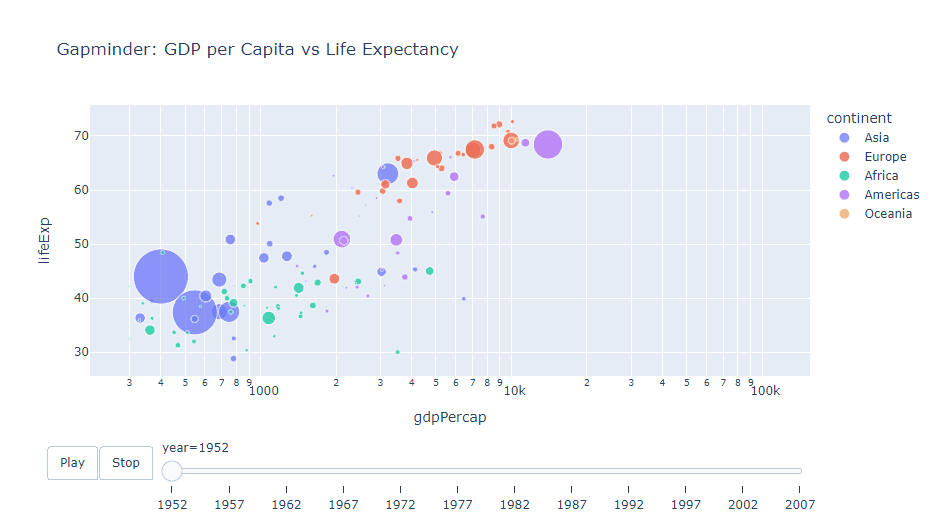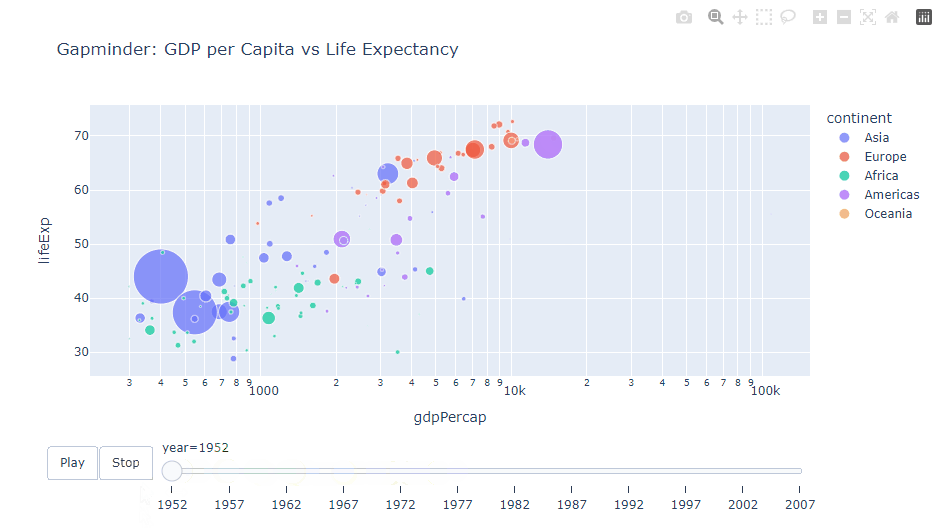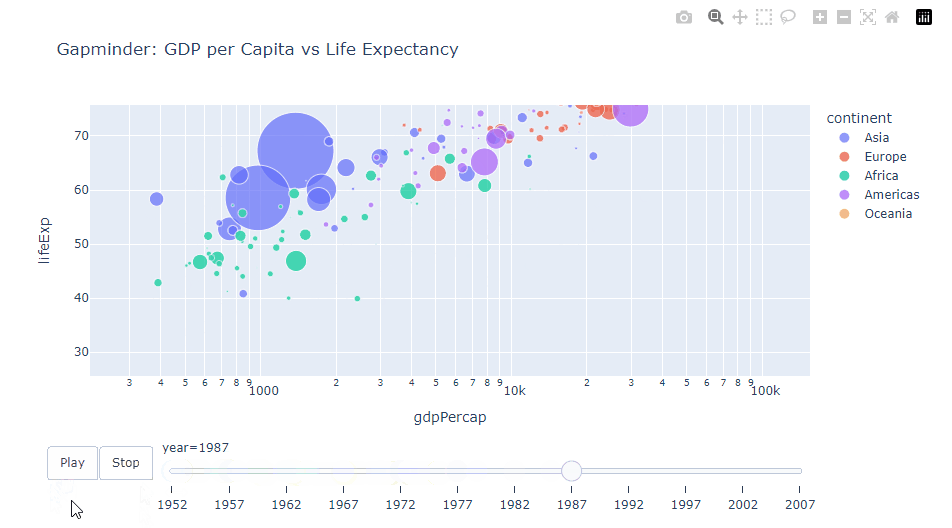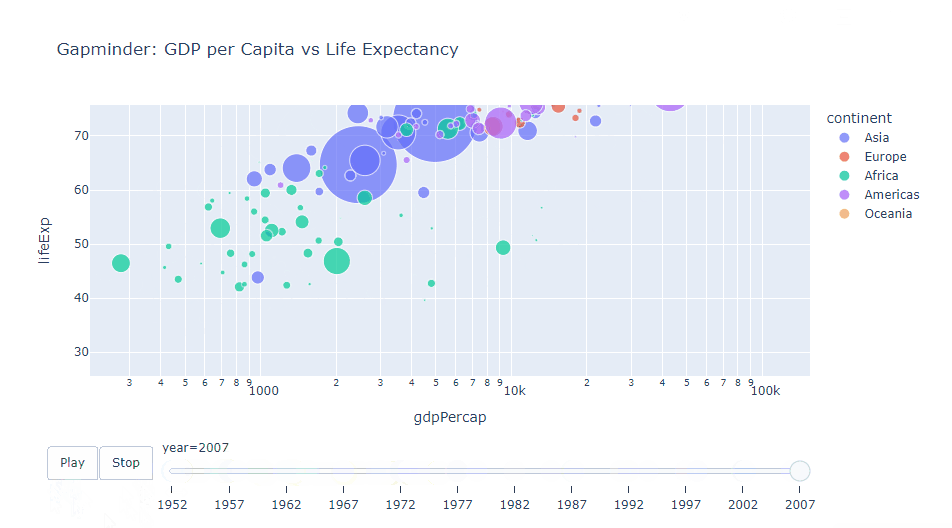
年ごとのGDPと平均寿命の関係を示すアニメーション付き散布図を作成します。ユーザーは再生ボタンを使ってアニメーションを制御できます。
以下、コードです。
import plotly.express as px
# Gapminder データセットの読み込み
df = px.data.gapminder()
# アニメーション付き散布図の作成
fig = px.scatter(
df,
x="gdpPercap",
y="lifeExp",
size="pop",
color="continent",
hover_name="country",
log_x=True,
size_max=60,
animation_frame="year",
animation_group="country",
title="Gapminder: GDP per Capita vs Life Expectancy")
# アニメーションの設定
fig.update_layout(
updatemenus=[
dict(type='buttons',showactive=False,
buttons=[
dict(label='Play',
method='animate',
args=[
None, {
'frame': {'duration': 500, 'redraw': True},
'fromcurrent': True,
'transition': {'duration': 300,
'easing': 'quadratic-in-out'},
'mode': 'immediate'}]),
dict(label='Stop',
