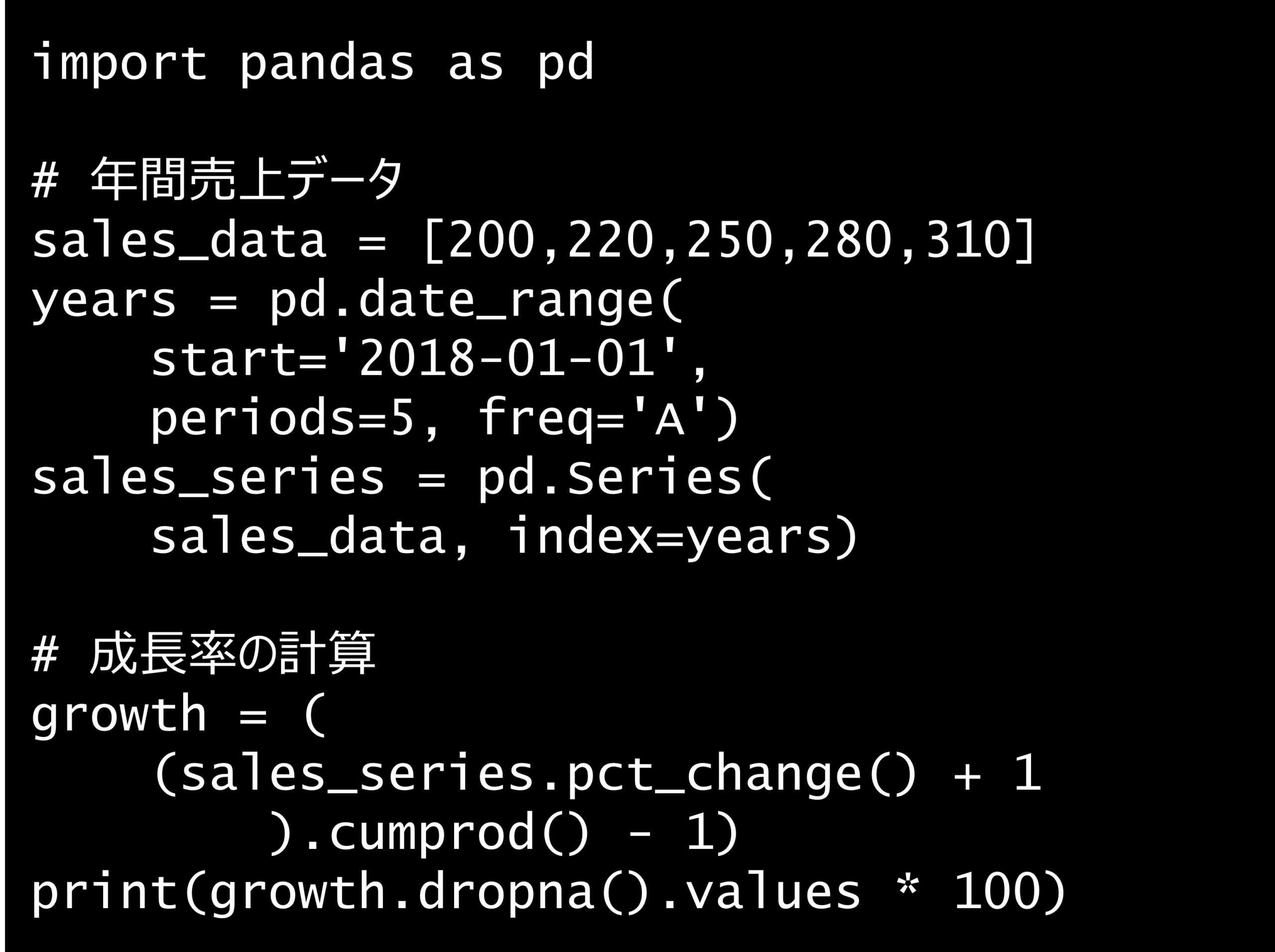
問題 答え 解説 次の Python コードの出力はどれでしょうか? Python コード: import pandas as pd # 年間売上データ sales_data = [200,220,250,28...
