
- 問題
- 答え
- 解説
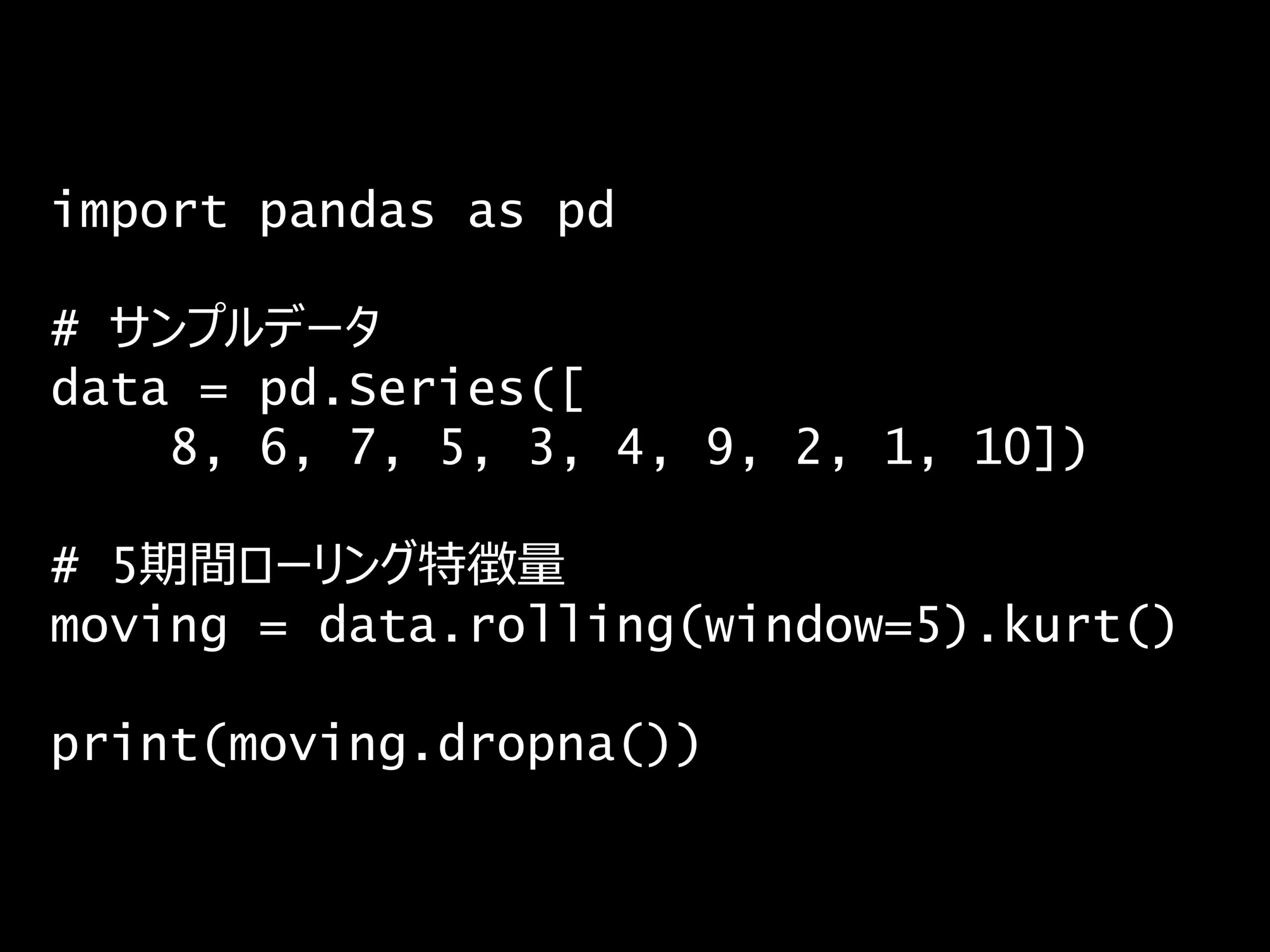
Python コード:
import pandas as pd
# サンプルデータ
data = pd.Series([
8, 6, 7, 5, 3, 4, 9, 2, 1, 10])
# 5期間ローリング特徴量
moving = data.rolling(window=5).kurt()
print(moving.dropna())
回答の選択肢:
(A) 移動平均
(B) 移動分散
(C) 移動尖度
(D) 移動歪度
4 -0.021914 5 -1.200000 6 -0.945303 7 2.021017 8 2.675098 9 -2.812220 dtype: float64
正解: (C)
回答の選択肢:
(A) 移動平均
(B) 移動分散
(C) 移動尖度
(D) 移動歪度
- コードの解説
-
このコードは、Pandasを使用してサンプルデータのシリーズに対して3期間のローリング尖度(kurtosis)を計算し、その結果を表示しています。Plain textCopy to clipboardOpen code in new windowEnlighterJS 3 Syntax Highlighterimport pandas as pd# サンプルデータdata = pd.Series([8, 6, 7, 5, 3, 4, 9, 2, 1, 10])# 5期間ローリング特徴量moving = data.rolling(window=5).kurt()print(moving.dropna())import pandas as pd # サンプルデータ data = pd.Series([ 8, 6, 7, 5, 3, 4, 9, 2, 1, 10]) # 5期間ローリング特徴量 moving = data.rolling(window=5).kurt() print(moving.dropna())
import pandas as pd # サンプルデータ data = pd.Series([ 8, 6, 7, 5, 3, 4, 9, 2, 1, 10]) # 5期間ローリング特徴量 moving = data.rolling(window=5).kurt() print(moving.dropna())詳しく説明します。
まず、6か月間の売上データをリストとして定義しています。
Plain textCopy to clipboardOpen code in new windowEnlighterJS 3 Syntax Highlightersales_data = [200, 210, 205, 220, 230, 240]sales_data = [200, 210, 205, 220, 230, 240]sales_data = [200, 210, 205, 220, 230, 240]
サンプルデータを
PandasのSeriesオブジェクトとして作成します。このSeriesは10個の整数値からなります。Plain textCopy to clipboardOpen code in new windowEnlighterJS 3 Syntax Highlighterdata = pd.Series([8, 6, 7, 5, 3, 4, 9, 2, 1, 10])data = pd.Series([8, 6, 7, 5, 3, 4, 9, 2, 1, 10])data = pd.Series([8, 6, 7, 5, 3, 4, 9, 2, 1, 10])
