
データ分析や機械学習の現場では、量的(数値)データと質的(カテゴリ)データが混在することが多々あります。
このようなデータを効果的にクラスタリングする方法として、k-プロトタイプ法が注目されています。
k-プロトタイプ法は、k-means法とk-modes法の良いところを組み合わせた手法で、量的データと質的データを同時に処理できるため、ビジネスやマーケティング、顧客セグメンテーションなど幅広い分野で活用されています。
Contents [hide]
- はじめに
- クラスタリングの基本
- クラスタリングとは?
- 量的データと質的データの違い
- k-プロトタイプ法の概要
- k-プロトタイプ法とは?
- k-プロトタイプ法のアルゴリズム
- k-プロトタイプ法のメリット
- k-プロトタイプ法の限界
- Pythonでのk-プロトタイプ法の実施手順
- 必要なライブラリのインストール
- データセットの準備と前処理
- k-プロトタイプ法の実装
- k-プロトタイプ法の結果の解釈
- KPrototypesの諸設定の説明
- 主要な設定項目
- n_clusters
- init
- max_iter
- n_init
- gamma
- verbose
- random_state
- 設定例
- 設定例1: 基本的なクラスタリング
- 設定例2: 初期条件に依存しない安定した結果を得たい場合
- 設定例3: 質的データの影響を強調したい場合
- 設定例4: 再現性を重視したい場合
- 設定例5: 複雑なデータに対してより多くのイテレーションを設定
- 適用事例
- 事例1 顧客セグメンテーション
- 事例2 マーケットバスケット分析
- 事例3 営業リードマッチング
- まとめ
はじめに
データ分析や機械学習の分野では、データを有効に活用するための技術が日々進化しています。
その中でも「クラスタリング」と呼ばれる手法は、データの中に隠れたパターンやグループを発見するための強力なツールとして知られています。
特に、ビジネスやマーケティング分野では、顧客をセグメント化して、ターゲットごとに異なる戦略を立てるためにクラスタリングが広く使われています。
しかし、実際のデータには、数値で表される「量的データ」と、カテゴリやラベルで表される「質的データ」が混在していることが一般的です。
このようなデータを扱う際、単純なk-meansクラスタリングなどでは十分に対応できないことがあります。そこで活躍するのが「k-プロトタイプ法」です。
k-プロトタイプ法は、量的データに適したk-means法と、質的データに適したk-modes法を組み合わせたクラスタリング手法です。
この手法を使うことで、量的・質的データの両方を考慮したクラスタリングが可能になり、より現実的で実用的な結果を得ることができます。
クラスタリングの基本
クラスタリングとは、データセットの中から似たような特徴を持つデータをグループ化(クラスタリング)する手法のことを指します。
クラスタリングは、教師なし学習の一種で、あらかじめ定義されたラベルや答えがないデータに対して行われるため、どのようなパターンやグループがデータ内に存在するのかを探索する際に有効です。
クラスタリングとは?
クラスタリングは、データをいくつかのグループ(クラスタ)に分け、それぞれのクラスタ内のデータが他のクラスタ内のデータよりも互いに似ているようにするプロセスです。
これにより、データの背後に潜む構造を明らかにすることができます。
クラスタリングにはさまざまなアルゴリズムがありますが、代表的なものには以下のようなものがあります。
k-meansクラスタリング
- データをあらかじめ指定した数のクラスタに分割します。
- それぞれのクラスタの中心を計算し、その中心に最も近いデータポイントをそのクラスタに割り当てるというプロセスを繰り返します。
- 量的データに適しており、シンプルで効率的なアルゴリズムです。
階層的クラスタリング
- データポイントを階層的にクラスタリングしていく手法で、デンドログラムと呼ばれる木構造を用いて視覚的に表現されます。
- データが少ない場合に有効で、クラスタ数を事前に指定する必要がありません。
DBSCAN
- 密度に基づいたクラスタリング手法で、異常値やノイズが含まれるデータセットに適しています。
- クラスタ数を指定せずに、データの密度によってクラスタを形成します。
量的データと質的データの違い
クラスタリングを行う際に考慮すべき重要な点は、データの種類です。
データには、量的データと質的データの2種類があります。
量的データ
- 数値で表現され、測定可能なデータです。
- 例としては、年齢、収入、身長、体重などが挙げられます。
- これらのデータは連続的であり、一般的にユークリッド距離などの距離測定法を用いて類似度を評価します。
質的データ
- カテゴリデータとも呼ばれ、名前やラベルで表現されるデータです。
- 例としては、性別、職業、地域、顧客カテゴリなどが挙げられます。
- これらのデータは順序がなく、一般的には一致・不一致の基準で類似度を評価します。
量的データと質的データの両方が混在しているデータセットをクラスタリングする際には、それぞれの特性に適した方法を用いる必要があります。
量的データにはk-meansクラスタリングが適していますが、質的データには適用できません。
逆に、質的データにはk-modesクラスタリングが適していますが、量的データには対応できません。
ここで登場するのが「k-プロトタイプ法」です。
k-プロトタイプ法の概要
k-プロトタイプ法とは?
