集めるデータのイメージが付いたら、次にデータを集めなければなりません。 データ集める際にデータ品質が高いのが理想です。データ品質が低いと、後々のデータ分析やアクションなどに悪い影響を及ぼします。 データ品質を決めるのは、...
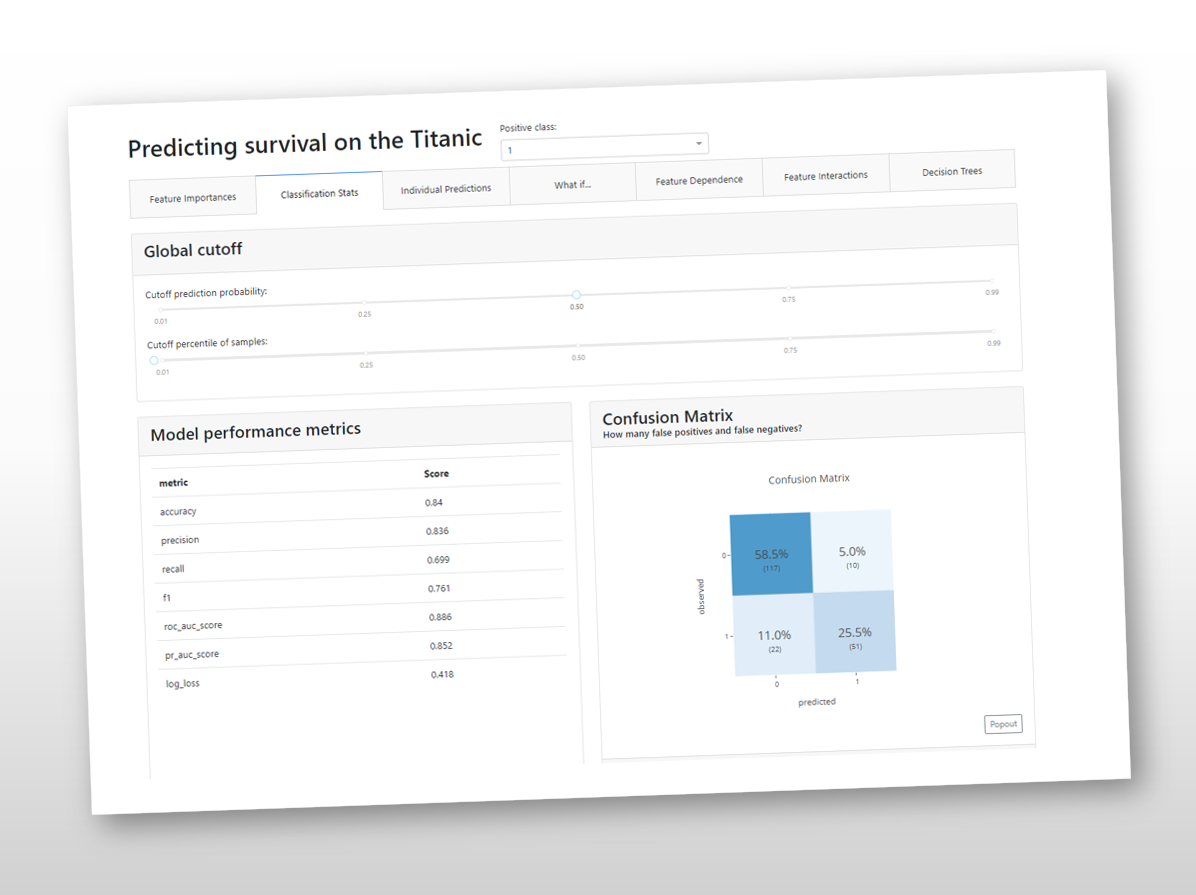
ビジネスでデータ活用をするとき、何かを予測をするために、数理統計学や機械学習などの数理モデル(分類問題・回帰問題)を構築することは、少なくありません。 例えば…… 売上予測 受注予測 離反予測 アップセル予測 クロスセル...
データ活用をするとき、「見える化」というキーワードが多々出てきます。 取り急ぎ「見える化」するためにデータを集めよう DX(デジタルトランスフォーメーション)の初手として「見える化」から始めましょう データ環境を整備し「...
