
- 問題
- 答え
- 解説
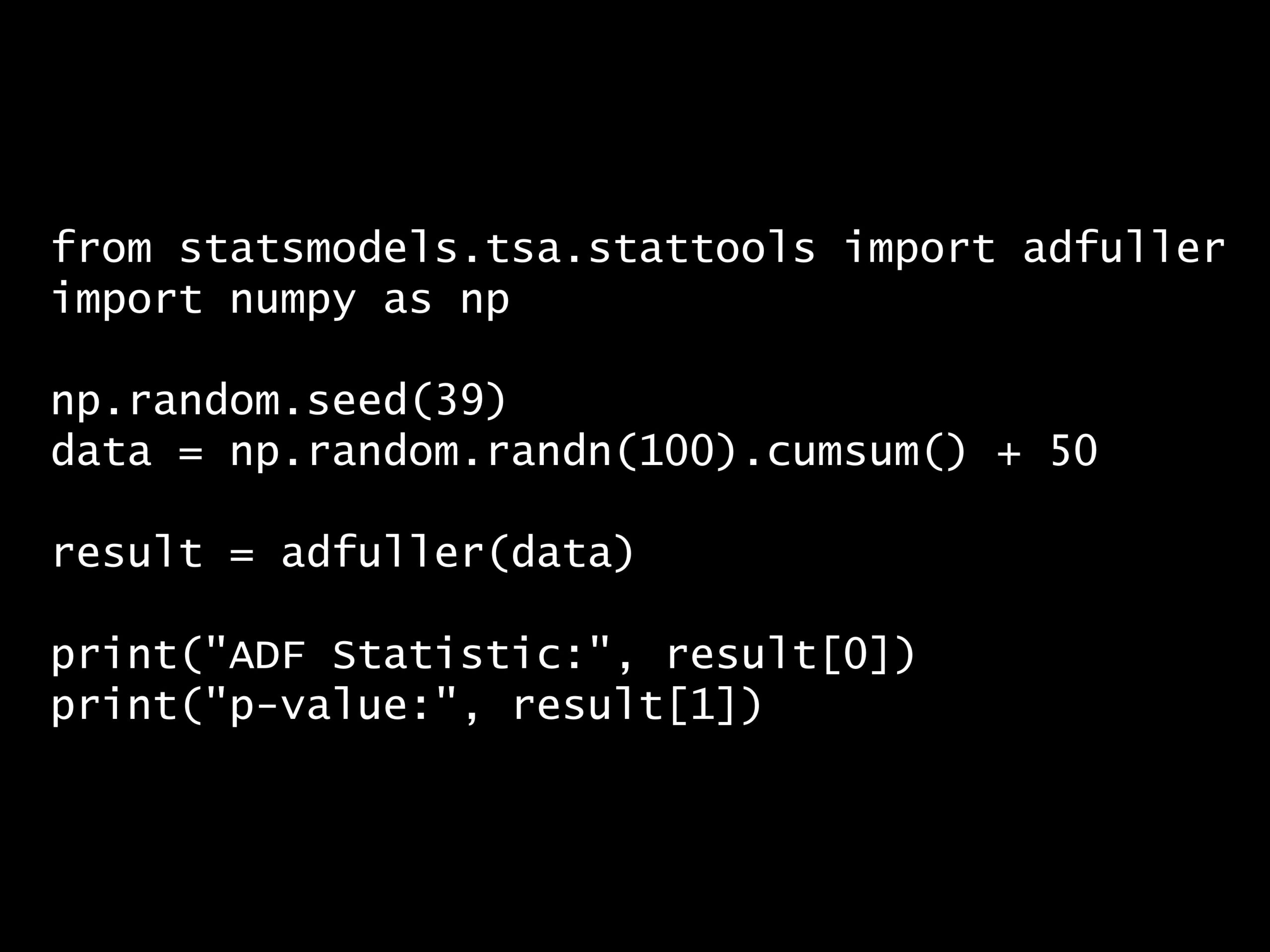
Python コード:
from statsmodels.tsa.stattools import adfuller
import numpy as np
np.random.seed(39)
data = np.random.randn(100).cumsum() + 50
result = adfuller(data)
print("ADF Statistic:", result[0])
print("p-value:", result[1])
回答の選択肢:
(A) p値が0.01未満
(B) p値が0.01以上0.05未満
(C) p値が0.05以上0.10未満
(D) p値が0.10以上
ADF Statistic: -2.3396066453266355 p-value: 0.1595119369898335
正解: (D)
回答の選択肢:
(A) p値が0.01未満
(B) p値が0.01以上0.05未満
(C) p値が0.05以上0.10未満
(D) p値が0.10以上
- コードの説明
-
このPythonコードは、Augmented Dickey-Fuller(ADF)単位根検定を使用して、時系列データが定常性を持つかどうかを確認します。Plain textCopy to clipboardOpen code in new windowEnlighterJS 3 Syntax Highlighterfrom statsmodels.tsa.stattools import adfullerimport numpy as npnp.random.seed(39)data = np.random.randn(100).cumsum() + 50result = adfuller(data)print("ADF Statistic:", result[0])print("p-value:", result[1])from statsmodels.tsa.stattools import adfuller import numpy as np np.random.seed(39) data = np.random.randn(100).cumsum() + 50 result = adfuller(data) print("ADF Statistic:", result[0]) print("p-value:", result[1])
from statsmodels.tsa.stattools import adfuller import numpy as np np.random.seed(39) data = np.random.randn(100).cumsum() + 50 result = adfuller(data) print("ADF Statistic:", result[0]) print("p-value:", result[1])ここでいう定常性とは、時系列データの統計的性質(平均、分散など)が時間に依存しない、つまり一定であるという特性を指します。時系列解析においては、データが定常であることが多くの手法の前提となります。
詳しく説明します。乱数を生成して累積和(ランダムウォーク)をとり(
np.random.randn(100).cumsum())、さらに50を加えてデータを生成します。Plain textCopy to clipboardOpen code in new windowEnlighterJS 3 Syntax Highlighternp.random.seed(39)data = np.random.randn(100).cumsum() + 50np.random.seed(39) data = np.random.randn(100).cumsum() + 50np.random.seed(39) data = np.random.randn(100).cumsum() + 50