k-プロトタイプ法は、量的データと質的データを同時にクラスタリングするための手法です。
これは、k-meansクラスタリングとk-modesクラスタリングのアイデアを組み合わせたものです。
具体的には、k-meansの手法を用いて量的データをクラスタリングし、k-modesの手法を用いて質的データをクラスタリングします。
この手法の大きな特徴は、量的データと質的データの両方を扱うことができる点にあります。
これにより、現実のビジネスデータなど、さまざまな種類のデータが混在する状況でも、適切にクラスタリングを行うことが可能になります。
k-プロトタイプ法のアルゴリズム
以下は、k-プロトタイプ法の手順です。
Step 1 初期プロトタイプの選定
- 最初に、k個のプロトタイプ(クラスタの中心点)をランダムに選びます。
- このプロトタイプは、量的データに対しては平均値で、質的データに対しては最頻値(モード)で構成されます。
Step 2 データポイントの割り当て
- 各データポイントについて、最も近いプロトタイプに割り当てます。
- 距離の計算は、量的データにはユークリッド距離、質的データには一致・不一致のカウントを使用します。
Step 3 プロトタイプの更新
- 各クラスタに割り当てられたデータポイントに基づいて、プロトタイプを更新します。
- 量的データのプロトタイプは各クラスタの平均値、質的データのプロトタイプは各クラスタの最頻値(モード)として再計算されます。
Step 4 収束の確認
- プロトタイプの更新が一定の閾値以下になったとき、あるいは指定した回数のイテレーションを終えたときに、アルゴリズムを停止します。
このプロセスを繰り返すことで、量的データと質的データの両方を考慮した最適なクラスタが得られます。
k-プロトタイプ法のメリット
k-プロトタイプ法は、量的データと質的データの両方を同時に処理できるため、現実の多くのデータセットに適用可能です。
また、k-meansやk-modesと同様に、アルゴリズム自体は比較的シンプルで直感的に理解できます。
k-プロトタイプ法の限界
k-プロトタイプ法も、他のk-means系アルゴリズムと同様に、クラスタ数を事前に指定する必要があります。
しかし、初期プロトタイプの選定が結果に大きく影響する可能性があります。初期値をランダムに選ぶため、結果が安定しない場合があります。
また、質的データの距離計算が一致・不一致に基づいているため、質的データが過度にクラスタリング結果に影響を与えないように、または逆に適切に反映されるように重み付けを行う場合があります。
Pythonでのk-プロトタイプ法の実施手順
必要なライブラリのインストール
まず、k-プロトタイプ法を実装するために必要なPythonライブラリをインストールします。
k-プロトタイプ法をサポートする kmodes ライブラリを使用します。
以下、kmodes ライブラリをpipでインストールするときのコード例です。
pip install kmodes
データセットの準備と前処理
次に、サンプルデータを準備し、クラスタリングの前処理を行います。
今回使用するデータセットは、仮の小売業者の顧客データです。このデータセットには、以下のような量的データと質的データが含まれています。
量的データ
- 年齢(Age)
- 年間購入額(Annual Spend)
- Webサイト訪問頻度(Visit Frequency)
質的データ
- 性別(Gender)
- 地域(Region)
- メンバーシップステータス(Membership Status)
以下、コードです。
import pandas as pd
data = {
'Age': [23, 45, 31, 35, 40, 52, 30, 28, 50, 33],
'Annual Spend': [500, 1500, 1000, 1200, 1400, 1600, 1100, 800, 1700, 1300],
'Visit Frequency': [5, 20, 15, 18, 22, 24, 19, 10, 25, 17],
