
Pandas が登場してから Python はデータ分析の事実上の標準言語になりました。
しかし、データ量が数千万行を超えると途端に RAM が足りない・処理が遅い という現実にぶつかります。
クラスタ環境に逃げる選択肢もありますが、準備・コスト・学習コストを考えると “ちょっと重い” だけのデータに対してはオーバーキルです。
そこで登場するのが Dask。
以下 3 点が現場エンジニアにとって大きな魅力です。
- API 類似度 90 %: 既存の Pandas/NumPy 知識をそのまま使える。
- 遅延評価 × 並列化: PC のコア数を自動で使い切り、メモリフットプリントを抑制。
- スケールラインが滑らか: ローカル PC → 分散クラスタへ“ほぼ同じコード”で移行可能。
今回は「大量 CSV を集計する」という 典型的に重くなる処理 を通して、Dask がどのように恩恵をもたらすかを見てみます。
Contents [hide]
Pandas と Dask の比較
まずは、それぞれの特徴を整理し、違いを明確に把握しましょう。
| Pandas | Dask データフレーム | |
|---|---|---|
| 主な用途 | 単一スレッドでの高速なインメモリ処理 | 並列・分散処理を抽象化し、大規模データに対応 |
| メモリ利用の仕組み | データ全体を一度にRAMへ読み込む | データをチャンク単位で分割し、断片的にRAMを使用 |
| 計算の実行タイミング | 即時評価(呼び出しと同時に計算) | 遅延タスクグラフを構築し、compute()で実行 |
| スケジューラ | OS 標準のスケジューラに依存 | スレッド・プロセス・分散クラスタから選択可能 |
上の表に示したように、Pandas は小~中規模データの分析に向いています。
データをすべて一度にメモリ上に読み込むため(メモリ利用の仕組み)、呼び出しと同時に計算が始まる「即時評価」の性質を持ちます。
そのため、操作後すぐに結果を確認でき、シンプルな API で手軽にデータ操作を進められるのが大きな利点です。
一方、Dask データフレーム は大量データや複雑な計算を扱う場面で威力を発揮します。
データを小さなチャンクに分割し断片的にメモリへ読み込むことで、限られた RAM 上でも処理が可能です。
また、遅延タスクグラフを構築し、compute() を呼び出すタイミングで一括実行するため、中間生成物の無駄を省きつつ高速に処理できます。
さらに、実行環境に応じてスレッド・プロセス・分散クラスタを自由に選択できるため、開発段階から本番環境まで同じコードでスケールさせやすい柔軟性が特徴です。
Daskのインストール
Dask を使い始めるには、Python 環境とパッケージ管理ツールが整っていれば、たった1行のコマンドでインストールできます。
| インストール方法 | コマンド |
|---|---|
| Conda を使う場合 | conda install -c conda-forge dask |
| pip を使う場合 | pip install dask |
サンプルデータ
次のような店舗別の売上データを利用します。
- 店舗数:200
- 各店舗のレコード数:10万行
- 変数:
- store: 店舗番号
- product: 商品ID
- date: 日付
- sales: 売上金額
全てのデータを合算すると、合計2,000万行のデータです。
店舗別にCSVファイルに格納されており、ファイル名は以下のようにdaily_sales_の後に店舗番号が付いたものになっています。
daily_sales_[店舗番号].csv
このようなCSVファイルが200個あるということです。
このデータは以下からダウンロードできます。
CSVファイル一式
https://www.salesanalytics.co.jp/x40x
処理時間比較