スタッキングは機械学習のアンサンブル学習の一つです。複数の学習器の出力を特徴量とし、さらに別の学習器で予測する方法です。 TPOTのスタッキングは、指定のアルゴリズムで予測した結果とそのアルゴリズムに入力した特徴量を組み...
集めるデータのイメージが付いたら、次にデータを集めなければなりません。 データ集める際にデータ品質が高いのが理想です。データ品質が低いと、後々のデータ分析やアクションなどに悪い影響を及ぼします。 データ品質を決めるのは、...
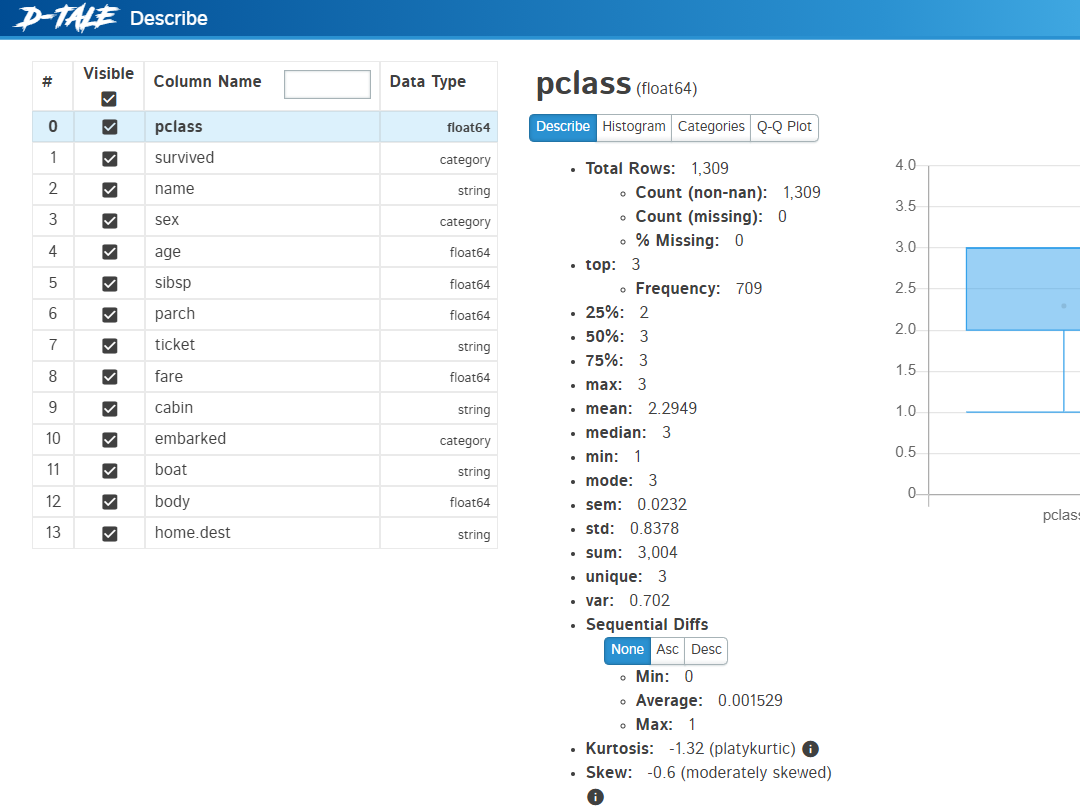
データセット手にしたら、数理モデルを作ったりする前に、通常はEDA(探索的データ分析)を実施します。 端的に言うと、データと仲良くなるための会話です。 ざっくり次のような流れになります。 データコンディションチェック(欠...
各報道機関の選挙速報で、よく開票率が数%なのに当確(当選確実)が出ることがあります。 データサイエンスっぽいアプローチとしては…… 出口調査を利用したもの 中間投票状況(開票率○○%)の結果を利用したもの ……を利用した...
第9回「AutoML【TPOT】のパイプラインに使われる関数一覧」で、TPOTのパイプライン(特徴量生成・予測)で使われる関数の概要を説明しました。 その中には、TPOT独自の関数がいくつかありました。 分類問題・回帰問...
