
次の Python コードの出力はどれでしょうか?
Python コード:
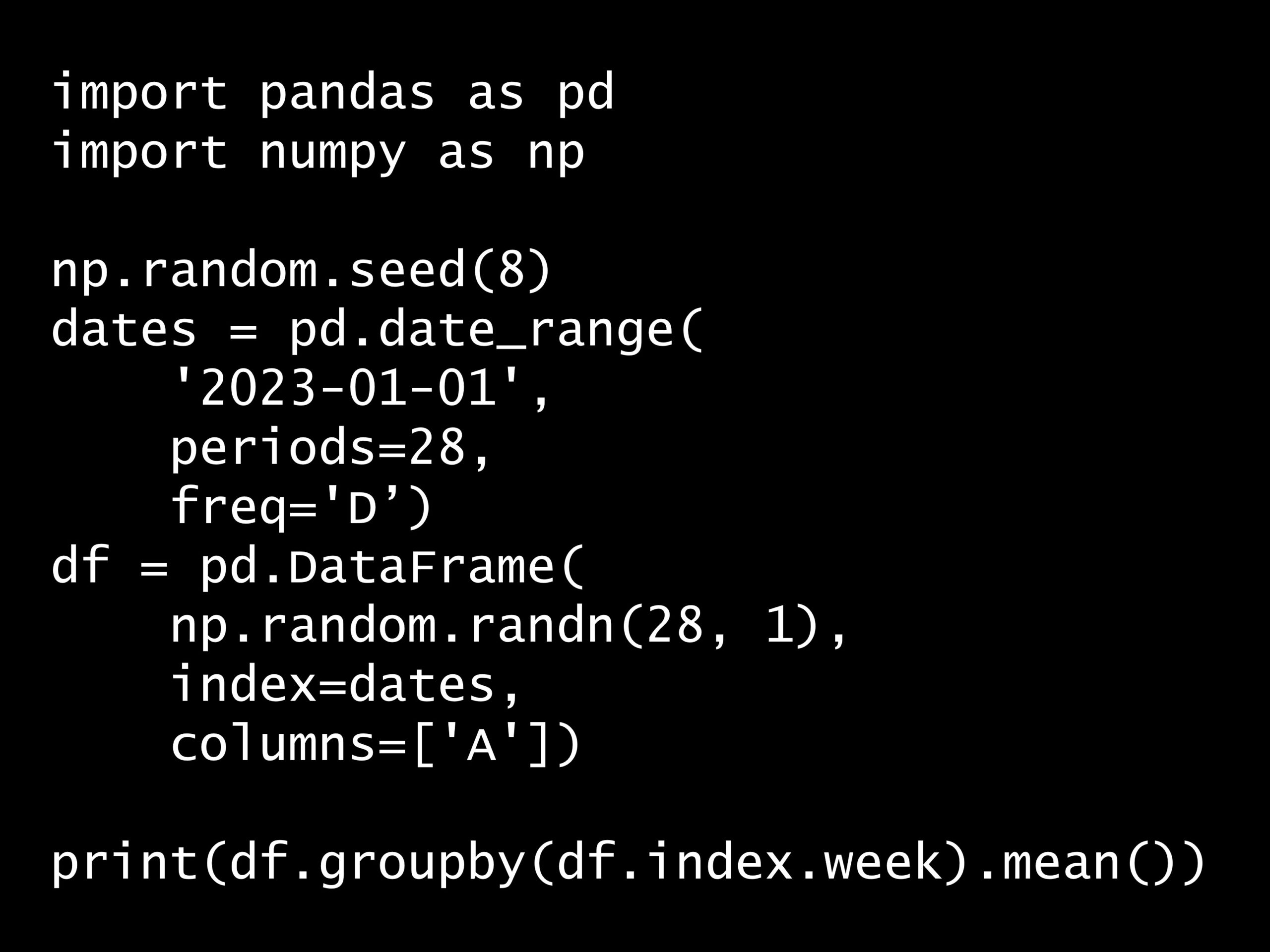
import pandas as pd
import numpy as np
np.random.seed(8)
dates = pd.date_range(
'2023-01-01',
periods=28,
freq='D')
df = pd.DataFrame(
np.random.randn(28, 1),
index=dates,
columns=['A'])
print(df.groupby(df.index.week).mean())
import pandas as pd
import numpy as np
np.random.seed(8)
dates = pd.date_range(
'2023-01-01',
periods=28,
freq='D')
df = pd.DataFrame(
np.random.randn(28, 1),
index=dates,
columns=['A'])
print(df.groupby(df.index.week).mean())
import pandas as pd
import numpy as np
np.random.seed(8)
dates = pd.date_range(
'2023-01-01',
periods=28,
freq='D')
df = pd.DataFrame(
np.random.randn(28, 1),
index=dates,
columns=['A'])
print(df.groupby(df.index.week).mean())
回答の選択肢:
(A) 週ごとの平均値
(B) 各日のランダムな値
(C) 月ごとの平均値
(D) 年ごとの平均値
出力例:
A
1 0.257671
2 0.048352
3 0.043252
4 -0.029687
52 0.091205
A
1 0.257671
2 0.048352
3 0.043252
4 -0.029687
52 0.091205
A 1 0.257671 2 0.048352 3 0.043252 4 -0.029687 52 0.091205
正解:
(A)
解説:
このコードは、ランダムな値を持つ時系列データを作成し、そのデータを週ごとにグループ化した後に、各グループの平均値を計算しています。
詳しく説明します。
‘2023-01-01’から始まる日付範囲を28期間作成します。ここで頻度として指定している’D’は「日」を意味します。
dates = pd.date_range(
'2023-01-01',
periods=28,
freq='D')
dates = pd.date_range(
'2023-01-01',
periods=28,
freq='D')
dates = pd.date_range(
'2023-01-01',
periods=28,
freq='D')
datesに格納されているデータは次のようになっています。
DatetimeIndex(['2023-01-01', '2023-01-02', '2023-01-03', '2023-01-04',
'2023-01-05', '2023-01-06', '2023-01-07', '2023-01-08',
'2023-01-09', '2023-01-10', '2023-01-11', '2023-01-12',
'2023-01-13', '2023-01-14', '2023-01-15', '2023-01-16',
'2023-01-17', '2023-01-18', '2023-01-19', '2023-01-20',
'2023-01-21', '2023-01-22', '2023-01-23', '2023-01-24',