'Gender': ['Male', 'Female', 'Female', 'Male', 'Female', 'Male', 'Female', 'Male', 'Male', 'Female'],
'Region': ['Urban', 'Suburban', 'Urban', 'Rural', 'Suburban', 'Rural', 'Urban', 'Suburban', 'Rural', 'Urban'],
'Membership Status': ['Gold', 'Silver', 'Gold', 'Bronze', 'Gold', 'Silver', 'Bronze', 'Gold', 'Bronze', 'Silver']
}
df = pd.DataFrame(data)
print(df)
以下、実行結果です。
Age Annual Spend Visit Frequency Gender Region Membership Status 0 23 500 5 Male Urban Gold 1 45 1500 20 Female Suburban Silver 2 31 1000 15 Female Urban Gold 3 35 1200 18 Male Rural Bronze 4 40 1400 22 Female Suburban Gold 5 52 1600 24 Male Rural Silver 6 30 1100 19 Female Urban Bronze 7 28 800 10 Male Suburban Gold 8 50 1700 25 Male Rural Bronze 9 33 1300 17 Female Urban Silver
k-プロトタイプ法の実装
kmodes ライブラリを使ってk-プロトタイプ法を実装します。
まず、質的データを数字にエンコードします。
これが必要なのは、k-プロトタイプ法が数字データで動作するためです。
以下、コードです。
from sklearn.preprocessing import LabelEncoder # ラベルエンコーディング le_gender = LabelEncoder() le_region = LabelEncoder() le_membership = LabelEncoder() df['Gender'] = le_gender.fit_transform(df['Gender']) df['Region'] = le_region.fit_transform(df['Region']) df['Membership Status'] = le_membership.fit_transform(df['Membership Status']) print(df)
以下、実行結果です。
Age Annual Spend Visit Frequency Gender Region Membership Status 0 23 500 5 1 2 1 1 45 1500 20 0 1 2 2 31 1000 15 0 2 1 3 35 1200 18 1 0 0 4 40 1400 22 0 1 1 5 52 1600 24 1 0 2 6 30 1100 19 0 2 0 7 28 800 10 1 1 1 8 50 1700 25 1 0 0 9 33 1300 17 0 2 2
エンコードされた質的変数の、数字とラベルの対応表を出力します。
以下、コードです。
# 質的変数の数字とラベルの対応表
print("質的変数の数字とラベルの対応表:")
print("Gender:", dict(zip(le_gender.classes_, le_gender.transform(le_gender.classes_))))
print("Region:", dict(zip(le_region.classes_, le_region.transform(le_region.classes_))))
print("Membership Status:", dict(zip(le_membership.classes_, le_membership.transform(le_membership.classes_))))
