
- 問題
- 答え
- 解説
- 全く予測不可能なデータ
- Ljung-Box検定とは?
Python コード:
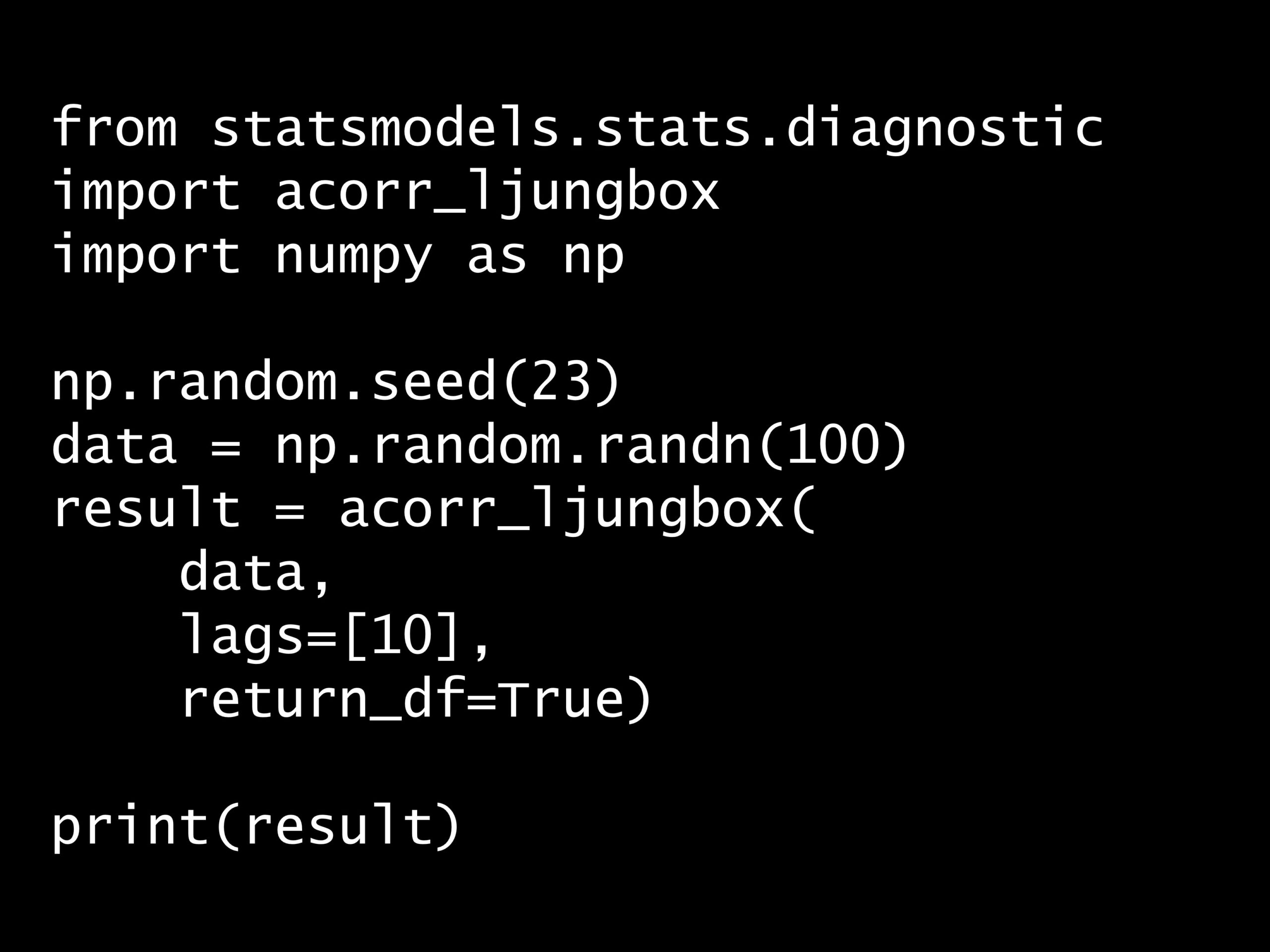
from statsmodels.stats.diagnostic import acorr_ljungbox
import numpy as np
np.random.seed(23)
data = np.random.randn(100)
result = acorr_ljungbox(
data,
lags=[10],
return_df=True)
print(result)
回答の選択肢:
(A) 自己相関の検定結果
(B) 単位根の検定結果
(C) ホワイトノイズの検定結果
(D) グレンジャー因果の検定結果
lb_stat lb_pvalue 10 4.506826 0.921601
正解: (C)
回答の選択肢:
(A) 自己相関の検定結果
(B) 単位根の検定結果
(C) ホワイトノイズの検定結果
(D) グレンジャー因果の検定結果
from statsmodels.stats.diagnostic import acorr_ljungbox
import numpy as np
np.random.seed(23)
data = np.random.randn(100)
result = acorr_ljungbox(
data,
lags=[10],
return_df=True)
print(result)
詳しく説明します。
numpyの乱数生成器を用いてランダムデータ`data`を生成しています。このdataはホワイトノイズなデータです。
np.random.seed(23) data = np.random.randn(100)
「ホワイトノイズ」とは、一定の平均と一定の分散を持ち、各データポイントが互いに独立していると仮定されているランダムなデータです。
dataに格納されているデータは次のようになっています。
[ 0.66698806 0.02581308 -0.77761941 0.94863382 0.70167179 -1.05108156 -0.36754812 -1.13745969 -1.32214752 1.77225828 -0.34745899 0.67014016 0.32227152 0.06034293 -1.04345 -1.00994188 0.44173637 1.12887685 -1.83806777 -0.93876863 -0.20184052 1.04537128 0.53816197 0.81211867 0.2411063 -0.95250953 -0.13626676 1.26724821 0.17363364 -1.22325477 1.41531998 0.45771098 0.72887584 1.96843473 -0.54778801 -0.67941827 -2.50623032 0.14696049 0.60619549 -0.02253889 0.01342226 0.93594489 0.42062266 0.41161964 -0.07132392 -0.04543758 1.04088597 -0.09403473 -0.42084395 -0.55198856 -0.12109755 0.19014136 0.51213739 0.13153847 -0.33161712 -1.63238628 0.61911407 -0.99257378 -0.16134639 1.19240433 0.25073655 -0.81361625 0.70362363 -0.26814214 -0.48255948 1.24461048 0.67686012 3.18750269 -1.08056475 0.0102293 0.43782968 1.32778762 -0.25114503 1.59311063 0.17081771 -0.7092539 -0.13302459 -0.01735694 -0.10109291 -0.56403963 -0.1790356 1.01105883 0.92099584 1.93308983 -0.79536322 -1.0115352 2.15077995 0.42514008 0.44115151 -0.81743933 0.43789248 0.09972328 0.06540607 1.22443067 -0.76959905 0.19211968 -1.72325306 0.4612592 -1.08536678 1.82337823]
生成されたデータdataに対して、`acorr_ljungbox`関数を使用してホワイトノイズ検定を実施しています。
result = acorr_ljungbox(
data,
lags=[10],
return_df=True)
この関数は、Ljung-Box検定と呼ばれる統計的検定を実施するためのものです。
Ljung-Box検定は、時系列データが「ホワイトノイズである」(帰無仮説)かどうかを確認するための検定で、具体的にはデータの自己相関が全てゼロであるかどうかを検出します。
print(result)を用いて、Ljung-Box検定の結果を出力しています。
print(result)
lb_stat lb_pvalue 10 4.506826 0.921601
検定結果はDataFrame形式で、検定統計量`lb_stat`とp値 `lb_pvalue`を含みます。
これらの結果を用いて、データがホワイトノイズかどうかを判断します。p値が一定の閾値(例えば、0.05)以下であれば、データがホワイトノイズであるという帰無仮説を棄却します。
以下の3つの主要な特性を持つランダムな変動を指します。
- 平均が一定: ホワイトノイズの時系列データの平均は一定です。つまり、全ての時間点における期待値が同一です。
- 分散が一定: 各時間点におけるホワイトノイズの変動(バラツキ)は一定です。すなわち、分散(もしくは標準偏差)は時間に対して一定です。
- 自己相関がゼロ: ホワイトノイズの任意の2つの時間点間の相関(自己相関)はゼロです。つまり、ある時点の値は他の任意の時点の値とは無関係です。
これらの特性は、時系列データが無作為なノイズのみから成る場合、つまりデータが全く予測不可能な場合に当てはまります。
ホワイトノイズの概念は、時系列データが特定のモデルによって適切に説明されているかを評価するために重要です。
具体的には、モデルによって説明できない残差がホワイトノイズに近似することを一般的に望みます。これは、モデルがデータ内の全ての「有用な」情報を抽出し、残ったランダムなノイズを残したことを示します。
主な時系列データの検定
時系列データの検定には以下のような種類があります。
- 単位根検定:時系列データが非定常(つまり一つまたはそれ以上の単位根を含むか)かどうかを検定します。具体的な手法としては、Augmented Dickey-Fuller(ADF)検定、Kwiatkowski-Phillips-Schmidt-Shin(KPSS)検定などがあります。
- ホワイトノイズ検定:時系列データが純粋なホワイトノイズ(つまり、全ての時点で独立で、一定の平均と分散を持つ)であるかどうかを検定します。具体的な手法としては、Ljung-Box検定、Box-Pierce検定などがあります。