'2023-01-25', '2023-01-26', '2023-01-27', '2023-01-28'],
dtype='datetime64[ns]', freq='D')
DatetimeIndex(['2023-01-01', '2023-01-02', '2023-01-03', '2023-01-04',
'2023-01-05', '2023-01-06', '2023-01-07', '2023-01-08',
'2023-01-09', '2023-01-10', '2023-01-11', '2023-01-12',
'2023-01-13', '2023-01-14', '2023-01-15', '2023-01-16',
'2023-01-17', '2023-01-18', '2023-01-19', '2023-01-20',
'2023-01-21', '2023-01-22', '2023-01-23', '2023-01-24',
'2023-01-25', '2023-01-26', '2023-01-27', '2023-01-28'],
dtype='datetime64[ns]', freq='D')
DatetimeIndex(['2023-01-01', '2023-01-02', '2023-01-03', '2023-01-04',
'2023-01-05', '2023-01-06', '2023-01-07', '2023-01-08',
'2023-01-09', '2023-01-10', '2023-01-11', '2023-01-12',
'2023-01-13', '2023-01-14', '2023-01-15', '2023-01-16',
'2023-01-17', '2023-01-18', '2023-01-19', '2023-01-20',
'2023-01-21', '2023-01-22', '2023-01-23', '2023-01-24',
'2023-01-25', '2023-01-26', '2023-01-27', '2023-01-28'],
dtype='datetime64[ns]', freq='D')
この日付範囲をインデックスとして28行1列のランダムな値からデータフレームを作成します。このデータフレームの列名は ‘A’ となっています。
df = pd.DataFrame(
np.random.randn(28, 1),
index=dates,
columns=['A'])
df = pd.DataFrame(
np.random.randn(28, 1),
index=dates,
columns=['A'])
df = pd.DataFrame(
np.random.randn(28, 1),
index=dates,
columns=['A'])
dfに格納されているデータは次のようになっています。
A
2023-01-01 0.091205
2023-01-02 1.091283
2023-01-03 -1.946970
2023-01-04 -1.386350
2023-01-05 -2.296492
2023-01-06 2.409834
2023-01-07 1.727836
2023-01-08 2.204556
2023-01-09 0.794828
2023-01-10 0.976421
2023-01-11 -1.183427
2023-01-12 1.916364
2023-01-13 -1.123327
2023-01-14 -0.664035
2023-01-15 -0.378359
2023-01-16 -0.791615
2023-01-17 0.859548
2023-01-18 -0.230789
2023-01-19 -0.065661
2023-01-20 -0.208636
2023-01-21 1.346869
2023-01-22 -0.606953