dataに格納されているデータは次のようになっています。[51.40483957 51.62596061 51.4806333 51.60383247 52.20985944 54.63262946 52.71602092 50.29349383 50.93978804 51.14128868 50.9845755 51.75662126 50.39901134 51.10072872 52.15405338 52.4239603 51.45310603 52.50098782 53.72016882 53.66848884 52.56021713 52.89151843 51.52975494 51.64353462 52.20354556 54.16157236 56.22509867 56.80609487 57.80710169 58.34487442 57.42079127 54.75926082 55.54604084 56.04389418 56.30341673 55.41014862 54.43436597 53.39712711 53.80391005 53.13522982 53.73806975 53.12331036 52.23493434 53.52618036 52.82841507 52.08987208 53.0402611 53.13913576 52.74038688 53.48121018 52.32067683 51.27363428 49.51974975 48.54735023 48.46385875 49.07458744 50.17766962 49.06605537 49.58546089 50.37740559 49.78712077 50.12759942 52.82457507 52.06320665 53.05504352 52.41524423 52.7730816 53.44328433 53.32819627 53.85996849 55.38567959 55.50245337 55.53391367 55.29115683 57.49895379 57.39358845 57.65318171 58.6545045 57.36570041 56.18767287 54.88861853 55.73321841 54.46927512 54.32668836 54.4424543 55.22371047 54.80245478 53.78253043 53.66408101 53.13376732 54.4516446 53.9624122 52.98104594 52.48941835 53.3815674 53.84040852 52.68772299 52.28847447 52.58833974 52.63003315]
一般にランダムウォークは非定常過程に分類されます。データの作り方より、このデータに対するAugmented Dickey-Fuller(ADF)単位根検定の結果は、p値は大きな値をとり、帰無仮説(非定常)は棄却されません。
dataに対して、ADF検定を行います。adfuller(data)はADF統計量を計算し、p値の計算結果も含まれます。result = adfuller(data)
ADF統計量とp値を出力します。
Plain textCopy to clipboardOpen code in new windowEnlighterJS 3 Syntax Highlighterprint("ADF Statistic:", result[0])print("p-value:", result[1])print("ADF Statistic:", result[0]) print("p-value:", result[1])print("ADF Statistic:", result[0]) print("p-value:", result[1])ADF Statistic: -2.3396066453266355 p-value: 0.1595119369898335
- 単位根検定で定常性を調べられるのか?
-
Contents [hide]
ADF検定とは?