機械学習モデルの開発において、モデルの性能を適切に評価することは非常に重要です。 評価指標は、モデルの予測性能を定量的に測定し、モデルの選択、比較、改善に役立ちます。 しかし、多様な評価指標の中から、どの指標を使うべきか...
因果推論は、因果関係を理解し、その影響を予測するための重要な分析手法です。 特にDAG(有向非巡回グラフ)は、複雑な因果関係を視覚化し、交絡因子やバックドア基準を特定するために重要です。 今回は、PythonのCausa...
データドリブンな意思決定がビジネスや政策、医療など多くの分野で重要視される現代において、因果効果の推定は欠かせない手法です。 因果効果を正確に推定することで、特定の施策が実際に期待される結果をもたらすかどうかを理解し、効...
前編では、交絡バイアスの特定と対処の方法に焦点を当て、有向非巡回グラフ(DAG)を使用してこれらのバイアスを可視化し、対処する方法を簡単に説明しました。 第386話|DAG(因果ダイアグラム)で識別したバイアスの対処手法...
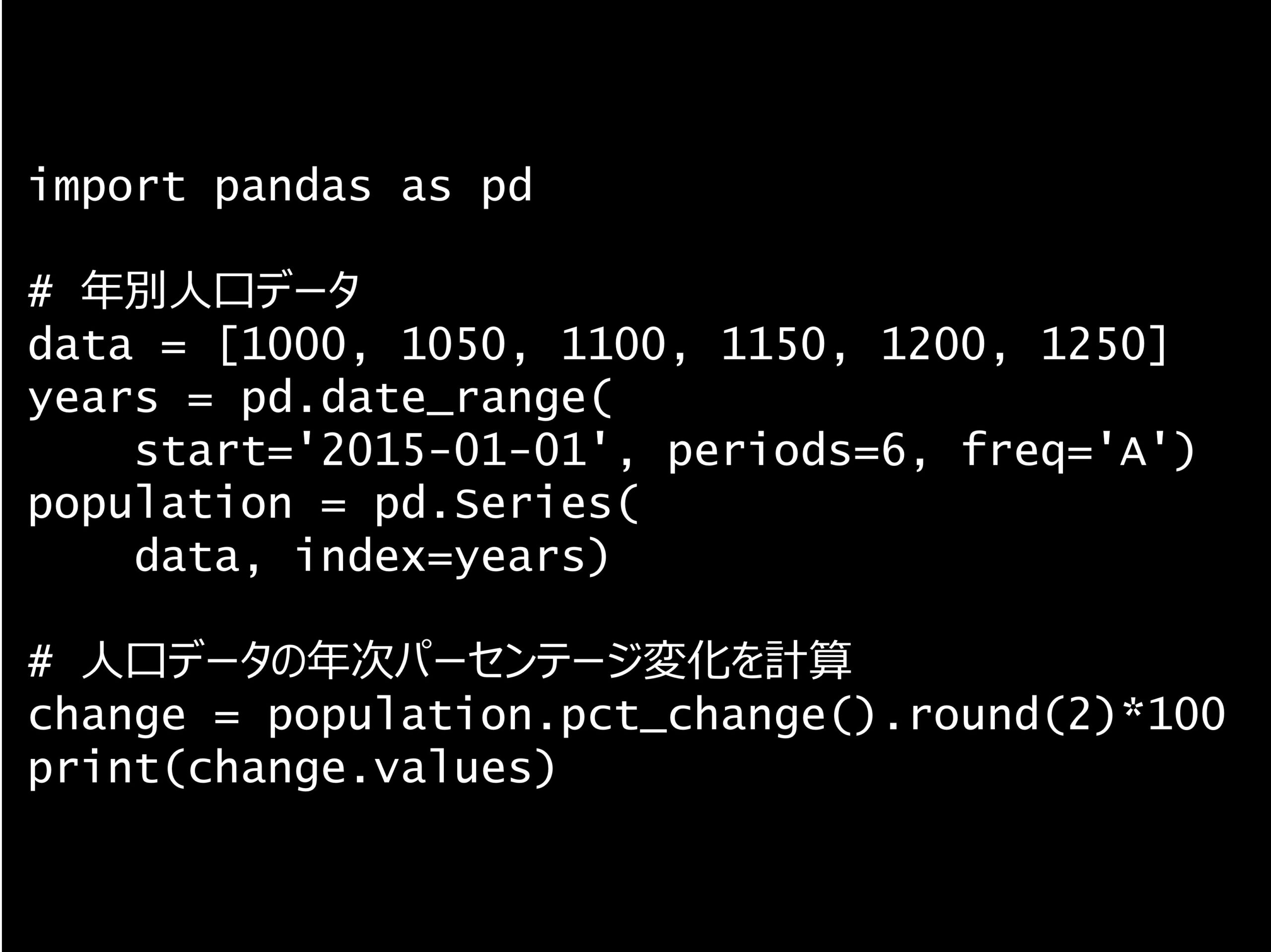
問題 答え 解説 次の Python コードの出力はどれでしょうか? Python コード: import pandas as pd # 年別人口データ data = [1000, 1050, 1100, 11...
交絡バイアスは、因果関係を探求する上での大きな障害の一つです。 この交絡バイアスは、調査対象の原因と結果の関係に、第三の変数が影響を与えている状況で生じます。 例えば、あるマーケティングキャンペーンが売上に影響を与えたと...
時系列分析は、過去のデータから未来を予測する重要な手段です。経済、金融、気象予報など多岐にわたる分野で用いられ、データの時間的な変動を捉えることで、より正確な意思決定をサポートします。 説明変数を時系列モデルに組み込むこ...
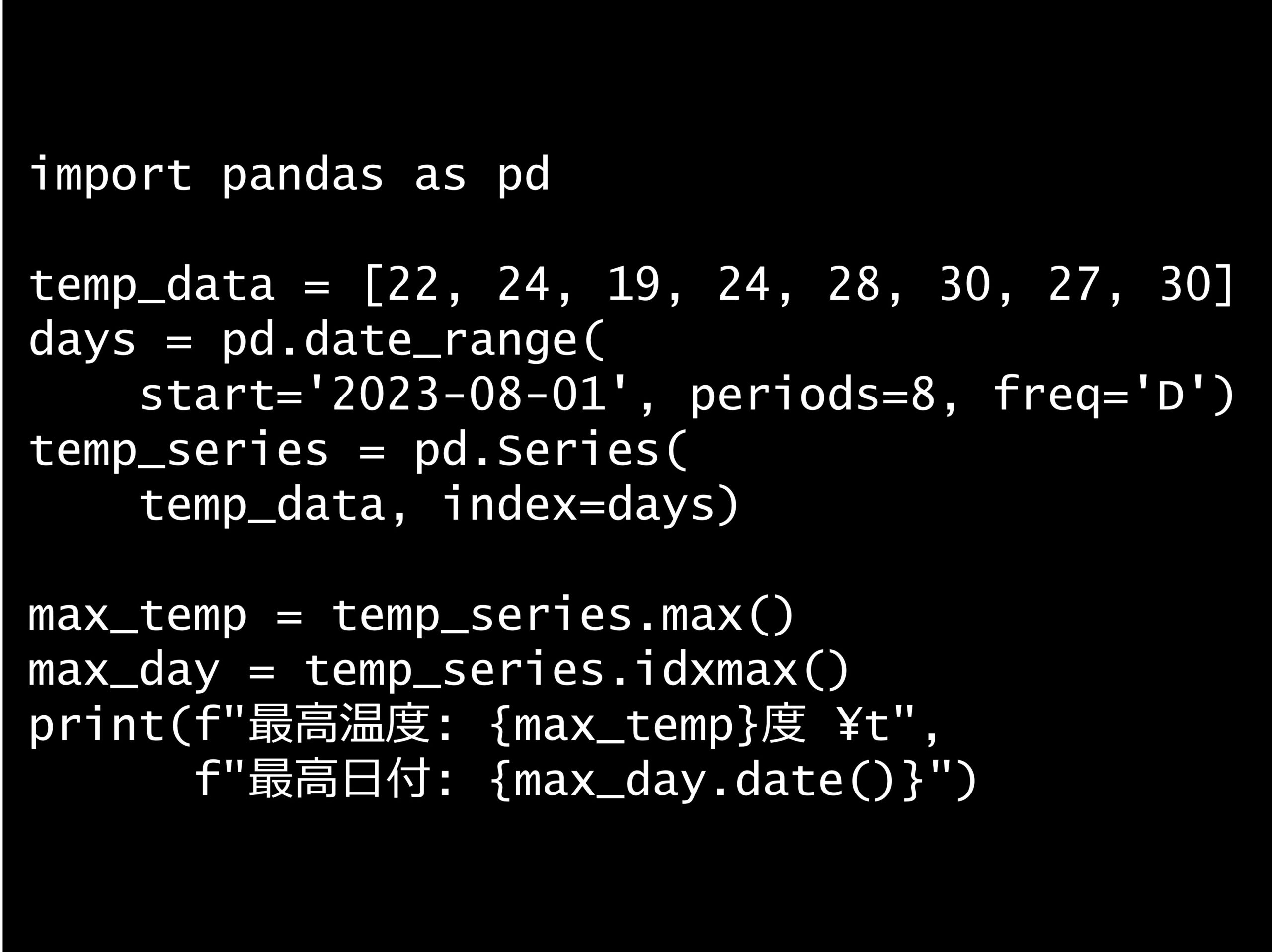
問題 答え 解説 次の Python コードの出力はどれでしょうか? Python コード: import pandas as pd temp_data = [22, 24, 19, 24, 28, 30, 2...
ビジネスの意思決定において、不確実性は避けられない課題です。 従来の統計手法では、この不確実性を十分に考慮できないことがあります。そこで注目されているのが、ベイズモデリングです。 ベイズモデリングは、統計学と機械学習の分...
非線形計画問題の大域的最適化は、工学や経済学など様々な分野で重要な役割を果たしています。特に、問題の規模が大きくなると、局所的な最適解ではなく、大域的な最適解を見つけることが求められます。 これまでの連載では、Pytho...
データを活用したマーケティング戦略は、ビジネスの成功に不可欠です。その中心に位置するのが、マーケティングミックスモデリング(MMM)です。 マーケティングミックスモデリング(MMM)は、過去のデータを分析する「振り返り分...
