
私たちの周りには、時間とともに変化するデータであふれています。
毎日の気温、株価の変動、心電図の波形など、これらはすべて時系列データと呼ばれ、私たちの生活や社会活動に深く関わっています。
今回は、そんな時系列データを「分類」するとはどういうことなのか、そしてどのように分類するのかを、解説していきます。
Contents [hide]
時系列データ分類とは?
まずは、時系列データ分類の基本的な概念を理解していきましょう。
時系列データ
時系列データとは、時間の経過とともに観測されたデータのことです。 私たちの身の回りには、たくさんの時系列データが存在しています。
例えば……
- 毎日の気温の変化
- 株価の変動
- 心電図の波形
- ウェブサイトへのアクセス数
- 音声データ
……など、挙げればきりがありません。
これらのデータは、単に数値や記号を並べたものではなく、時間という軸に沿って変化していくという特徴を持っています。
なぜ分類するのか?
では、なぜ時系列データを分類する必要があるのでしょうか?
それは、データに隠されたパターンや特徴を見つけ出し、有益な情報を得るためです。
例えば……
- 異常検知: 機械の振動データから故障の兆候を早期に発見する。
- パターン認識: 音声データから話者を識別する。
- 将来予測: 株価の過去のデータから将来の値動きを予測する。
……など、時系列データ分類は様々な分野で活用されています。
分類の種類
時系列データの分類は、大きく以下の3つの種類に分けられます。
- 単一クラス分類: 正常な状態を学習し、異常なデータ(外れ値)を検出する。
- 二値分類: データを2つのクラス(例:正常/異常、A/B)に分類する。
- 多クラス分類: データを3つ以上のクラス(例:A/B/C、話者1/話者2/話者3)に分類する。
どの分類方法を使うかは、分析の目的やデータの種類によって異なります。
時系列データ分類の手法
時系列データを分類するには、いくつかの手法があります。
それぞれの手法は、データの特徴や分析の目的に合わせて使い分けられます。
ここでは、代表的な手法をいくつか紹介しましょう。
距離ベースの手法
距離ベースの手法は、時系列データ同士の「似具合」を距離で測り、似たデータは同じクラスに分類するという考え方です。
代表的な手法として、Dynamic Time Warping (DTW) が挙げられます。
DTWは、2つの時系列データの形状が似ていれば、時間軸のズレを許容して距離を計算する手法です。
例えば、同じ動作を異なる速度で行った場合でも、DTWを用いれば類似していると判断できます。
これは、音声認識やモーション認識など、時間軸のズレが生じやすいデータの分類に有効です。
辞書ベースの手法
辞書ベースの手法は、時系列データを「単語」の列として表現し、単語の出現パターンに基づいて分類する手法です。
WEASEL は、この手法の代表例です。
WEASELは、時系列データを様々な長さの「窓」で切り取り、それぞれの窓内のパターンを「単語」として表現します。
そして、各クラスに特徴的な単語を辞書として作成し、未知のデータがどのクラスの辞書に近いかで分類を行います。
統計量ベースの手法
統計量ベースの手法は、時系列データから統計量を計算し、その統計量を用いて分類する手法です。
例えば……
- 平均値: データ全体の平均値
- 分散: データのばらつき具合
- 最大値/最小値: データの最大値と最小値
- 自己相関: データ自身の過去の値との相関関係
……などを統計量として計算することができます。