- 定常性検定:時系列データが、その平均と分散が時間とともに一定である条件を満たすかどうか検証するために用いられます。Kwiatkowski-Phillips-Schmidt-Shin(KPSS)検定がその一例です。
- グレンジャー因果性検定:時系列データ間に因果関係(一つの時系列が他の時系列に先行して影響を及ぼす)が存在するかどうかを検定します。
- 自己相関検定:時系列データの自己相関を検定します。たとえば、Durbin-Watson検定は一定のラグでの自己相関を検定します。
これらの検定は、時系列データが特定の前提条件を満たすかを確認し、適切な時系列分析手法を選ぶために重要です。また、時系列モデルの適合度を評価するためにも用いられます。
Ljung-Box検定とは?
Ljung-Box検定は、時系列データがホワイトノイズであるかどうかを検定するための手法です。時系列データがどの程度ランダムであるか(すなわち、どの程度予測不能であるか)を検定します。
具体的には、Ljung-Box検定は、一定の遅延(ラグ)までの自己相関がゼロであるという帰無仮説を検定します。
自己相関がゼロである場合、時系列データのある値は過去の値に依存せず、ランダムな(予測不能な)値であると解釈できます。つまり、データがホワイトノイズであるという仮説を支持します。
- 帰無仮説(Null Hypothesis):データはホワイトノイズである。つまり、選択したラグ数までの全ての自己相関係数はゼロである。
- 対立仮説(Alternative Hypothesis):データはホワイトノイズではない。少なくとも1つの自己相関係数はゼロではない。
Ljung-Box検定は、選択したラグ数までの自己相関が全てゼロであるかどうかを検定します。
- 自己相関がゼロである場合、データのある値は過去の値に依存せず、ランダムな(予測不能な)値であると解釈できます。つまり、データがホワイトノイズであるという帰無仮説が成立します。
- 一方、p値が一定の閾値(例えば、0.05)以下であれば、データがホワイトノイズである(つまり帰無仮説)という仮説を棄却します。そして、対立仮説(少なくとも1つの自己相関係数がゼロではない)を採択します。これは、データがランダムなホワイトノイズではなく、ある程度予測が可能であることを示します。
このLjung-Box検定は、モデルの残差を検証し、時系列モデルが適切にデータをフィットしているかどうか(すなわち、残差がホワイトノイズに近いかどうか)を確認するためによく使われます。
Ljung-Box検定以外のホワイトノイズ検定は?
ホワイトノイズを検定するための手法は、Ljung-Box検定以外にもいくつか存在します。以下に主なものを挙げます。
- Box-Pierce検定: Ljung-Box検定の前身であり、同様に時間序列データの自己相関を検定します。しかし、Ljung-Box検定と比較すると、Box-Pierce検定の方が大標本の場合にはパワーが少し劣ると一般に言われています。
- Durbin-Watson検定: 一次の自己相関を検定するための手法で、特に回帰分析の残差の自己相関を調べるために使われます。一次の自己相関がない場合、データはホワイトノイズであると解釈できます。
- Brock-Dechert-Scheinkman(BDS)検定: 高次元の埋め込み空間を利用してデータのランダム性を検定します。時間序列データがホワイトノイズであるかどうかだけでなく、特定の非線形構造を持つかどうかも検定します。
これらの検定はいずれもデータがホワイトノイズであるかどうかを検定しますが、検定の手法や仮定、解釈はそれぞれ異なる点に注意が必要です。