集めるデータのイメージが付いたら、次にデータを集めなければなりません。 データ集める際にデータ品質が高いのが理想です。データ品質が低いと、後々のデータ分析やアクションなどに悪い影響を及ぼします。 データ品質を決めるのは、...
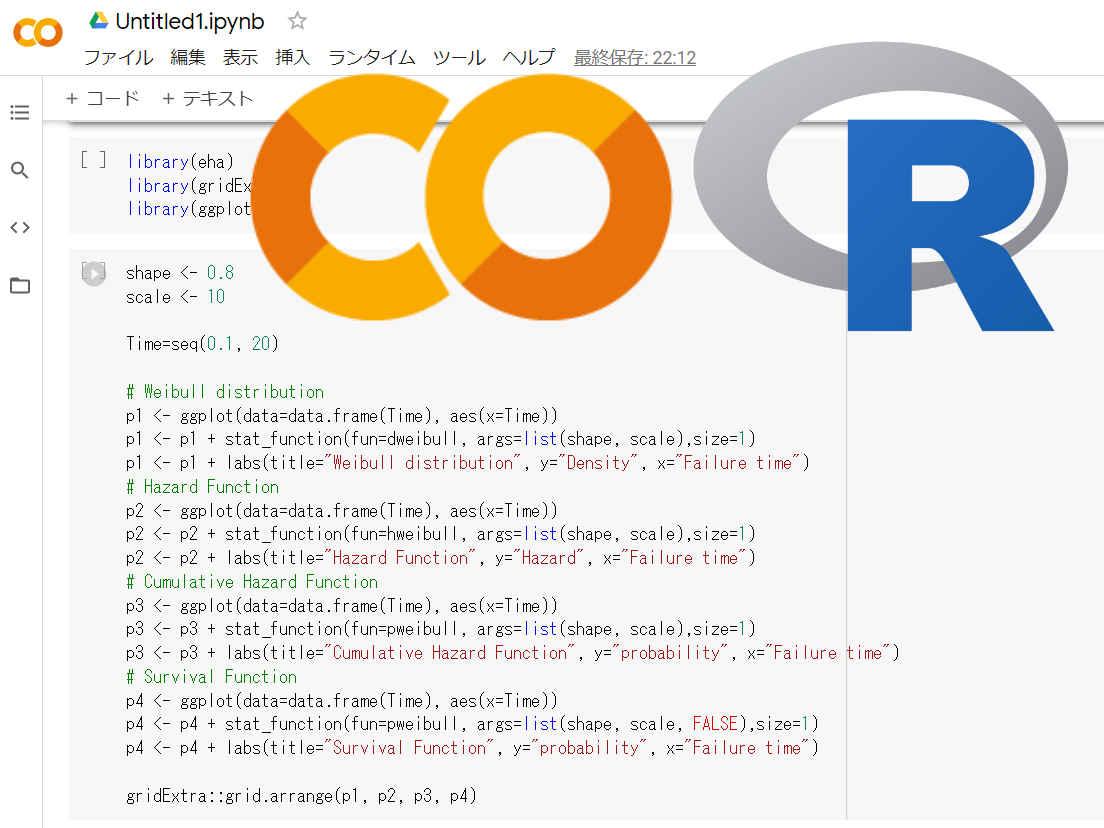
Google Colaboratoryは、ブラウザから Python や R を実行できるサービスです。Jupyter Notebook のように使えます。 何も考えずにGoogle Colaboratory上でノートブ...