以下、実行結果です。
質的変数の数字とラベルの対応表:
Gender: {'Female': 0, 'Male': 1}
Region: {'Rural': 0, 'Suburban': 1, 'Urban': 2}
Membership Status: {'Bronze': 0, 'Gold': 1, 'Silver': 2}
k-プロトタイプ法でクラスタリングを実施します。
以下、コードです。
from kmodes.kprototypes import KPrototypes # k-プロトタイプ法の実行 kproto = KPrototypes(n_clusters=3, init='Cao') clusters = kproto.fit_predict(df, categorical=[3, 4, 5]) # クラスタリング結果をデータフレームに追加 df['Cluster'] = clusters print(df)
以下、実行結果です。
Age Annual Spend Visit Frequency Gender Region Membership Status \ 0 23 500 5 1 2 1 1 45 1500 20 0 1 2 2 31 1000 15 0 2 1 3 35 1200 18 1 0 0 4 40 1400 22 0 1 1 5 52 1600 24 1 0 2 6 30 1100 19 0 2 0 7 28 800 10 1 1 1 8 50 1700 25 1 0 0 9 33 1300 17 0 2 2 Cluster 0 2 1 0 2 1 3 1 4 0 5 0 6 1 7 2 8 0 9 1
クラスタ 列が追加され、各顧客がどのクラスタに属しているかが示されます。
この例では、3つのクラスタに分類されています。
k-プロトタイプ法の結果の解釈
クラスタリングの結果として得られる各クラスタは、共通の特徴を持つデータポイント(顧客やアイテムなど)で構成されています。
まず、各クラスタがどのような特徴を持っているのかを理解することが重要です。
先ほど実施したクラスタリングの結果を使って、各クラスタの特徴を確認します。
以下、コードです。
# 量的変数
num_var = ['Age', 'Annual Spend', 'Visit Frequency']
# 質的変数
cate_var = ['Gender', 'Region', 'Membership Status']
# 各クラスタの特徴を確認
for i in range(3):
print(f"クラスタ {i} の特徴:")
print("量的データの平均値:")
print(df[df['Cluster'] == i][num_var].mean())
print("\n質的データの最頻値:")
print(df[df['Cluster'] == i][cate_var].mode().iloc[0])
print("\n")
このコードは、各クラスタに属するデータポイントの量的データの平均値と、質的データの最頻値を表示します。これにより、各クラスタがどのような属性を持っているのかを把握できます。
以下、実行結果です。
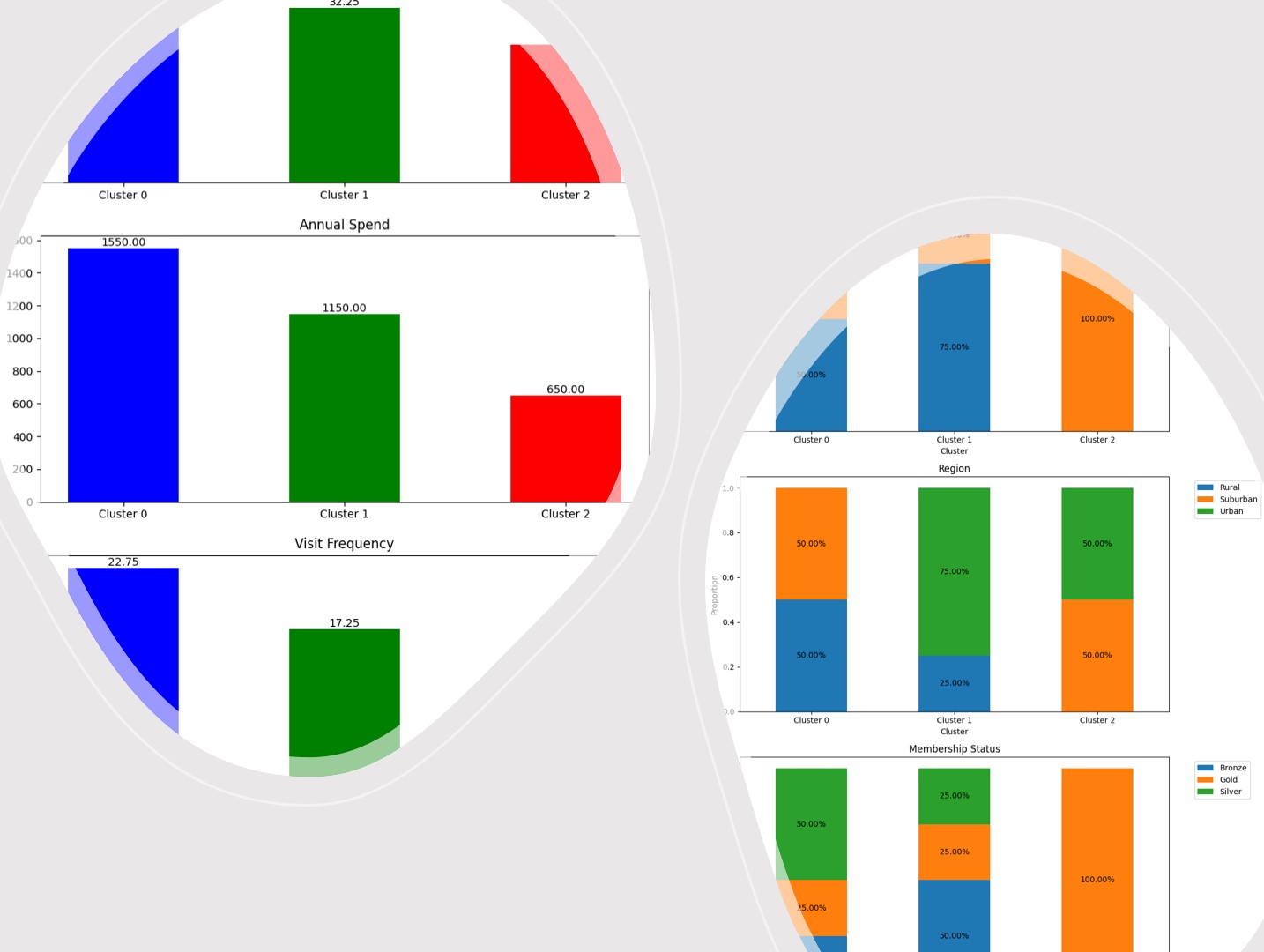
クラスタ 0 の特徴: 量的データの平均値: Age 46.75 Annual Spend 1550.00 Visit Frequency 22.75 dtype: float64 質的データの最頻値: Gender 0.0 Region 0.0 Membership Status 2.0 Name: 0, dtype: float64 クラスタ 1 の特徴: 量的データの平均値: Age 32.25 Annual Spend 1150.00 Visit Frequency 17.25 dtype: float64 質的データの最頻値: Gender 0 Region 2 Membership Status 0 Name: 0, dtype: int64 クラスタ 2 の特徴: 量的データの平均値: Age 25.5 Annual Spend 650.0 Visit Frequency 7.5 dtype: float64 質的データの最頻値: Gender 1.0 Region 1.0 Membership Status 1.0 Name: 0, dtype: float64