method='animate',
args=[
[None], {
'frame': {'duration': 0, 'redraw': False},
'mode': 'immediate',
'transition': {'duration': 0}}])
])
])
fig.show()
以下、実行結果です。
統計的可視化
データの統計的特性を視覚化することは、データ分析において非常に重要です。
plotlyは、データの分布や関係性を効果的に表現するための様々なツールを提供しています。
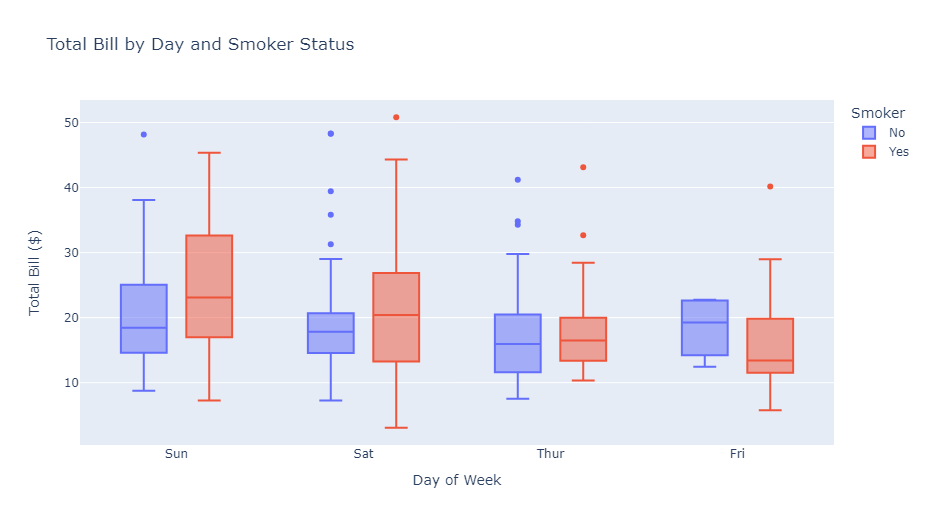
箱ひげ図(Box plots)
箱ひげ図は、データの分布を要約的に表現するのに適しています。中央値、四分位数、外れ値などの情報を一度に表示できます。
チップのデータセットを使用して、曜日ごとの請求額の分布を喫煙者と非喫煙者で比較します。箱ひげ図は、各グループのデータの中央値、四分位範囲、外れ値を明確に示しています。
以下、コードです。
import plotly.express as px
# レストランのチップに関するデータセットの読み込み
df = px.data.tips()
# 箱ひげ図の作成
fig = px.box(
df,
x="day",
y="total_bill",
color="smoker",
title="Total Bill by Day and Smoker Status",
labels={
"total_bill": "Total Bill ($)",
"day": "Day of Week",
"smoker": "Smoker"})
fig.show()
以下、実行結果です。
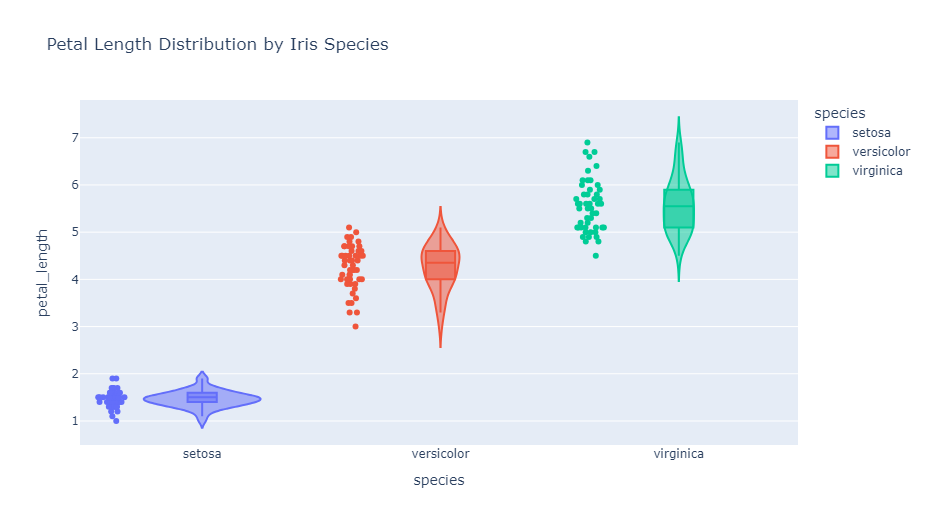
バイオリンプロット(Violin plots)
バイオリンプロットは、箱ひげ図の情報に加えて、データの確率密度も表現します。これにより、データの分布の形状をより詳細に観察できます。
