データを集めたら、次にデータを分析しなければなりません。 集めたデータと分析の関係は、食材と料理の関係に似ています。良い食材であっても料理人の腕に問題があると台無しになることがあります。不十分な食材でも調理しだいで美味し...
scikit-learnなどで構築した機械学習モデル(オブジェクト)を、どのようにファイルに保存し、それを読み込み使うのか。 よくあるのが以下の2つです。 pickle:保存&読み込むスピードがjoblibより早い jo...
なぜお金を使おうとするのだろうか? 行政機関もそうですが、大手企業も似たようなものだと感じているのが、お金をかけなくてもいいところに、お金をかけようとする。 例えば、「1円も払わずに社内に構築できるITシステム(データ利...
最近、機械学習系の数理モデルを構築する人も増えてきています。PythonですとScikit-Learn(sklearn)を使う人が多いようです。 では、Rではどうか? となりますが、Rで似たようなものですと、Caret(...
TPOTは、最適な機械学習の一連の流れ(パイプライン)を自動で構築する自動機械学習(AutoML)です。 では、どのようにして最適なパイプラインを得るのでしょうか? あらゆるパイプラインの構築パターンを試せば、最適なパイ...
EDA(探索的データ分析)と称して、大量のグラフを作成し意味のあるグラフを探しながら見ていくという作業は、昔から行われてきました。 その作業が少しでも楽でにでもなれば、ということで Lux というPythonライブラリー...