今から、店舗別の200のCSVファイルを読み込み、全データを結合し、月別に集計していきます。
以下の3パターンで実施し、処理時間を比べます。
- Pandasで処理
- Daskで処理
- Pandas の処理の中で Dask Delayed を使う
Dask Delayed を使うと、既存の Pandas コードを大きく書き換えることなく、関数単位で「遅延タスク」に変換して並列実行できるようになります。具体的には、 @dask.delayed デコレータ(もしくは delayed(...))を適用し、処理の呼び出し時には計算を行わずにタスクグラフを構築し、compute()が呼び出されたタイミングで一括実行します。
Pandasで処理
以下、コードです。
import pandas as pd
import time
import glob
# 処理時間の計測開始
start = time.perf_counter()
# CSVファイル一覧を取得
files = glob.glob("data/daily_sales_*.csv")
# for文でファイルを逐次読み込み
dfs = [] # DataFrameを格納するリスト
for f in files:
df = pd.read_csv(f, parse_dates=['date'])
dfs.append(df)
pdf = pd.concat(dfs)
# date列から年月の列を作成
pdf['year_month'] = pdf['date'].dt.strftime('%Y-%m')
# date列をインデックスに設定
pdf = pdf.set_index('date')
# データを店舗別商品別の年月別に集計する処理
monthly = pdf.groupby([
'store',
'product',
'year_month'
])['sales'].sum().reset_index()
# 年月でソート
monthly = monthly.sort_values(['store', 'product', 'year_month'])
# 結果を表示
print(monthly.head())
# 処理時間の計算
pd_time = time.perf_counter() - start
# 処理時間の表示
print(f"Processing Time (seconds) : {pd_time:.2f}s")
このコードの流れです。
- タイマーをスタートして、処理時間の計測を開始
glob.glob()で対象の CSV ファイル一覧を取得forループ内でpd.read_csv()を使って各 CSV を逐次読み込みし、リストに格納pd.concat()でリスト内のデータフレームを結合date列からstrftime('%Y-%m')により「年-月」を表すyear_month列を作成set_index()でdate列をインデックスに設定groupby+sum()で店舗・商品・年月ごとの売上を集計し、reset_index()とsort_values()で整形- 集計結果の先頭を表示し、タイマーを止めて全体の処理時間を秒単位で出力
以下、実行結果です。
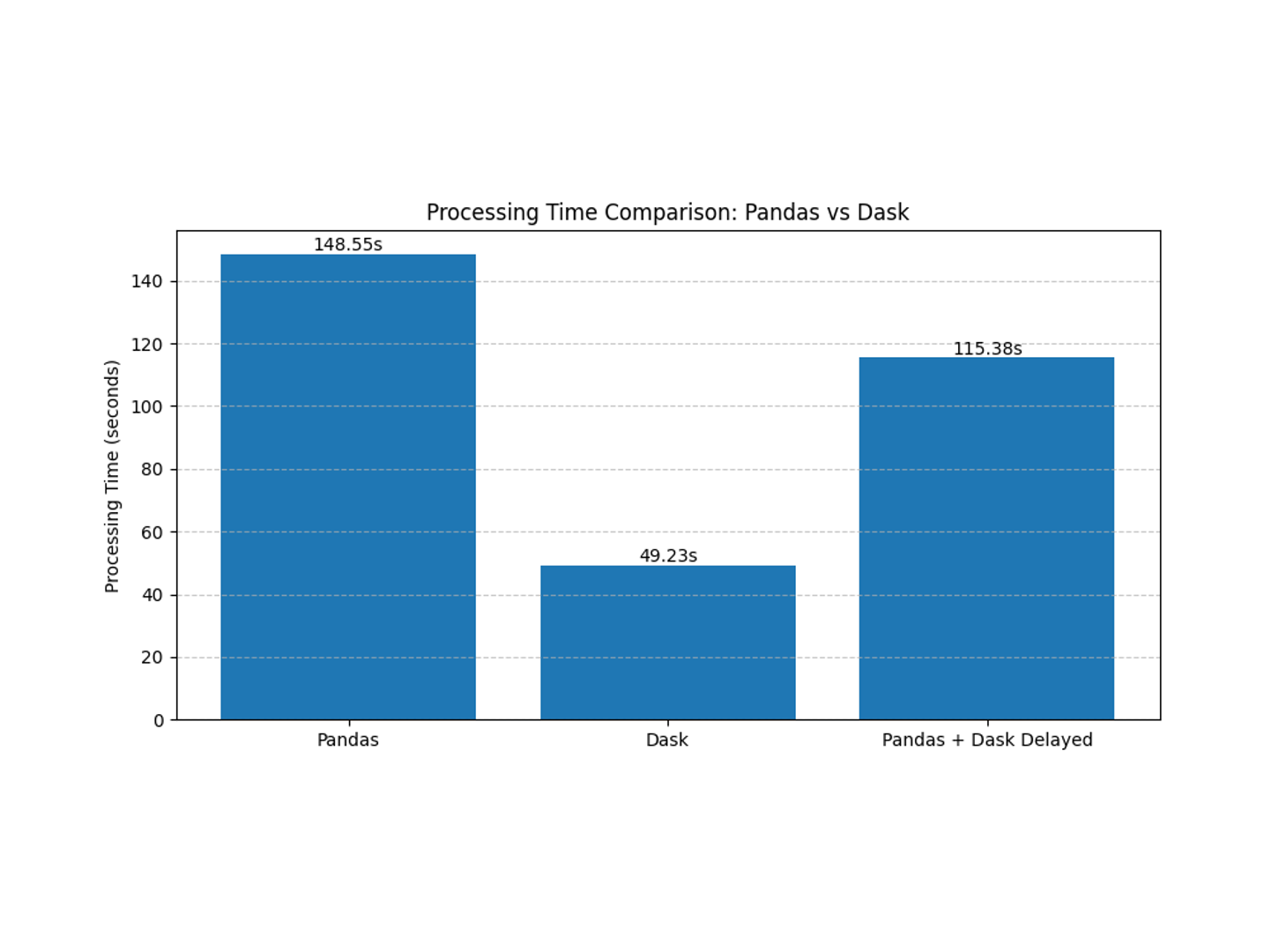
store product year_month sales 0 0 0 2023-01 1094.897811 1 0 0 2023-02 1096.106691 2 0 0 2023-03 1277.466556 3 0 0 2023-04 1417.308542 4 0 0 2023-05 1349.660263 Processing Time (seconds) : 148.55s
Daskで処理
以下、コードです。
import dask.dataframe as dd
import time