dataに格納されているデータは以下です。0 8 1 6 2 7 3 5 4 3 5 4 6 9 7 2 8 1 9 10 dtype: int64
dataの各要素に対して、ウィンドウサイズ5のローリング尖度を計算します。ローリング尖度は、指定されたウィンドウ内のデータの尖度(分布の鋭さ)を計算します。Plain textCopy to clipboardOpen code in new windowEnlighterJS 3 Syntax Highlightermoving = data.rolling(window=5).kurt()moving = data.rolling(window=5).kurt()moving = data.rolling(window=5).kurt()
計算結果からNaN(Not a Number)値を除外し(
.dropna())、結果を表示します。NaNは、ウィンドウサイズがデータの先頭部分に適用できないために発生します。Plain textCopy to clipboardOpen code in new windowEnlighterJS 3 Syntax Highlighterprint(moving.dropna())print(moving.dropna())print(moving.dropna())
4 -0.021914 5 -1.200000 6 -0.945303 7 2.021017 8 2.675098 9 -2.812220 dtype: float64
- ローリング(移動)特徴量とは?
-
ローリング(移動)特徴量とは、時系列データや連続データに対して、一定のウィンドウサイズ(期間)を設定し、そのウィンドウ内で計算される統計量や特徴量のことを指します。
これにより、データの局所的な変動や傾向を捉えることができます。
具体的には、以下のような特徴量がローリング(移動)特徴量として計算されることが多いです。
- 移動平均 (Moving Average): ウィンドウ内のデータの平均値(データの中心傾向)を計算します。データの平滑化やトレンドの把握に使用されます。
- 移動分散 (Moving Variance): ウィンドウ内のデータの分散(データのばらつき)を計算します。データの変動の大きさを把握するのに役立ちます。
- 移動標準偏差 (Moving Standard Deviation): ウィンドウ内のデータの標準偏差(データのばらつき)を計算します。データのばらつきを把握するのに役立ちます。
- 移動尖度 (Moving Kurtosis): ウィンドウ内のデータの尖度(分布の鋭さ)を計算します。データの分布の鋭さを把握するのに役立ちます。
- 移動歪度 (Moving Skewness): ウィンドウ内のデータの歪度(分布の非対称性)を計算します。データの分布の非対称性を把握するのに役立ちます。
- 移動最小値 (Moving Minimum): ウィンドウ内のデータの最小値を計算します。
- 移動最大値 (Moving Maximum): ウィンドウ内のデータの最大値を計算します。
これらのローリング特徴量を計算することで、データの局所的な特性を捉え、異常検知や予測モデルの精度向上に役立てることができます。
- rolling()メソッドとは?