これらの統計量を、機械学習モデルに入力することで、時系列データを分類することが可能です。
機械学習モデルの活用
機械学習モデルを用いることで、時系列データから自動的に規則性を学習し、分類することができます。
代表的なモデルとしては……
- k近傍法 (KNN): 距離が近いk個のデータのクラスから、多数決で分類する。
- サポートベクターマシン (SVM): データを最適な超平面で分割する。
- 決定木: データを段階的に分割していくことで分類する。
……などが挙げられます。
これらのモデルは、統計量ベースの手法と組み合わせて用いられることが多く、高い分類精度を実現することができます。
Pythonを使った実践例
それでは、実際にPythonを使って時系列データを分類してみましょう。
ここでは、sktimeというライブラリを使って、簡単な分類タスクを行います。
必要なライブラリのインストール
まずは、必要なライブラリをインストールします。
pip install sktime
データの準備
今回は、sktimeに組み込まれているデータセット(load_arrow_head)を使用します。
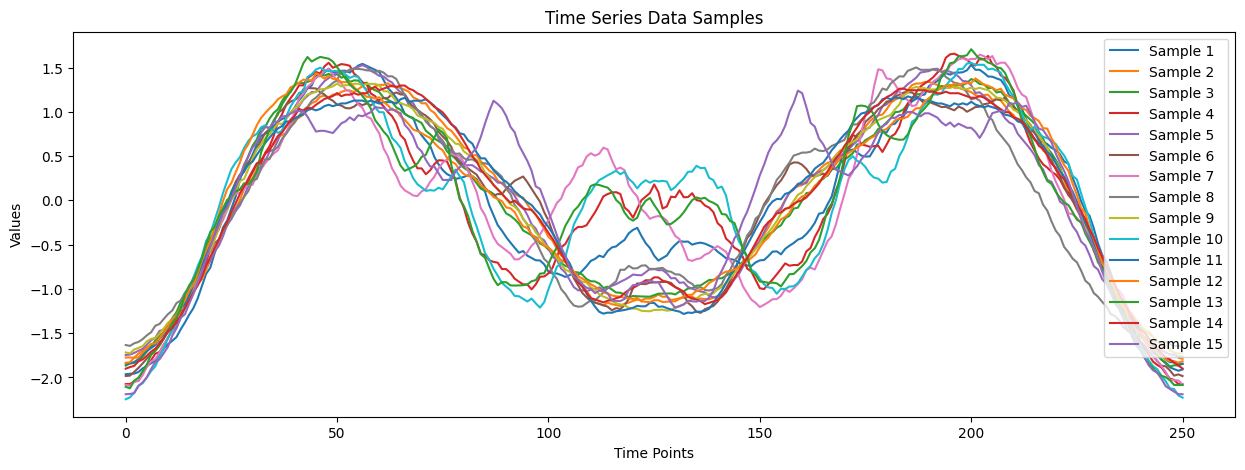
このload_arrow_head は、考古学の分野の矢じりの外形を表す時系列データセットです。
では、読み込みます。
以下、コードです。
from sktime.datasets import load_arrow_head X, y = load_arrow_head(return_X_y=True)
X: 矢じりの形状を表す時系列データ
形状は (211, 1) で、211個のサンプルがあり、各サンプルは1次元の時系列データです。
各サンプルには、矢じり形状を表す長さ 251 の時系列が格納されており、値は z 正規化された浮動小数点です。
データ型はNumPyの多次元配列(numpy.ndarray)です。
y: 各矢じりのクラスラベル
形状は (211,) で、各サンプルに対応する矢じりが属する文化圏を表すクラスラベル(0, 1, 2)が格納されています。
データ型はNumPyの配列(numpy.ndarray)です。
具体的には……
y[i] == 0なら、X[i]は Avonlea の矢じりy[i] == 1なら、X[i]は Clovisの矢じりy[i] == 2なら、X[i]は Wylies の矢じり
……となります。
各矢じりの特徴は以下の通りです。
- Avonlea : およそ西暦3世紀~8世紀頃に北米北部平原地域で使用された小型の矢じりで、弓矢用に特化して軽量・細身化されている
- Clovis : 北米における最古級の石器文化(紀元前約13,000~11,000年)頃のもので、基部に縦溝(フルート)がある大型の槍・投槍器用ポイントで、マンモス等の大型獣狩猟に用いられたと考えられる
- Wylies : Clovis よりは新しく、Avonlea ほどの小型化はされていない矢じり。地域や時期により形状がやや異なり、中期~後期の古期(Archaic~Woodland 期)にかけて利用されたと推定されている
どのような感じでデータが格納されているのかを、一番最初のサンプルで見てみます。
以下、コードです。
print('X[0]\n', X.iloc[0].values)
print('--')
print('y[0]\n', y[0])
以下、実行結果です。
X[0]
[0 -1.963009
1 -1.957825
2 -1.956145
3 -1.938289
4 -1.896657
...