# 処理時間の計測開始
start = time.perf_counter()
# CSVファイルをDaskデータフレームとして読み込む
pdf = dd.read_csv(
"data/daily_sales_*.csv",
parse_dates=['date'],
)
# 年・月の列を追加
pdf['year_month'] = pdf['date'].dt.to_period('M').dt.to_timestamp()
# 月次集計(年-月ごとに)
dd_monthly = pdf.groupby([
'store',
'product',
'year_month'
])['sales'].sum().to_frame('sales').reset_index()
# compute()メソッドを使用しPandasデータフレームに変換
monthly = dd_monthly.compute()
# 結果を表示
print(monthly.head())
# 処理時間の計算
dd_time = time.perf_counter() - start
# 処理時間の表示
print(f"Processing Time (seconds) : {dd_time:.2f}s")
このコードの流れです。
- タイマーをスタートして、処理時間の計測を開始
dd.read_csv()で複数の CSV ファイルをまとめて Dask データフレームとして読み込む- 読み込んだ日付列から「年月」を表す新しい列
year_monthを追加 groupby+sum()によって店舗・商品・年月ごとの売上合計を計算し、結果を新しい Dask データフレームにまとめるcompute()を呼び出して、Dask データフレームを Pandas データフレームに変換- 集計結果の先頭を表示し、タイマーを止めて全体の処理時間を秒数で出力
以下、実行結果です。
store product year_month sales 0 139 0 2029-05-01 1370.741023 1 139 0 2030-12-01 1223.201196 2 139 1 2026-05-01 1683.776449 3 139 1 2030-01-01 659.329479 4 139 1 2033-09-01 1387.381915 Processing Time (seconds) : 49.23s
Pandas の処理の中で Dask Delayed を使う
以下、コードです。
import pandas as pd
import dask.dataframe as dd
from dask.delayed import delayed
import glob
import time
# 処理時間の計測開始
start = time.perf_counter()
# CSVファイル一覧を取得
files = glob.glob("data/daily_sales_*.csv")
# delayed を使用してファイル読み込みを遅延評価化
@delayed
def read_csv(filename):
return pd.read_csv(filename, parse_dates=['date'])
# 各ファイルの読み込みを遅延評価として準備
delayed_dfs = [read_csv(f) for f in files]
# すべてのデータフレームの結合を遅延評価として準備
@delayed
def combine_dfs(dfs):
pdf = pd.concat(dfs)
# date列から年月の列を作成
pdf['year_month'] = pdf['date'].dt.strftime('%Y-%m')
# date列をインデックスに設定
pdf = pdf.set_index('date')
return pdf
# 集計処理を遅延評価として準備
@delayed