グラフ化して分かりやすくします。
まずは、量的変数のグラフ化(平均値の棒グラフ)です。
以下、コードです。
import matplotlib.pyplot as plt
import numpy as np
labels = num_var
# クラスタごとの色を定義
colors = ['b', 'g', 'r']
# 各クラスタの量的変数の平均値
cluster_averages = [
df[df['Cluster'] == i][num_var].mean().values for i in range(3)
]
fig, axes = plt.subplots(3, 1, figsize=(10, 15))
for idx, label in enumerate(labels):
for i in range(3): # クラスタ 0, 1, 2
bar = axes[idx].bar(i, cluster_averages[i][idx], color=colors[i], width=0.5)
axes[idx].text(i, bar[0].get_height(), f'{bar[0].get_height():.2f}', ha='center', va='bottom')
axes[idx].set_xticks(range(3))
axes[idx].set_xticklabels([f'Cluster {i}' for i in range(3)])
axes[idx].set_title(label)
plt.show()
以下、実行結果です。
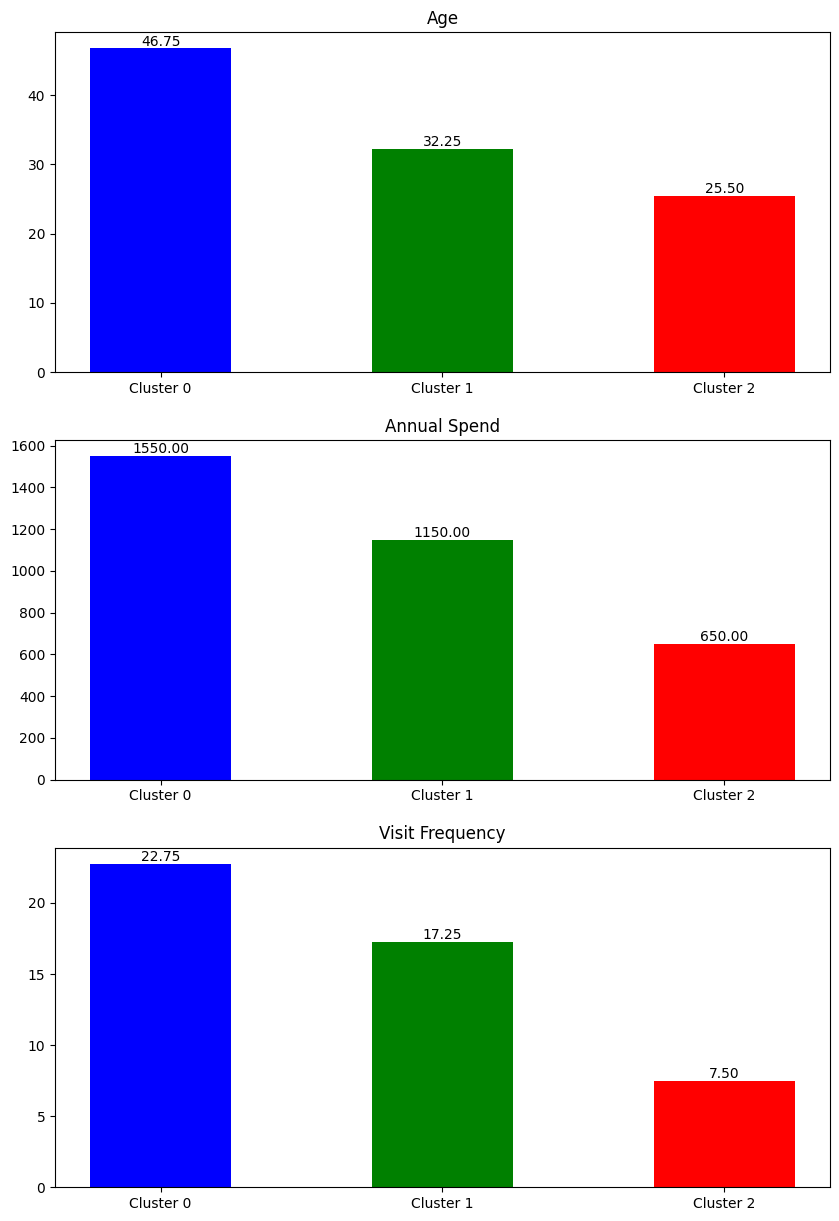
次に、質的変数のグラフ化(構成比の帯グラフ)です。
以下、コードです。
# 質的変数の構成比を棒グラフで表示
fig, axes = plt.subplots(3, 1, figsize=(10, 15))
legend_labels = {
'Gender': {v: k for k, v in dict(zip(le_gender.classes_, le_gender.transform(le_gender.classes_))).items()},
'Region': {v: k for k, v in dict(zip(le_region.classes_, le_region.transform(le_region.classes_))).items()},
'Membership Status': {v: k for k, v in dict(zip(le_membership.classes_, le_membership.transform(le_membership.classes_))).items()}
}
for i, var in enumerate(cate_var):
cluster_counts = df.groupby(['Cluster', var]).size().unstack().fillna(0)
cluster_counts = cluster_counts.div(cluster_counts.sum(axis=1), axis=0)
cluster_counts.plot(kind='bar', stacked=True, ax=axes[i], legend=False)
axes[i].set_title(var)
axes[i].set_ylabel('Proportion')
axes[i].set_xticklabels([f'Cluster {i}' for i in range(3)], rotation=0)
# 値を%で表示
for p in axes[i].patches:
width = p.get_width()
height = p.get_height()
