

TPOTをはじめとした「自動機械学習」(AutoML)が実施するのは、以下の2点です。
- 変換器(特徴量の生成と選択)の生成
- 予測器(予測モデル)の生成
自動機械学習(AutoML)によっては、予測モデルの生成のみのものもあります。
特徴量の生成と予測モデルの生成をつなげたものを、「パイプライン」(pipeline)と言います。
今回は、このあたりのお話しを、TPOTを題材にしてお話しします。
Contents [hide]
パイプライン処理
「パイプライン」(pipeline)は、「自動機械学習」(AutoML)独自の用語ではありません。
「パイプライン」というキーワードは、色々な分野で使われています。今回の「パイプライン」(pipeline)は、「パイプライン処理」と呼ばれるコンピュータ用語です。
パイプライン処理とは、複数の処理プログラムを直列に連結し、ある処理プログラムの出力が次の処理プログラムの入力となるようにし、複数の処理プログラムを並行処理させる技術です。
「自動機械学習」(AutoML)の場合
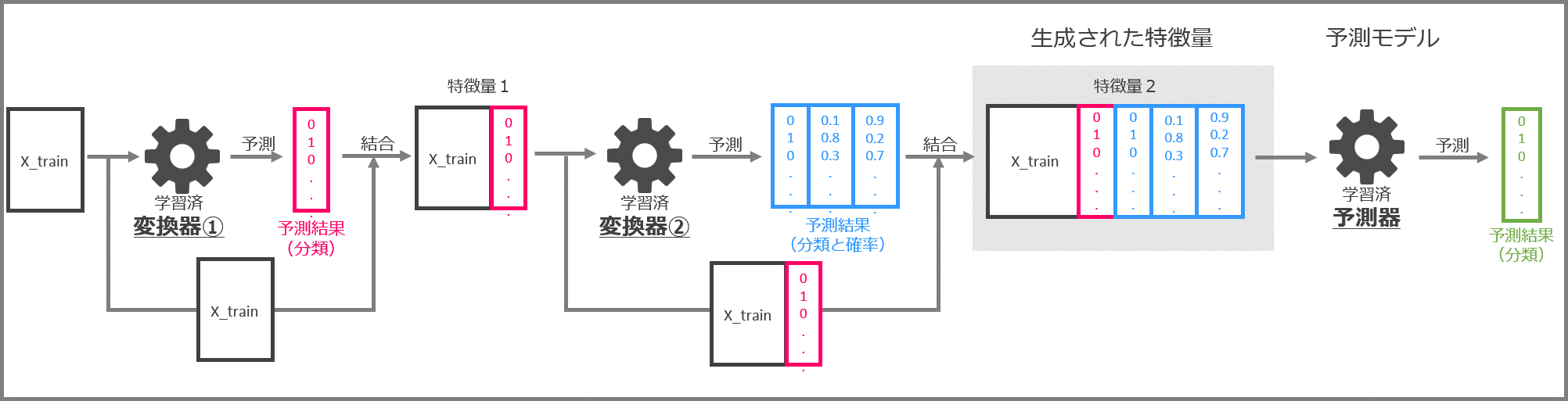
TPOTをはじめとした「自動機械学習」(AutoML)の場合ですと、以下のようになります。
データセット
↓
処理プログラム(変換器)
↓
処理プログラム(予測器)
↓
予測結果
要するに、ここでは、変換器(特徴量の生成と選択)と予測器(予測モデル)を直列に繋げたものを「パイプライン」と言います。
ちなみに、変換器(特徴量の生成と選択)は1つではなく複数の場合も多いです。
場合によっては、変換器(特徴量の生成と選択)を通さず、データセットをそのまま使い予測器(予測モデル)で予測することもあります。
この「パイプライン」を自動で最適化するのが「自動機械学習」(AutoML)です。
TPOTの場合
TPOTのサイト(http://epistasislab.github.io/tpot/)に、以下のようなTPOTのパイプライン例があります。
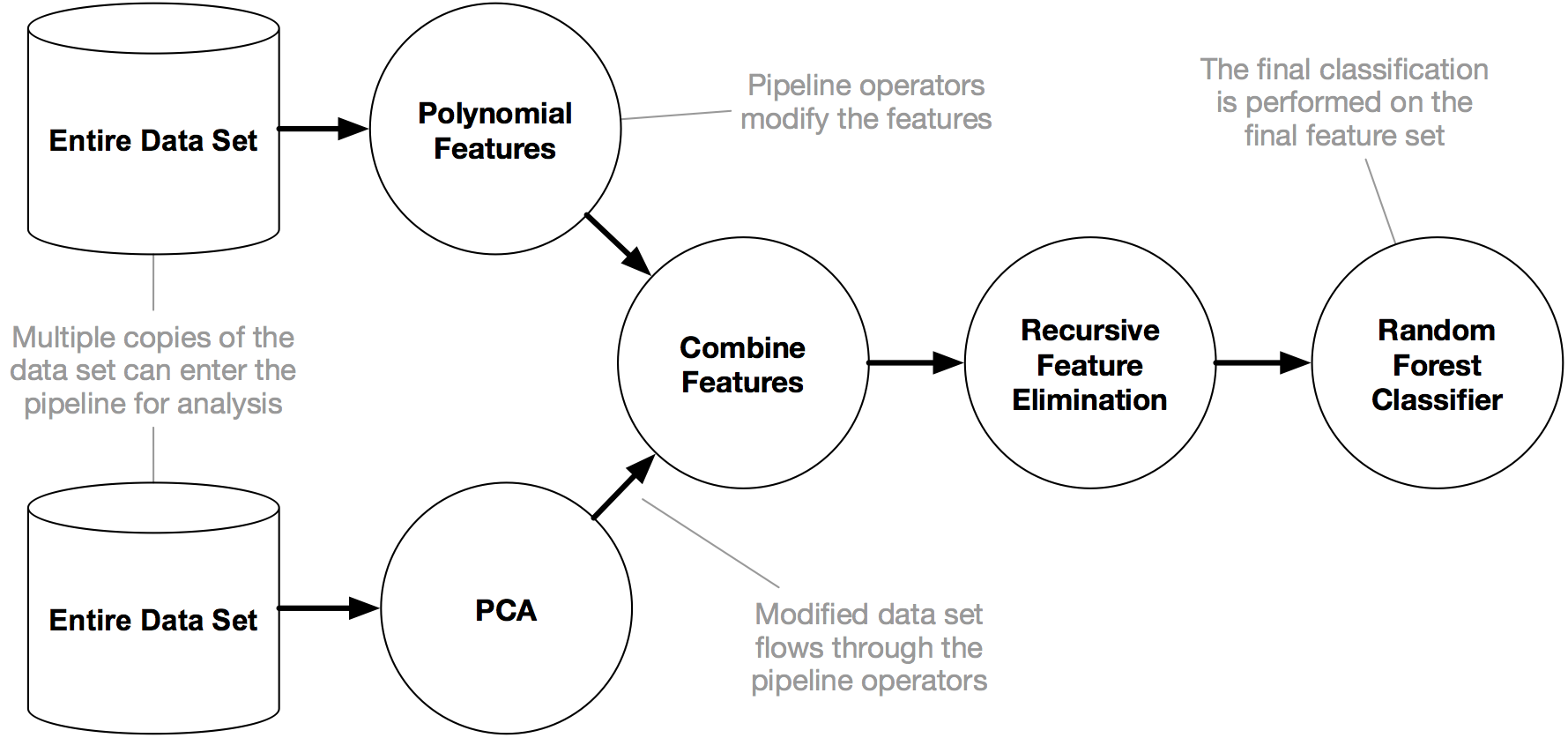
https://raw.githubusercontent.com/EpistasisLab/tpot/master/images/tpot-pipeline-example.png