def aggregate_data(pdf):
# データを店舗別商品別の年月別に集計する処理
monthly = pdf.groupby([
'store',
'product',
'year_month'
])['sales'].sum().reset_index()
# 年月でソート
monthly = monthly.sort_values(['store', 'product', 'year_month'])
return monthly
# 遅延評価の実行チェーンを構築
pdf = combine_dfs(delayed_dfs)
monthly = aggregate_data(pdf)
# 実際の計算を実行
result = monthly.compute()
# 結果を表示
print(result.head())
# 処理時間の計算
pd_dd_time = time.perf_counter() - start
# 処理時間の表示
print(f"Processing Time (seconds) : {pd_dd_time:.2f}s")
このコードの流れです。
- タイマーをスタートして、処理時間の計測を開始
glob.glob()で対象の CSV ファイル一覧を取得@delayedを使って CSV ファイル読み込み関数を遅延評価化- リスト内包表記で各ファイルの読み込みタスクを準備
combine_dfs関数を遅延評価化し、全 データフレームの結合、年月の列作成、インデックス設定を準備aggregate_data関数を遅延評価化し、店舗・商品・年月別の売上集計とソート処理を準備combine_dfs(delayed_dfs)とaggregate_data(pdf)の呼び出しでタスクグラフを構築compute()を呼び出して、遅延タスクを並列実行し結果を取得- 結果の先頭行を表示し、タイマーを停止、全体の処理時間を秒単位で出力
以下、実行結果です。
store product year_month sales 0 0 0 2023-01 1094.897811 1 0 0 2023-02 1096.106691 2 0 0 2023-03 1277.466556 3 0 0 2023-04 1417.308542 4 0 0 2023-05 1349.660263 Processing Time (seconds) : 115.38s
グラフで比較
最後に、以下の3パターンで実施した処理時間をグラフで比べます。
- Pandasで処理
- Daskで処理
- Pandas の処理の中で Dask Delayed を使う
以下、コードです。
import matplotlib.pyplot as plt
# データの準備
frameworks = ['Pandas', 'Dask', 'Pandas + Dask Delayed']
times = [pd_time, dd_time, pd_dd_time]
# グラフの作成
plt.figure(figsize=(10, 5))
bars = plt.bar(frameworks, times)
# グラフの装飾
plt.title('Processing Time Comparison: Pandas vs Dask')
plt.ylabel('Processing Time (seconds)')
plt.grid(axis='y', linestyle='--', alpha=0.7)
# 棒の上に数値を表示
for bar in bars:
height = bar.get_height()
plt.text(bar.get_x() + bar.get_width()/2., height,
f'{height:.2f}s',
ha='center', va='bottom')
plt.show()
以下、実行結果です。
Dask Delayedとは?