if height > 0: # 0%の表示はしない
x, y = p.get_xy()
axes[i].text(x + width / 2, y + height / 2, f'{height:.2%}', ha='center', va='center')
# 凡例のラベルに質的変数の情報を追加
handles, labels = axes[i].get_legend_handles_labels()
labels = [legend_labels[var].get(int(label), label) for label in labels]
axes[i].legend(handles, labels, bbox_to_anchor=(1.05, 1), loc='upper left')
plt.tight_layout()
plt.show()
以下、実行結果です。
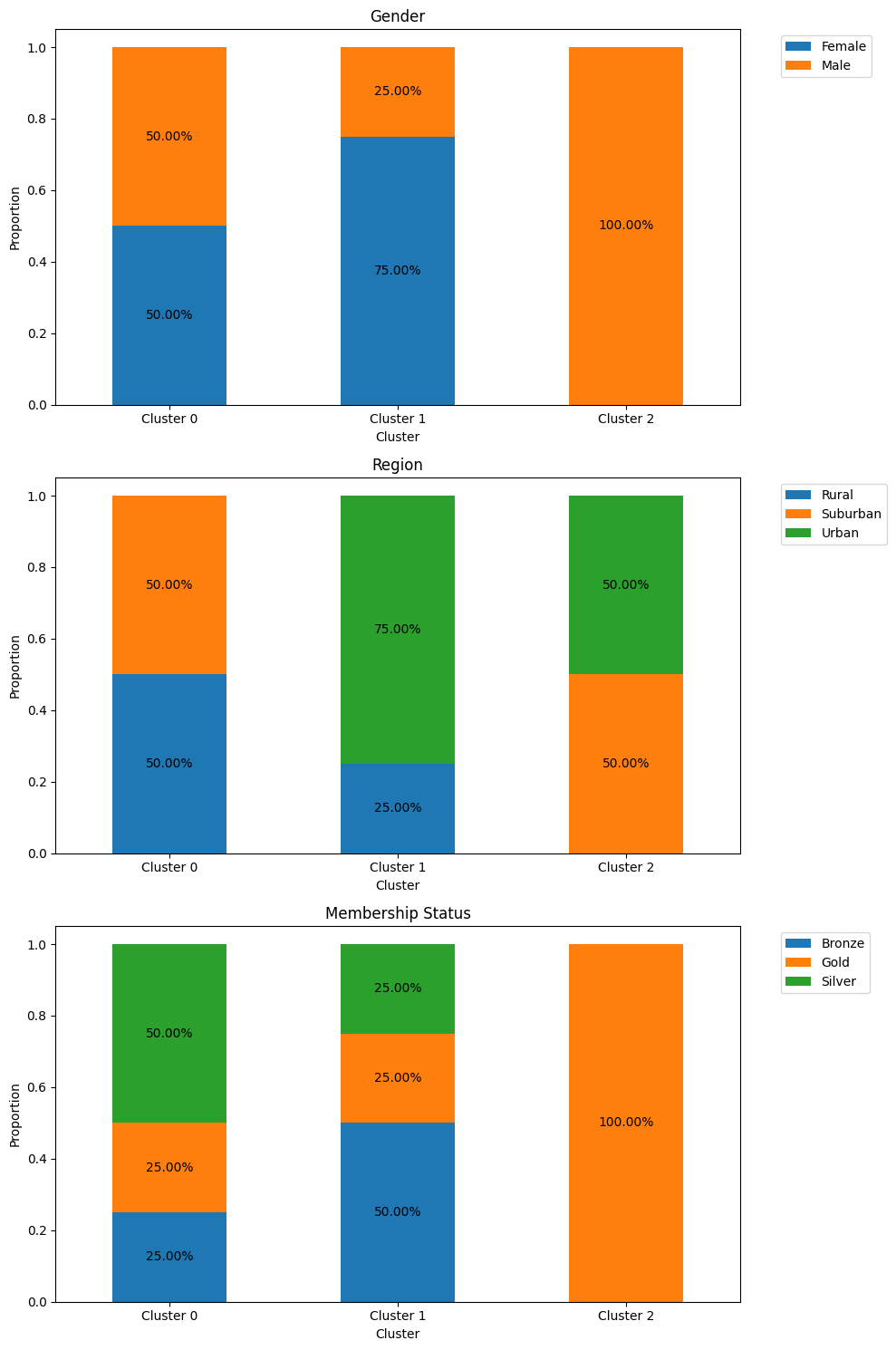
KPrototypesの諸設定の説明
k-プロトタイプ法を効果的に使うためには、KPrototypes クラスのさまざまな設定を理解しておくことが重要です。
主要な設定項目
KPrototypes の主要な設定項目について説明し、どのような場合にどの設定を調整すべきかを説明します。
n_clusters
n_clusters は、データをいくつのクラスタに分けるかを指定するパラメータです。デフォルト値は8です。
k-プロトタイプ法では、このパラメータに基づいてクラスタリングを行います。
一般的に、クラスタ数はドメイン知識や事前のデータ分析に基づいて決定します。
クラスタ数が多すぎると過学習のリスクが高まり、少なすぎると重要な情報が失われる可能性があります。
最適なクラスタ数を選ぶために、エルボー法やシルエットスコアなどの手法を使うと良いでしょう。
init
init パラメータは、初期のクラスタ中心(プロトタイプ)の選定方法を指定します。
k-プロトタイプ法は、初期のクラスタ中心の選定に依存するため、ここでの設定が重要です。デフォルト値は 'Cao'です。
'Huang': k-means法のようにランダムに選定する方法。最も基本的な手法です。'Cao': k-means++アルゴリズムのように、クラスタ中心をより効率的に選定する方法。'random': 完全にランダムにクラスタ中心を選定する方法。
より安定した結果を得るために、'Cao' を使用することが一般的です。
ただし、データの性質や目標によっては 'Huang' や 'random' を試す価値があります。
max_iter
max_iter は、クラスタリングアルゴリズムが収束するまでの最大イテレーション回数を指定します。デフォルト値は100です。
アルゴリズムがこの回数に達すると、収束していなくてもクラスタリングが停止します。
通常はデフォルトの設定で十分ですが、データが非常に複雑でクラスタリングが収束しにくい場合には、max_iter を増やすことが考えられます。
ただし、あまり大きくすると計算負荷が高くなるため、必要に応じて調整します。
n_init
n_init は、異なる初期条件でクラスタリングを複数回行い、その中で最も良い結果を採用する設定です。デフォルト値は10です。
これにより、局所的最適解に陥るリスクを軽減できます。
特に初期プロトタイプに依存しやすいデータセットでは、n_init の値を大きくすることで、より安定した結果を得ることができます。
gamma
gamma は、量的データと質的データの間のバランスを調整するためのパラメータです。
このパラメータが高いほど、質的データの影響が強くなります。
- 低い値 (
gamma ≪ 1): 量的データがクラスタリングにおいて支配的な要素となります。質的データの影響が減少し、量的データに基づいてクラスタが形成されやすくなります。 - 標準的な値 (
gamma ≈ 1): 量的データと質的データがバランスよく考慮され、どちらもクラスタ形成に影響を与えます。 - 高い値 (
gamma ≫ 1): 質的データがクラスタリングにおいて支配的な要素となります。質的データの不一致がクラスタの分割に大きく影響し、量的データの影響が相対的に小さくなります。