-
Pandasの
rollingメソッドは、時系列データや連続データに対して、指定されたウィンドウサイズでローリング計算(移動計算)を行うために使用されます。これにより、データの局所的な統計量や特徴量を計算することができます。
以下は
rollingメソッドの主な引数です。window: 計算に使用するウィンドウサイズを指定します。整数値を指定します。>min_periods: 計算に必要な最小の観測値の数を指定します。デフォルトはwindowと同じです。center: ウィンドウを中心に配置するかどうかを指定します。デフォルトはFalseです。win_type: ウィンドウのタイプを指定します。デフォルトはNoneです。on: 計算に使用する列を指定します。デフォルトはNoneです。axis: 計算に使用する軸を指定します。デフォルトは0です。closed: ウィンドウのどの端点を含むかを指定します。デフォルトはrightです。
以下は、
rollingメソッドを使用して移動平均を計算する例です。Plain textCopy to clipboardOpen code in new windowEnlighterJS 3 Syntax Highlighterimport pandas as pd# サンプルデータdata = pd.Series([8, 6, 7, 5, 3, 4, 9, 2, 1, 10])# 3期間ローリング平均の計算moving_avg = data.rolling(window=3).mean()print(moving_avg)import pandas as pd # サンプルデータ data = pd.Series([8, 6, 7, 5, 3, 4, 9, 2, 1, 10]) # 3期間ローリング平均の計算 moving_avg = data.rolling(window=3).mean() print(moving_avg)import pandas as pd # サンプルデータ data = pd.Series([8, 6, 7, 5, 3, 4, 9, 2, 1, 10]) # 3期間ローリング平均の計算 moving_avg = data.rolling(window=3).mean() print(moving_avg)
以下、結果です。
0 NaN 1 NaN 2 7.000000 3 6.000000 4 5.000000 5 4.000000 6 5.333333 7 5.000000 8 4.000000 9 4.333333 dtype: float64
この例では、ウィンドウサイズ3で移動平均を計算しています。最初の2つの値はウィンドウサイズに満たないため
NaNとなり、それ以降の値はウィンドウ内の平均値が計算されます。
center=Trueとし、ウィンドウを中心に配置し計算します。以下、コードです。
Plain textCopy to clipboardOpen code in new windowEnlighterJS 3 Syntax Highlighter# サンプルデータdata = pd.Series([8, 6, 7, 5, 3, 4, 9, 2, 1, 10])# 3期間ローリング平均の計算moving_avg = data.rolling(window=3,center=True).mean()print(moving_avg)# サンプルデータ data = pd.Series([8, 6, 7, 5, 3, 4, 9, 2, 1, 10]) # 3期間ローリング平均の計算 moving_avg = data.rolling(window=3,center=True).mean() print(moving_avg)# サンプルデータ data = pd.Series([8, 6, 7, 5, 3, 4, 9, 2, 1, 10]) # 3期間ローリング平均の計算 moving_avg = data.rolling(window=3,center=True).mean() print(moving_avg)
以下、結果です。
0 NaN 1 7.000000 2 6.000000 3 5.000000 4 4.000000 5 5.333333 6 5.000000 7 4.000000 8 4.333333 9 NaN dtype: float64
closed='left'とし、ウィンドウを中心に配置し計算します。以下、コードです。
Plain textCopy to clipboardOpen code in new windowEnlighterJS 3 Syntax Highlighter# サンプルデータdata = pd.Series([8, 6, 7, 5, 3, 4, 9, 2, 1, 10])# 3期間ローリング平均の計算moving_avg = data.rolling(window=3,closed='left').mean()print(moving_avg)# サンプルデータ data = pd.Series([8, 6, 7, 5, 3, 4, 9, 2, 1, 10]) # 3期間ローリング平均の計算 moving_avg = data.rolling(window=3,closed='left').mean() print(moving_avg)# サンプルデータ data = pd.Series([8, 6, 7, 5, 3, 4, 9, 2, 1, 10]) # 3期間ローリング平均の計算 moving_avg = data.rolling(window=3,closed='left').mean() print(moving_avg)
以下、結果です。
0 NaN 1 NaN 2 NaN 3 7.000000 4 6.000000 5 5.000000 6 4.000000 7 5.333333 8 5.000000 9 4.000000 dtype: float64
色々な統計量で求めてみます。
以下、コードです。