アイリスデータセットを使用して、品種ごとの花弁の長さの分布を示します。box=Trueオプションにより、箱ひげ図も同時に表示しています。また、points="all"により、個々のデータポイントも表示しています。
以下、コードです。
import plotly.express as px
# アイリスデータセットの読み込み
df = px.data.iris()
# バイオリンプロットの作成
fig = px.violin(
df,
y="petal_length",
x="species",
color="species",
box=True,
points="all",
hover_data=df.columns,
title="Petal Length Distribution by Iris Species")
fig.show()
以下、実行結果です。
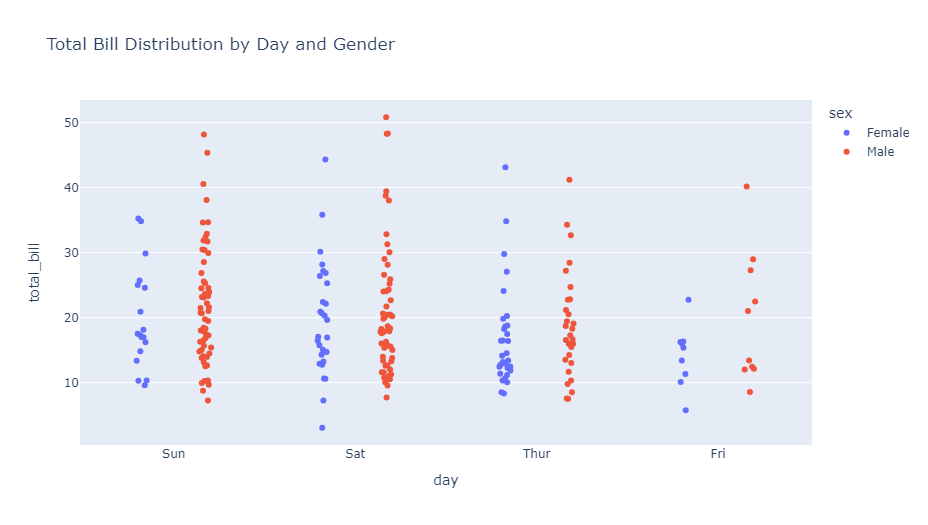
スウォームプロット(Swarm plots)
スウォームプロットは、カテゴリカルデータの分布を個々のポイントで表現する手法です。重なりを避けるようにポイントが配置されるため、データの密度も視覚的に理解できます。
チップのデータセットを使用して、曜日ごとの請求額の分布を性別で色分けして表示します。各ポイントは個々の請求額を表しており、ポイントの密度から分布の特徴を読み取ることができます。
以下、コードです。
import plotly.express as px
import numpy as np
# レストランのチップに関するデータセットの読み込み
df = px.data.tips()
# スウォームプロットの作成
fig = px.strip(
df,
x="day",
y="total_bill",
color="sex",
title="Total Bill Distribution by Day and Gender")
fig.show()
以下、実行結果です。