デフォルトでは、gamma の値は以下のように自動計算されます。
デフォルトの自動計算で十分な場合が多いですが、特定のデータセットで量的データまたは質的データの重要度を強調したい場合には、このパラメータを手動で調整します。
例えば、質的データが非常に重要な要素である場合には、gamma の値を高く設定します。
verbose
verbose は、クラスタリングの進行状況や詳細な情報を出力するかどうかを制御する設定です。
- 0(無効)
- 1(基本情報を出力)
- 2(詳細な情報を出力)
デフォルトでは出力(0)が無効になっていますが、クラスタリングの詳細な進行状況を確認したい場合には、1や2に設定すると良いでしょう。
特に初めてクラスタリングを行う場合や、アルゴリズムの動作を理解したい場合に役立ちます。
random_state
random_state は、ランダム要素が関与するプロセスに対してシード値を設定することで、結果の再現性を確保するためのパラメータです。
実験の結果を再現可能にしたい場合には、特定の数値を random_state に設定します。
これにより、同じデータセットと設定を使った場合、常に同じクラスタリング結果が得られます。
設定例
ここでは、KPrototypes の設定例を示します。
設定例1: 基本的なクラスタリング
最も一般的な設定で、デフォルトのパラメータを使用しつつ、クラスタ数だけを指定する場合です。
# 基本的な設定例 kproto = KPrototypes(n_clusters=3, init='Cao', verbose=0)
- n_clusters: 3つのクラスタに分類
- init: デフォルトの
Caoを使用 - verbose: 出力を表示しない
設定例2: 初期条件に依存しない安定した結果を得たい場合
複数回のクラスタリングを行い、最良の結果を選びたい場合の設定です。
# 安定した結果を得るための設定例 kproto = KPrototypes(n_clusters=4, init='Huang', n_init=10, verbose=1)
- n_clusters: 4つのクラスタに分類
- init:
Huangを使用(初期中心の選定をランダムに) - n_init: 10回のクラスタリングを実行し、最良の結果を採用
- verbose: 基本情報を表示
設定例3: 質的データの影響を強調したい場合
質的データが特に重要な場合に、gamma を調整して質的データの影響を強めます。
# 質的データの影響を強調する設定例 kproto = KPrototypes(n_clusters=3, init='Cao', gamma=2, verbose=1)
- n_clusters: 3つのクラスタに分類
- init:
Caoを使用(デフォルト) - gamma: 2に設定し、質的データの影響を強調
- verbose: 基本情報を表示
設定例4: 再現性を重視したい場合
クラスタリング結果を再現可能にするために random_state を設定します。
# 再現性を重視する設定例 kproto = KPrototypes(n_clusters=4, init='Cao', random_state=42, verbose=2)
- n_clusters: 4つのクラスタに分類
- init:
Caoを使用(デフォルト) - random_state: 42に設定し、結果の再現性を確保
- verbose: 詳細な情報を表示
設定例5: 複雑なデータに対してより多くのイテレーションを設定
複雑なデータに対して収束しやすくするために、最大イテレーション数を増やします。
# 複雑なデータに対する設定例 kproto = KPrototypes(n_clusters=5, init='Cao', max_iter=200, verbose=1)
- n_clusters: 5つのクラスタに分類
- init:
Caoを使用(デフォルト) - max_iter: 200に設定し、収束しやすくする
- verbose: 基本情報を表示
適用事例