246 -1.841345
247 -1.884289
248 -1.905393
249 -1.923905
250 -1.909153
Length: 251, dtype: float64]
--
y[0]
0
X[0] は最初の矢じりの形状データ、y[0] はその矢じりのクラスラベルを表します。
モデルの構築と評価
今回は、K近傍法(KNN)を用いてDTWで分類を行います。sktimeでは、KNeighborsTimeSeriesClassifierというクラスでKNNを利用できます。
まずは、学習データとテストデータに分割します。
from sklearn.model_selection import train_test_split
# 学習データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size=0.3,
random_state=42
)
学習データで学習します。
以下、コードです。
from sktime.classification.distance_based import KNeighborsTimeSeriesClassifier
# クラス分類器のインスタンスを作成
classifier = KNeighborsTimeSeriesClassifier(
distance="dtw", # 距離に DTW を使う
n_neighbors=3, # 3つの近傍
n_jobs=-1 # 並列化
)
# 学習
classifier.fit(X_train, y_train)
KNeighborsTimeSeriesClassifier は、sktime ライブラリに含まれる 時系列データに対する k-NN(k近傍法)分類器です。
通常の k-NN ではユークリッド距離などを用いますが、時系列同士の「ずれ」などを考慮した DTW (Dynamic Time Warping) 距離を使うことで、時系列のパターンをより柔軟に比較できます。
distance="dtw":KNN の「距離」の定義に DTW を用いる。n_neighbors=3:近傍とみなす件数(k)を 3 にする。n_jobs=-1:計算を CPU のコア数を最大限使って並列実行する。
テストデータに対する精度を計算します。
以下、コードです。
accuracy = classifier.score(X_test, y_test)
print(f"Accuracy: {accuracy}")
以下、実行結果です。
Accuracy: 0.828125
正答率は約83%です。
分類予測するときは、predictメソッド(予測値)もしくはpredict_probaメソッド(予測確率)を使用します。
テストデータの最初のサンプルに対し予測を実施してみます。
以下、コードです。
# クラス予測値
y_pred = classifier.predict(X_test.iloc[[0]])
print(f"True: {y_test[0]}, Pred: {y_pred[0]}")
# クラス予測確率
y_pred_prob = classifier.predict_proba(X_test.iloc[[0]])
print(f"True: {y_test[0]}, Pred Probabilities: {y_pred_prob[0]}")
以下、実行結果です。
True: 0, Pred: 0 True: 0, Pred Probabilities: [1. 0. 0.]
実のクラスが0で、予測したクラスも0です。予測確率は、クラス0が100%で他が0%です。
時系列データ分類がもたらす成果
時系列データ分類が実際にどのような成果を上げているのか、事例を交えながら見ていきましょう。
製造業における予知保全
ある自動車部品メーカーでは、工場の生産ラインにおける機械の振動データを収集し、時系列データ分類を用いて故障の予兆を検知するシステムを導入しました。
活用データ
- 機械の振動センサーデータ
手法
- 統計量ベースの手法で振動データから統計量を抽出
- 機械学習モデル(SVM)で正常状態と異常状態を分類
成果
- 従来の定期的なメンテナンスに加え、故障予兆に基づくメンテナンスを実施
- 機械のダウンタイムを削減し、生産効率を向上
- メンテナンスコストを削減
医療における病気の早期発見
ある病院では、患者の心電図データを収集し、時系列データ分類を用いて心臓疾患の早期発見に役立てています。
活用データ
- 心電図データ
手法
- DTWを用いて正常な心電図パターンと異常な心電図パターンを分類
成果
- 従来の診断方法では見逃してしまう可能性のある軽微な異常を検知
- 心臓疾患の早期発見・早期治療に貢献
- 患者のQOL向上に貢献
金融における不正取引の検知
あるクレジットカード会社では、顧客の取引履歴データを分析し、時系列データ分類を用いて不正利用を検知するシステムを構築しました。
活用データ
- 顧客のカード利用履歴データ(利用日時、利用金額、利用場所など)
手法
- 辞書ベースの手法で、過去の不正利用パターンを学習
- リアルタイムの取引データを分析し、不正利用の可能性が高い取引を検知
成果
- 不正利用による被害を大幅に削減
- 顧客の信頼を獲得
まとめ
時系列データ分類は、時間とともに変化するデータの特徴を捉え、グループ分けする技術です。
心電図や脳波、株価、機械のセンサーデータなど、様々な分野で活用されています。
距離ベースのDynamic Time Warpingや辞書ベースのWEASEL、特徴量ベースの手法などがあり、Pythonのsktimeライブラリで実装できます。
近年では深層学習も活用され、より複雑なパターンを学習することが可能になっています。
時系列データ分類は、未来予測や異常検知、パターン認識など、様々な問題解決に役立つ重要な技術と言えるでしょう。