「鉛筆を舐めておけ文化」とは、数値の改ざんが当たり前のごとく行われている文化です。 データを活用し社会をより良くするDXとは、真逆の文化です。 DXを推進しながら、「鉛筆を舐めておけ文化」である組織は、その文化から脱却し...
Power BI に読み込んだデータが、そのまますぐに使える状態になっているわけではありません。 何かしらの加工が必要になることがあります。例えば、列を分割したり、不要な行を削除したり、などなど。 今回は次の3つについて...
Rでグラフ作成と言えば、ggplot2です。 ただ、ggplot2による可視化は綺麗だけど、その設定がちょっと面倒。もっとさくっとグラフ作成できなものだろうか。 と言うことで、パッケージ「ggplotgui」「esqui...
データを集めたら、次にデータを分析しなければなりません。 集めたデータと分析の関係は、食材と料理の関係に似ています。良い食材であっても料理人の腕に問題があると台無しになることがあります。不十分な食材でも調理しだいで美味し...
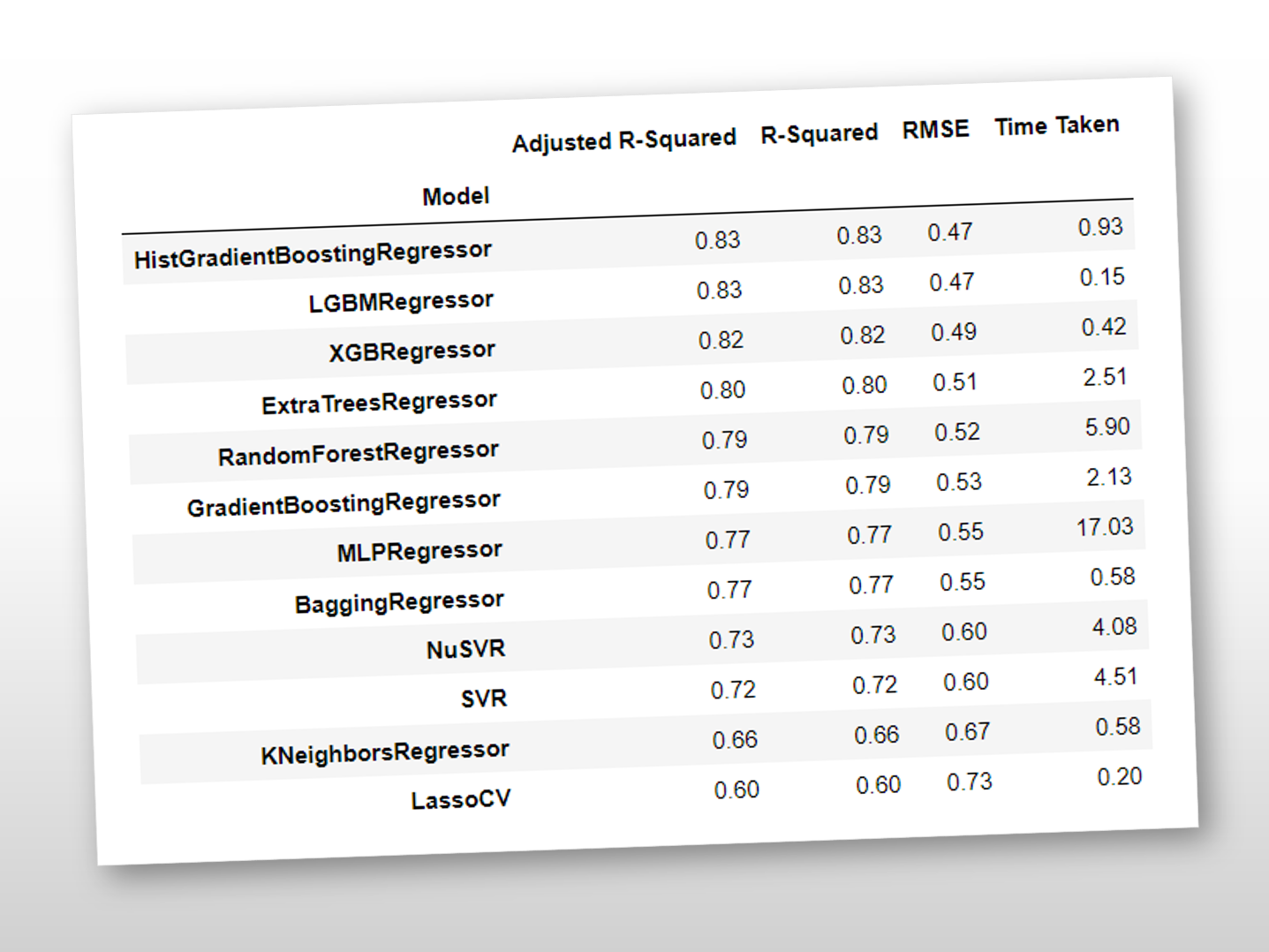
回帰問題や分類問題の予測モデルを構築するときに、色々なアルゴリズムで構築し比べたことがあるかと思います。 AutoML(自動機械学習)というわけではないですが、PythonのLazy Predictを使うと、1コードで色...
世の中不思議なもので、誰も嬉しくもないし、得もしていないのに止められないことがあります。 その1つが、DX(デジタルトランスフォーメーション)を旗印に掲げ始めた無意味なデータ活用です。 DXを旗印のもと始めたデータ活用が...