事例1 顧客セグメンテーション
顧客セグメンテーションは、マーケティング戦略を最適化するために、顧客を特定の属性に基づいてグループ化するプロセスです。
一般的に、顧客データには数値で表される量的データ(年齢、収入、購買頻度など)と、カテゴリやラベルで表される質的データ(性別、居住地、職業など)が含まれます。
k-プロトタイプ法を使用することで、これらの量的データと質的データの両方を同時に考慮したクラスタリングが可能になります。
たとえば、次のような属性を持つ顧客データがあるとします。
- 量的データ: 年齢、年間購買金額、Webサイト訪問回数
- 質的データ: 性別、居住地(都市/地方)、会員ステータス(ゴールド/シルバー/ブロンズ)
k-プロトタイプ法を用いることで、これらの異なる種類のデータを一つのモデルで処理し、顧客をいくつかのセグメントに分類することができます。
このセグメントに基づいて、マーケティングチームはセグメントごとに異なるプロモーション戦略を立てたり、商品提案をパーソナライズしたりすることができます。
たとえば、「高収入で都市部在住のゴールド会員」というセグメントに対しては、高級な商品やサービスを提案する戦略が有効かもしれません。
これにより、よりターゲットを絞ったマーケティング活動が可能になり、顧客満足度やリピート率の向上が期待されます。
事例2 マーケットバスケット分析
マーケットバスケット分析は、顧客が購入する商品の組み合わせパターンを分析し、関連商品の推奨や陳列の最適化に活用する手法です。
購入履歴には、商品の価格や数量といった量的データと、商品のカテゴリやブランドといった質的データが含まれています。
例えば、以下のような属性を持つ購買データを考えます。
- 量的データ: 購入金額、購入回数、割引率
- 質的データ: 商品カテゴリ(食品/衣料品/家電)、ブランド名、購入日(平日/週末)
k-プロトタイプ法を使ってこれらのデータをクラスタリングすることで、類似した購買パターンを持つ顧客グループを特定できます。
たとえば、「週末に食品を頻繁に購入するが、家電製品は平日に購入する」という顧客グループが存在するかもしれません。
このようなクラスタリング結果を基に、特定の顧客グループに対してクロスセル(関連商品を一緒に購入させる)やアップセル(より高価な商品を推奨する)の機会を見出し、販売戦略を最適化できます。
これにより、平均購入額の増加や顧客ロイヤルティの向上が期待できます。
事例3 営業リードマッチング
営業リードマッチングとは、営業活動を行う際に、見込み顧客(リード)を最も適切な営業アプローチ(お勧めする商材や営業方法など)でターゲティングするための手法です。
企業が既に保有している既存顧客のデータを基に、似たような属性を持つ新しいリードを識別し、適切な営業戦略を展開することが目的です。
例えば、ある企業の既存顧客データには次のような属性が含まれているとします。
- 量的データ: 会社規模(売上や従業員数など)
- 質的データ: 業界(製造業/サービス業/小売業)、地域(都市部/地方)
k-プロトタイプ法を使ってこれらの既存顧客をクラスタリングすることで、顧客をいくつかのグループに分類できます。
次に、新しいリードのデータを用いて、どのクラスタに属するかを予測します。この結果に基づいて、リードが最も似ている既存顧客グループの営業アプローチを適用することができます。
これにより、営業チームは各リードに対して最適な戦略を採用できるため、成約率の向上が期待できます。
また、よりパーソナライズされた提案が可能になるため、リードの関心を引きやすくなります。
たとえば、「サービス業で都市部にある中規模企業」というセグメントに対して、成功率の高い営業資料や提案を使うことで、効果的に商談を進めることができます。
まとめ
k-プロトタイプ法は、量的データと質的データが混在するデータセットを効果的にクラスタリングするための強力なツールです。
パラメータの調整などを行うことで、ビジネスの様々なシナリオにおいて有用なインサイトを得ることができます。
この手法を使いこなすことで、データドリブンな意思決定を支援し、さらなるビジネスの成長につながることでしょう。