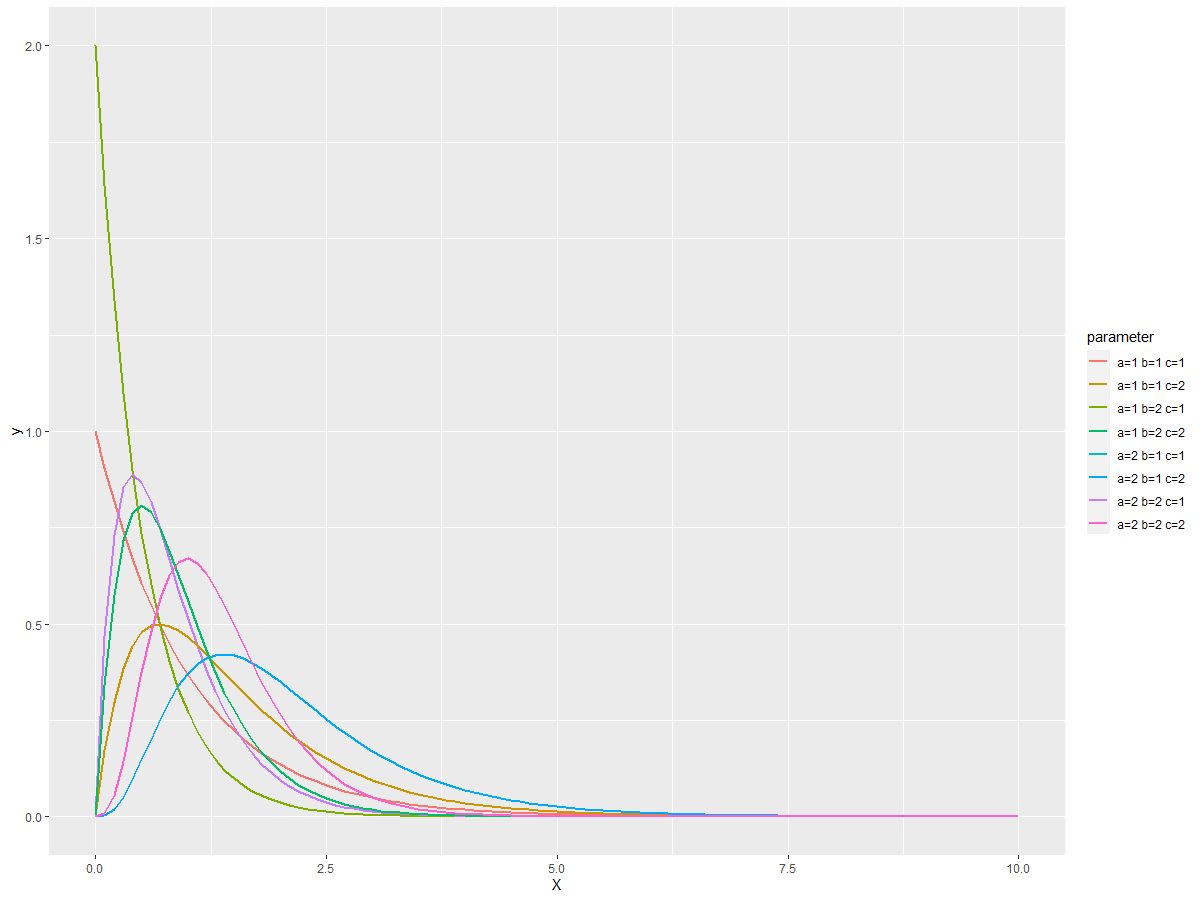
営業活動やマーケティング活動にとって、顧客の離反対策は重要課題の1つでしょう。 顧客の離反などのイベントが発生するまでの期間を扱う分析手法があります。 生存時間分析(survival time analysis)というも...
第9回「AutoML【TPOT】のパイプラインに使われる関数一覧」で、TPOTのパイプライン(特徴量生成・予測)で使われる関数の概要を説明しました。 その中には、TPOT独自の関数がいくつかありました。 分類問題・回帰問...
「第222話|パレート指数による売上分析」でパレート分布についてお話ししました。 ビジネスはパレートな世界の住人でしょう。 例えば…… チェーン店であれば、極端に売上の大きい店舗はあります 営業パーソンであれば、極端に受...
集めるデータのイメージが付いたら、次にデータを集めなければなりません。 データ集める際にデータ品質が高いのが理想です。データ品質が低いと、後々のデータ分析やアクションなどに悪い影響を及ぼします。 データ品質を決めるのは、...
所得分布の不均衡を研究したヴィルフレド・パレート(Vilfredo Pareto)から名付けられた、パレートの法則(20:80の法則もしくは80:20の法則)と呼ばれるものがあります。 この法則は…… 売上上位20%の商...