Plain textCopy to clipboardOpen code in new windowEnlighterJS 3 Syntax Highlighterimport pandas as pd# サンプルデータdata = pd.Series([8, 6, 7, 5, 3, 4, 9, 2, 1, 10])# 3期間ローリング特徴量moving_avg = data.rolling(window=5).mean()moving_var = data.rolling(window=5).var()moving_std = data.rolling(window=5).std()moving_skew = data.rolling(window=5).skew()moving_min = data.rolling(window=5).min()moving_max = data.rolling(window=5).max()moving_kurt = data.rolling(window=5).kurt()# 結果をまとめて表示df = pd.DataFrame({'data': data,'moving_avg': moving_avg,'moving_var': moving_var,'moving_std': moving_std,'moving_skew': moving_skew,'moving_min': moving_min,'moving_max': moving_max,'moving_kurt': moving_kurt})print(df.dropna())import pandas as pd # サンプルデータ data = pd.Series([8, 6, 7, 5, 3, 4, 9, 2, 1, 10]) # 3期間ローリング特徴量 moving_avg = data.rolling(window=5).mean() moving_var = data.rolling(window=5).var() moving_std = data.rolling(window=5).std() moving_skew = data.rolling(window=5).skew() moving_min = data.rolling(window=5).min() moving_max = data.rolling(window=5).max() moving_kurt = data.rolling(window=5).kurt() # 結果をまとめて表示 df = pd.DataFrame({ 'data': data, 'moving_avg': moving_avg, 'moving_var': moving_var, 'moving_std': moving_std, 'moving_skew': moving_skew, 'moving_min': moving_min, 'moving_max': moving_max, 'moving_kurt': moving_kurt }) print(df.dropna())import pandas as pd # サンプルデータ data = pd.Series([8, 6, 7, 5, 3, 4, 9, 2, 1, 10]) # 3期間ローリング特徴量 moving_avg = data.rolling(window=5).mean() moving_var = data.rolling(window=5).var() moving_std = data.rolling(window=5).std() moving_skew = data.rolling(window=5).skew() moving_min = data.rolling(window=5).min() moving_max = data.rolling(window=5).max() moving_kurt = data.rolling(window=5).kurt() # 結果をまとめて表示 df = pd.DataFrame({ 'data': data, 'moving_avg': moving_avg, 'moving_var': moving_var, 'moving_std': moving_std, 'moving_skew': moving_skew, 'moving_min': moving_min, 'moving_max': moving_max, 'moving_kurt': moving_kurt }) print(df.dropna())以下、結果です。
data moving_avg moving_var moving_std moving_skew moving_min \ 4 3 5.8 3.7 1.923538 -0.590129 3.0 5 4 5.0 2.5 1.581139 0.000000 3.0 6 9 5.6 5.8 2.408319 0.601364 3.0 7 2 4.6 7.3 2.701851 1.338504 2.0 8 1 3.8 9.7 3.114482 1.549131 1.0 9 10 5.2 16.7 4.086563 0.347275 1.0 moving_max moving_kurt 4 8.0 -0.021914 5 7.0 -1.200000 6 9.0 -0.945303 7 9.0 2.021017 8 9.0 2.675098 9 10.0 -2.812220
自分で定義したカスタム統計量でも求めることができます。
以下、コードです。
Plain textCopy to clipboardOpen code in new windowEnlighterJS 3 Syntax Highlighterimport pandas as pddata = pd.Series([8, 6, 7, 5, 3, 4, 9, 2, 1, 10])# カスタム統計量の定義 (ここでは「標本範囲 = 最大値 - 最小値」を定義)def custom_function(x):value = x.max() - x.min()return value# 3期間ローリング特徴量moving_range = data.rolling(window=3).apply(custom_function)print(moving_range)import pandas as pd data = pd.Series([8, 6, 7, 5, 3, 4, 9, 2, 1, 10]) # カスタム統計量の定義 (ここでは「標本範囲 = 最大値 - 最小値」を定義) def custom_function(x): value = x.max() - x.min() return value # 3期間ローリング特徴量 moving_range = data.rolling(window=3).apply(custom_function) print(moving_range)import pandas as pd data = pd.Series([8, 6, 7, 5, 3, 4, 9, 2, 1, 10]) # カスタム統計量の定義 (ここでは「標本範囲 = 最大値 - 最小値」を定義) def custom_function(x): value = x.max() - x.min() return value # 3期間ローリング特徴量 moving_range = data.rolling(window=3).apply(custom_function) print(moving_range)以下、結果です。
0 NaN 1 NaN 2 2.0 3 2.0 4 4.0 5 2.0 6 6.0 7 7.0 8 8.0 9 9.0 dtype: float64