一番左がデータセットで、一番右にあるのが予測器(この例ではランダムフォレスト)になります。その間にあるのが変換器です。
変換器がたくさんあります。
次に、この例の変換器を簡単に解説します。
【興味のある方だけご覧ください】変換器の説明
①データセット(Entire Data Set)から特徴量生成
先ず、データセット(Entire Data Set)を使い、2種類の特徴量セットを生成します。
- 多項式による特徴量生成(polynomial features)
- 主成分分析(PCA)による特徴量生成
「多項式による特徴量生成(polynomial features)」と「主成分分析(PCA)による特徴量生成」で使っているデータセットは同じものです。
データ分析に馴染みのない方は、意味不明だと思いますので、簡単に説明します。
「多項式による特徴量生成(polynomial features)」では、元のデータセットの特徴量(説明変数X)を多項式で表現し特徴量を新たに生成します。
例えば、特徴量(説明変数X)が2つ(X1とX2)あり、この2つの特徴量に対し「2次」の多項式による特徴量生成(polynomial features)を実施した場合、次にようになります。
1, X1, X2, X1×X1, X1×X2, X2×X2
つまり、2つの特徴量が6個になるのです。
今回の例は「2次」ですが、3次でも4次でも構いません。どんどん特徴量が増えます。
「主成分分析(PCA)による特徴量生成」では、元のデータセットの特徴量(説明変数X)に対し主成分分析を実施し、元の特徴量(説明変数X)と同じ数だけの新たな特徴量(説明変数X)を作り、その新しく作成した特徴量(説明変数X)の中から代表的な特徴量を選びます。
もちろん、新たな特徴量(説明変数X)すべてを使っても問題ありません。
元の特徴量(説明変数X)と新たな特徴量(説明変数X)の違いは何でしょうか?
元の特徴量(説明変数X)全体と新たな特徴量(説明変数X)全体の情報量は同じです。違いは、新たな特徴量(説明変数X)間の相関が小さくなっていることです。上手くいった場合には、ほぼ相関0になります。
②生成した特徴量を統合