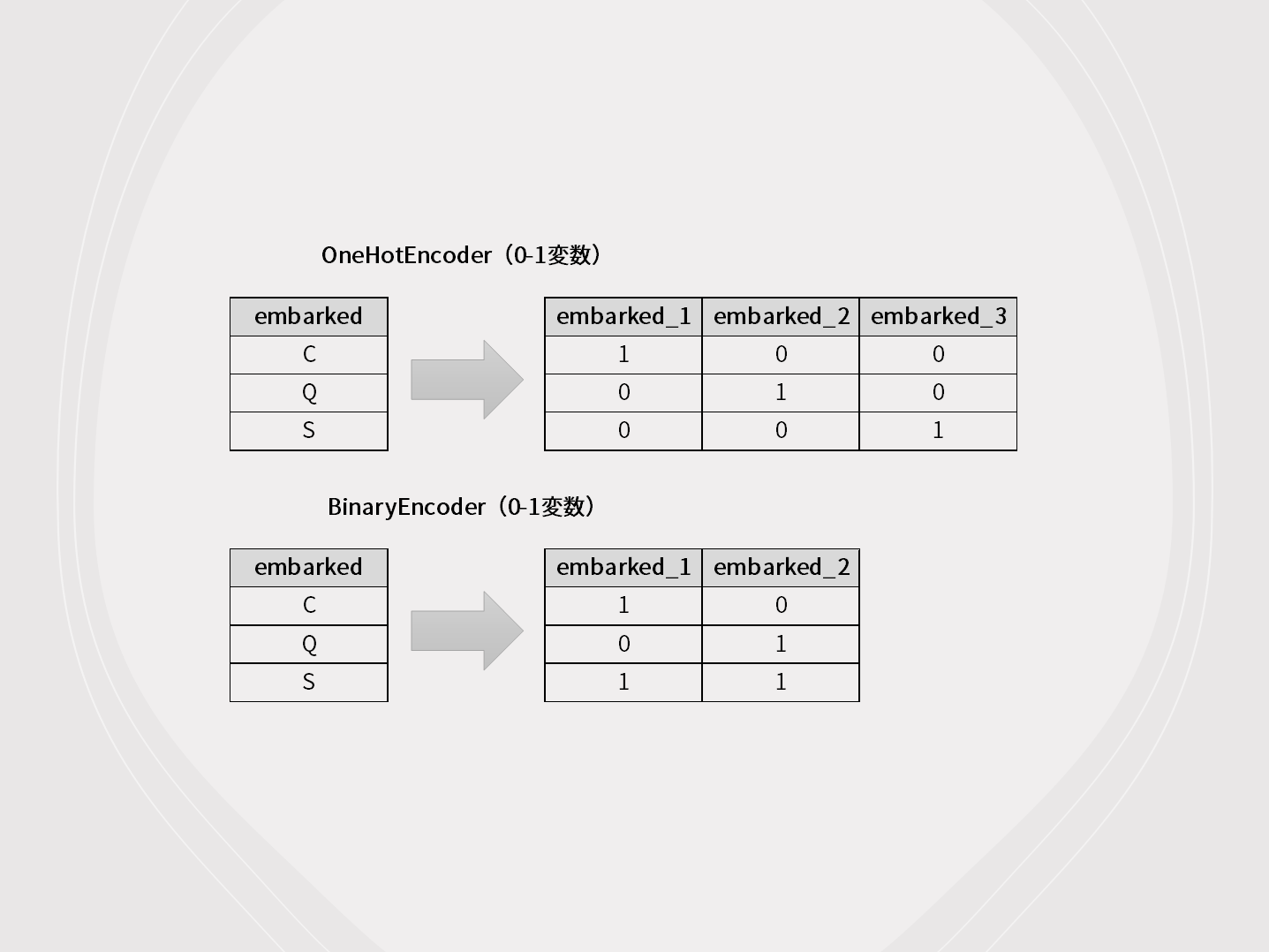
カテゴリカル変数は、数字で表現されているケースと、文字列で表現されているケースが多いです。 文字列で表現されているケースの場合、そのままモデル構築するとエラーが出ることも多いです。 そのような場合、文字列を数字にエンコー...
何事にも始まりが必ずあるように、多くの食べ物は、誰かが最初に口にしたはずです。 例えば、多くの野菜やキノコも同様でしょう。 集めたデータと分析の関係は、食材と料理の関係に似ています。 今回は、「あなたは、誰も食べたことの...
データ分析や予測モデル構築などをやってみたいが…… RやPythonだとの無料ツールはコーディングスキルがそれなりに必要になりハードルがある 有料ツールのSASやSPSSなどは使いやすそうだけど高額すぎる。 無料で使える...
Power BI でデータを読み込んだとき、行と列を入れ替えたいと思うときがあるかもしれません。 今回は、データを読み込んだ後に、Power BI 上でデータの行と列の入れ替える方法について説明します。 以下、今回の流れ...