2023-01-23 -0.174248
2023-01-24 0.424051
2023-01-25 -1.645990
2023-01-26 -0.483541
2023-01-27 0.535468
2023-01-28 1.166140
A
2023-01-01 0.091205
2023-01-02 1.091283
2023-01-03 -1.946970
2023-01-04 -1.386350
2023-01-05 -2.296492
2023-01-06 2.409834
2023-01-07 1.727836
2023-01-08 2.204556
2023-01-09 0.794828
2023-01-10 0.976421
2023-01-11 -1.183427
2023-01-12 1.916364
2023-01-13 -1.123327
2023-01-14 -0.664035
2023-01-15 -0.378359
2023-01-16 -0.791615
2023-01-17 0.859548
2023-01-18 -0.230789
2023-01-19 -0.065661
2023-01-20 -0.208636
2023-01-21 1.346869
2023-01-22 -0.606953
2023-01-23 -0.174248
2023-01-24 0.424051
2023-01-25 -1.645990
2023-01-26 -0.483541
2023-01-27 0.535468
2023-01-28 1.166140
A 2023-01-01 0.091205 2023-01-02 1.091283 2023-01-03 -1.946970 2023-01-04 -1.386350 2023-01-05 -2.296492 2023-01-06 2.409834 2023-01-07 1.727836 2023-01-08 2.204556 2023-01-09 0.794828 2023-01-10 0.976421 2023-01-11 -1.183427 2023-01-12 1.916364 2023-01-13 -1.123327 2023-01-14 -0.664035 2023-01-15 -0.378359 2023-01-16 -0.791615 2023-01-17 0.859548 2023-01-18 -0.230789 2023-01-19 -0.065661 2023-01-20 -0.208636 2023-01-21 1.346869 2023-01-22 -0.606953 2023-01-23 -0.174248 2023-01-24 0.424051 2023-01-25 -1.645990 2023-01-26 -0.483541 2023-01-27 0.535468 2023-01-28 1.166140
最後に、データフレームの `groupby` メソッドを用いてデータを週ごとにグループ化します。ここで、`df.index.week`はデータフレームのインデックス(日付)から週の番号を取得します。その後、各グループに対して平均値を計算します(`mean()`メソッド)。
print(df.groupby(df.index.week).mean())
print(df.groupby(df.index.week).mean())
print(df.groupby(df.index.week).mean())
出力としては、各週ごとの平均値が表示されます。
A
1 0.257671
2 0.048352
3 0.043252
4 -0.029687
52 0.091205
A
1 0.257671
2 0.048352
3 0.043252
4 -0.029687
52 0.091205
A 1 0.257671 2 0.048352 3 0.043252 4 -0.029687 52 0.091205