「多項式による特徴量生成(polynomial features)」と「主成分分析(PCA)による特徴量生成」で新たな特徴量のセットが2つ生成されました。
それを次に、統合(Combine Features)します。
これだけです。
元のデータセットの特徴量(説明変数X)と比べると、倍以上に増えています。
③特徴量の選択
統合された特徴量をすべて使って予測モデルを構築してもいいですが、不必要なものを取り除きたいものです。
ここでは、「再帰的特徴量削減」(RFE、Recursive Feature Elimination)という手法をつあって、特徴量の選択を行っています。
なんか凄そうな名前ですが、実施していることは非常にシンプルです。
- 先ず、特徴量(説明変数X)すべてを使い予測モデルを構築します
- その中で、重要度が最も低い特徴量(説明変数X)を1つ取り除きます
- 次に、残りの特徴量(説明変数X)すべてを使い予測モデルを構築します
- その中で、重要度が最も低い特徴量(説明変数X)を1つ取り除きます
これを繰り返します。
これは、ラッパー法 (Wrapper Method)と呼ばれる「特徴量選択法」の1種です。
ラッパー法 (Wrapper Method)とは、数理モデル(ランダムフォレストなど)を用いて特徴量の重要度などを計算し、最も重要度の低い特徴量を削っていきます。
最後に、選択された特徴量を使い予測器で予測します。
ここまでが、この例の変換器の流れです。
この例の場合、複数の変換器により生成し選択した特徴量(説明変数X)を使い「ランダムフォレスト」と呼ばれる予測器(予測モデル)を使って予測します。
「自動機械学習」(AutoML)で構築したパイプラインは勉強になる
TPOTを実行すると、どのようなパイプラインが最適なのかを教えてくれます。
「自動機械学習」(AutoML)は、単に最適な予測モデルを自動で構築してくれるだけでなく、その前の特徴量の生成と選択までを含めて最適なものを構築してくれます。
「自動機械学習」(AutoML)で構築したパイプラインを眺めると非常に勉強になります。
人間の思いもよらなかった特徴量の生成と選択、予測モデルの構築などを実施することがあります。
元々のデータセットのクセのようなものも見えてくることもあります。
次回
次回は、第3回で扱った分類問題を使い、パイプラインの構築事例を解説します。