Dask Delayed は、既存の Python 関数やスクリプトをほとんど書き換えずに「遅延評価」し、並列/分散処理できるようにする仕組みです。
ちなみに、遅延評価(Lazy Evaluation)とは、必要になるまで計算や処理を実行せず、「後回し」にしておく仕組みのことです。
“遅延タスク”への変換
普通に関数を呼び出すとすぐに処理が実行されますが、Dask Delayed では関数に @delayed デコレータ(もしくは delayed() 関数呼び出し)を付けることで、その呼び出し自体を「タスク」として記録します。実行はされず、タスクだけが積み上がるイメージです。
タスクグラフの構築
こうして作成された遅延タスクは、依存関係を持つ “ノード” として、Dask の内部にグラフ(DAG: 有向非巡回グラフ)を構築します。例えば「ファイル読み込み → 結合 → 集計」といった複数ステップの処理を、それぞれ独立したタスクとしてグラフ化できます。
一括実行と最適化
最後に .compute() を呼ぶと、Dask がタスクグラフ全体を解析し、最適な順序や並列実行のスケジュールを自動的に決定します。その結果、マルチコア/マルチプロセス、あるいはクラスタ上で並列に処理を行い、高速化やメモリ効率の向上を図れます。
既存コードとの親和性
Pandas や NumPy で書いた関数をそのまま遅延タスク化できるため、コードの大幅な書き換えが不要です。また、Dask データフレーム や Array を使わずに、必要な部分だけ Delayed で置き換えるハイブリッド運用も可能です。
まとめると、Dask Delayed は「関数呼び出しをタスク化し、タスクグラフを遅延構築→最適化→並列実行する」ことで、シンプルなコードを書いたまま大規模データ処理をスケールさせるための強力なツールです。
Dask の主な機能
今回は、すぐ使える機能ということでDask データフレームを中心にお話しをしました。
他にも幾つか便利な機能があります。以下、まとめたものです。
| 機能 | 説明 |
|---|---|
| Dask DataFrame | Pandas とほぼ互換の API を提供し、行・列をパーティションに分割して並列/分散実行することで、メモリを超えるサイズの表形式データも扱える。 |
| Dask Array | NumPy ndarray のサブセット API をブロックアルゴリズムで実装。大規模多次元配列や線形代数演算をコア数・クラスタ規模までスケールさせる。 |
| Dask Bag | JSON/ログなど半構造化データを対象に、map・filter・fold など Map-Reduce 風操作を並列化できるコレクション。 |
| 分散スケジューラ | スレッド・プロセス(単一マシン)から Dask Distributed を用いたクラスタ実行まで、タスクスケジューラを柔軟に切り替えられる。 |
| リアルタイムモニタリング | Bokeh 製の Web ダッシュボードが自動生成され、タスクグラフの進行状況や CPU/メモリ使用量をリアルタイムに可視化できる。 |
| Dask-ML | Scikit-Learn 互換 API で前処理・学習・推論を並列/分散化し、早期停止付きハイパーパラメータ探索などもサポート。 |
| Futures インターフェース | concurrent.futures と類似した文法で Python 関数を Future 化し、クラスタ全体へ非同期スケジュールできる。 |
| エコシステム統合 | XGBoost・CuPy・RAPIDS など GPU/分散ライブラリとシームレスに連携し、CPU と GPU をまたいだ高速処理を実現。 |
詳しくは、以下のDaskのドキュメントを見てください。
まとめ
今回は、簡単なデモを通じDaskの高速化の一端を説明しました。
具体的には、Daskのデータフレームをメインに使い、200 ファイル・約2,000 万行の売上 CSV を月次集計するベンチマークを通じて、Pandas では約150 秒かかった処理が Dask データフレーム では遅延評価とタスクグラフにより約50 秒に短縮できることを示した。
Daskは、データフレーム 以外にも追加モジュールが用意されており、ニーズに応じて段階的に活用範囲を広げられるのが Dask の魅力です。