ADF検定(Augmented Dickey-Fuller test)は、時系列データが単位根過程(非定常)か定常過程を持つかを確認するための統計的検定方法の一つです。
「非定常」は、時系列データの統計的性質(平均、分散など)が時間によって変化する性質を指します。単位根を持つ時系列過程は一般的に非定常であり、その特性(例えば、平均や分散)は時間によって変化します。
多くの時系列解析手法はデータが定常性を持つことを前提としています。したがって、時系列データに対する分析を行う前に、ADF検定を用いてその定常性を確認することが重要となります。
具体的には、ADF検定は以下の仮説を検証します。
- 帰無仮説(H0):データに単位根が存在する(つまり、非定常である)
- 対立仮説(H1):データに単位根が存在しない(つまり、定常である)
ADF検定統計量のp値が所定の有意水準(例えば、0.05)未満であれば、帰無仮説を棄却して対立仮説を採択します。つまり、時系列データは定常であると結論づけられます。
それ以上(例えば、0.05以上)であれば帰無仮説を採択し、つまり時系列データは非定常であると結論づけられます。
非定常 ⊃ 単位根 ⊃ ランダウォーク
「非定常」は、時系列データの統計的性質(平均、分散など)が時間によって変化する性質を指します。それに対して、「定常」は統計的性質が時間によらず一定である特性を指します。
「単位根」は、非定常過程の一種を指し、特にその逐次的な変動が一定の値(単位根)を中心に変動する現象を指します。つまり、単位根を持つ過程は一般に非定常ですが、必ずしも全ての非定常過程が単位根を持つわけではありません。
「ランダムウォーク」も非定常過程の一つで、各時点での値がそれまでの値と一定の確率的な変動(ランダムな「歩み」)によって決まる過程を指します。ランダムウォークは単位根を持つ一例と言えますが、全ての単位根過程がランダムウォークであるわけではありません。
大まかな意味合い(単純化すると……)としては「非定常 ⊃ 単位根 ⊃ ランダムウォーク」であるとも言えます。
そのため、ADF検定のような単位根検定で「単位根がない」と判断されても、定常かどうか分かりません。単位根はないのに非定常な時系列データがあるからです。
単位根がないと判断されても、定常かどうか分からない
単位根検定(たとえばADF検定)は「単位根が存在するか否か」、すなわち「データが非定常かどうか」を検証するためのものであり、単位根が存在しないという結果が出ても、それは「データが定常である可能性が高い」事を意味するもので、「データが定常である」事を確定的に示すものではありません。
定常性はデータの平均および分散が時間に対して一定であり、どの時間点を選んでも同じ統計的特性を持つという状態を指します。
しかし、単位根検定が「単位根がない」(すなわち、データが非定常でない)を示しても、そのデータが全ての時点で一定の統計的特性を持つ(すなわち定常である)かどうかは、他の因子(季節性、サイクリックパターン動等)によっても影響されます。
したがって、単位根検定は時系列データが定常性を持つかどうかの一部を評価するのに役立つツールでありますが、総合的な評価を行うためには、他の手段(自己相関の確認等)の組み合わせも必要となることがあります。
このような理由から、「単位根がない」と言っても、必ずしもデータが定常であるわけではない、という事が言えるわけです。
単位根はないが非定常な例
単位根がない(つまり、ADF検定などで非定常でないと示される)が、それでも非定常となる時系列データの具体的な例として、「季節性を持つデータ」があります。
例えば、年間を通して一定のパターンを繰り返す売上データ(例えば、冬季にアイスクリームの売り上げが下がり、夏季に上がる等)のようなデータは、ADF検定では「単位根がない」、すなわち「非定常ではない」可能性があります。
しかし、これらのデータは季節性の影響により、その平均や分散が時間の経過とともに変動するため、実際には非定常な時系列データです。
このようなデータは、季節性の影響を取り除くために季節調整を行ったり、もしくは階差をとる等の前処理を行うことで、定常性を有するデータに変換することが可能です。
季節調整後に単位根検定を実施した方がいい
時系列データが季節性を持つ場合、その季節性はデータの統計的特性(例えば平均や分散)が時間的に変動する一因となります。これはデータが非定常であることを示す特徴です。
ですから、データが定常性を持つかどうかを確認するために単位根検定(例えばADF検定)を行う前に、季節調整を行って季節性の影響を取り除くことが推奨されます。
これにより、単位根検定の結果がその他の時系列性(例えばトレンドや自己相関)による非定常性により影響されるだけで、季節性による影響は排除されます。
したがって、季節調整を行った後に単位根検定を行うことで、より確実にデータの定常性を評価することが可能になります。
3つのAugmented Dickey-Fuller (ADF) 検定
ADF検定には実際、次の3つの主要なバリエーション(バージョン)があります。
扱っている時系列データの特性(例えば、データがトレンドを持つかどうか、定数項を持つかどうかなど)に基づいて選択する必要があります。
- ADF-NC(No Constant):時系列
- ADF-C(Constant):時系列
- ADF-CT(Constant and Trend):時系列
単位根検定以外の定常性の検定方法
単位根検定以外にも定常性を検定するための方法はいくつかあります。
KPSS (Kwiatkowski-Phillips-Schmidt-Shin)検定
データが定常過程(つまり、その期待値、分散、自己共分散が時間に依存しない)であるという帰無仮説を検定します。ADF検定とは逆に、ここでは非定常であることが対立仮説となります。ブロックブートストラップ法
有限ブロック長を持つデータのブートストラップ再サンプリングを行うことで定常過程の検定を行います。この方法は主に、データが大量にあり、かつ、周期性や他の時間依存性の特性を明示的に説明することが難しい場合に使用されます。