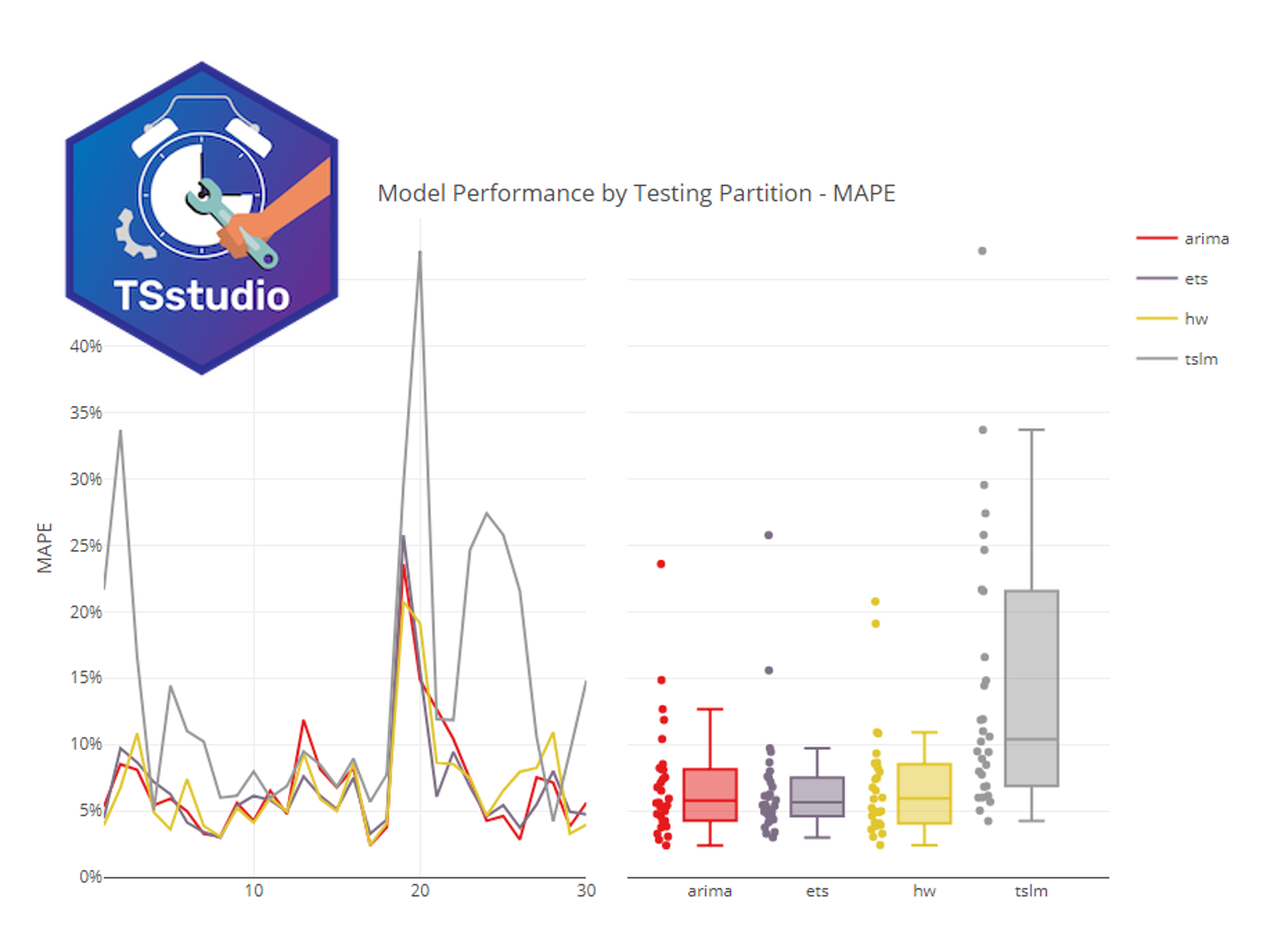
ビジネス系データサイエンスの多くは、時系列データです。 RのTSstudioパッケージを使うと、サクッと時系列解析できます。「TSstudio」の「TS」はTime Series(時系列)の略です。 RのTSstudio...