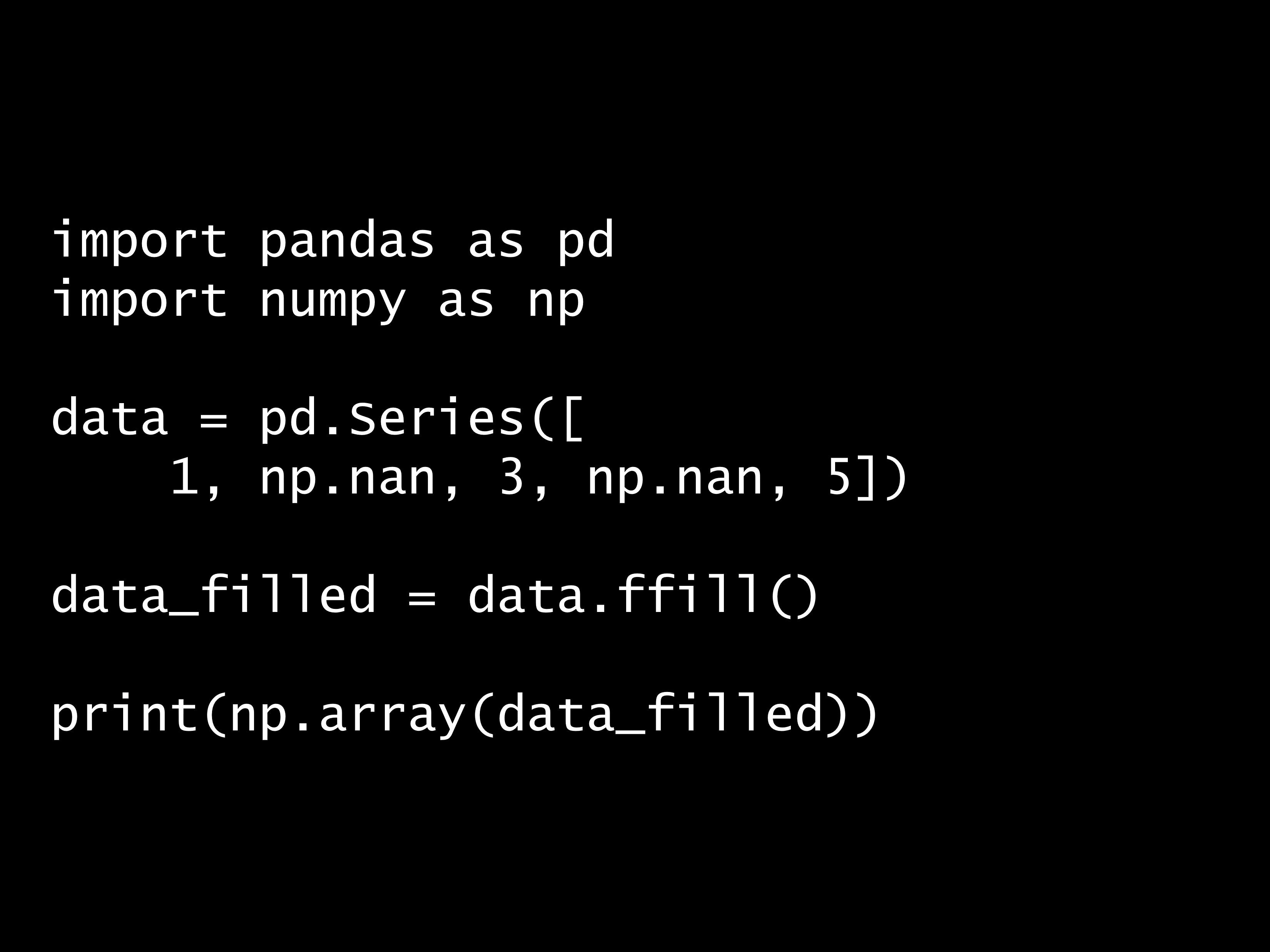
問題 答え 解説 次の Python コードの出力はどれでしょうか? Python コード: import pandas as pd import numpy as np data = pd.Series([1...
前回の記事では、因果推論の基礎とDAG(有向非巡回グラフ)の読み方について解説しました。因果関係と単なる関連性の違いを理解し、DAGを使って因果関係の構造を可視化する方法を学びました。 第383話|ビジネスパーソンのため...
本連載では、Pythonを用いた非線形計画問題の大域的最適化手法について、これまで3回にわたって解説してきました。 第1回では非線形計画問題と大域的最適化の基礎的な概念を取り上げました。 第2回ではメタヒューリスティクス...
デジタル化の波が押し寄せる中で、ビジネスにおけるデータの重要性はますます高まっています。 特に、時系列データは経済指標、株価、気象情報など、あらゆる分野で収集されており、その分析から得られる洞察は企業の意思決定を大きく左...