複合的な統計プロット
これらの統計的プロットは、組み合わせることでより豊富な情報を提供できます。
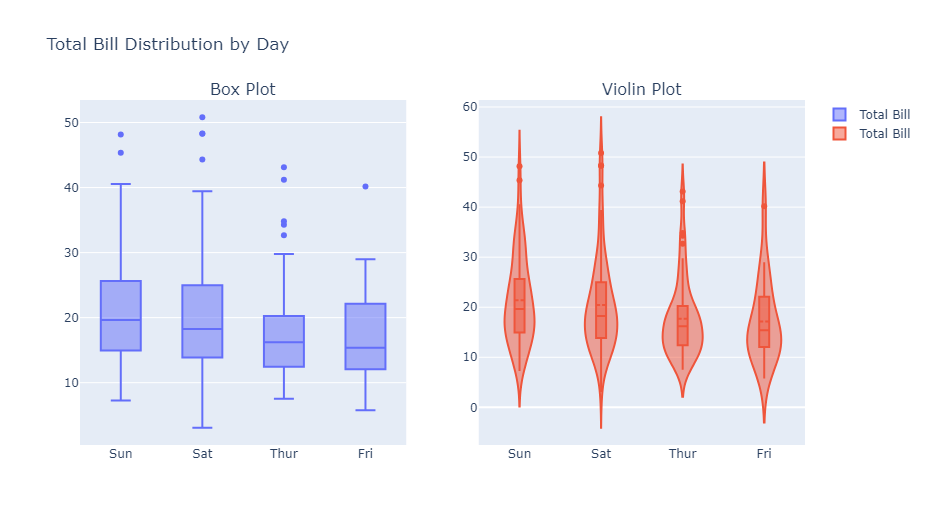
箱ひげ図とバイオリンプロットを組み合わせてみます。
以下、コードです。
import plotly.express as px
import numpy as np
# レストランのチップに関するデータセットの読み込み
df = px.data.tips()
# スウォームプロットの作成
fig = px.strip(
df,
x="day",
y="total_bill",
color="sex",
title="Total Bill Distribution by Day and Gender")
fig.show()
以下、実行結果です。
まとめ
今回は、plotlyを使用したデータ可視化の基礎的な内容をお話ししました。
準備(ライブラリのインストールなど)から始まり、基本的なプロットの作成、インタラクティブ機能の活用、そして基本的な統計的可視化までをカバーしました。
折れ線グラフ、散布図、棒グラフなどの基本的なグラフの作成方法を習得し、ズーム、パン、ホバー情報、クリックイベント、アニメーションなどのインタラクティブ機能を実装する技術などです。
さらに、箱ひげ図、バイオリンプロット、スウォームプロットなどの統計的可視化手法を用いてデータの分布や関係性を効果的に表現する方法をお話ししました。
これらだけでも十分ですが、次回以降は、さらに高度な可視化テクニックについてお話しします。
例えば、3D可視化などの空間的な関係性の視覚化、地図上にデータをマッピングし位置情報を含むデータの傾向を探るための可視化、複合グラフとサブプロットによる異なるタイプのグラフを組み合わせの表現方法に触れる予定です。
これらの技術を習得することで、より豊かで洞察に満ちたデータストーリーを語る能力が向上し、データサイエンティストやアナリストとしてのスキルセットがさらに強化されるでしょう。