

第9回「AutoML【TPOT】のパイプラインに使われる関数一覧」で、TPOTのパイプライン(特徴量生成・予測)で使われる関数の概要を説明しました。
その中には、TPOT独自の関数がいくつかありました。
分類問題・回帰問題ともに、とく利用されるTPOT独自の変換器は次の3つです。
- tpot.builtins.ZeroCount
- tpot.builtins.OneHotEncoder
- tpot.builtins.StackingEstimator
Scikit-Learn(sklearn)などにも似たようなことのできるものはありますが、独自の工夫がなされています。
今回は、その中で「OneHotEncoder変換器」について説明します。
OneHotEncoder変換器とは?
OneHotEncoderは、入力値をダミー変数に変換した配列を返す関数です。
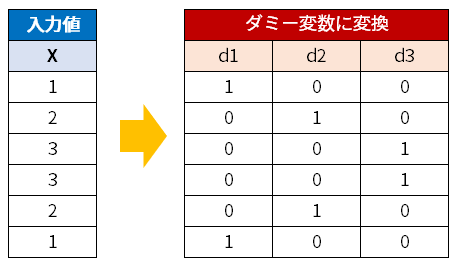
入力値は正の整数に限定されます。なので、文字列を特徴量としたいときは、文字列と一対一対応する整数に変換しておきます。
それでは実際にOneHotEncoderを使ってみましょう。
OneHotEncoderの挙動を確かめてみよう!
OneHotEncoderのモジュールと配列や数式を取り扱うnumpyパッケージをインポートします。
サンプルデータをnumpyで作り、OneHotEncoderの挙動を確かめます。
先ず、必要なライブラリーを読み込みます。
以下、コードです。
from tpot.builtins import OneHotEncoder import numpy as np
次に、NumPyでサンプルデータ(2次元配列)を作ります。
例えば、次のようなサンプルデータ(2次元配列)を作ったとします。
X = np.array([[10, 20, 40],
[10, 10, 20],
[20, 30, 20]])
print(X)
以下、実行結果です。

このXをOneHotEncoderで変換してみます。
sparse=Falseを実行することで、なじみのあるnumpyの2次元配列で答えを得ることができます。sparse=Trueを設定すると、メモリ領域を圧縮できる形式で変換結果を保持しておくことができます。
以下、コードです。
OneHotEncoder(sparse=False).fit_transform(X)
以下、実行結果です。

この実行結果を、図で説明します。
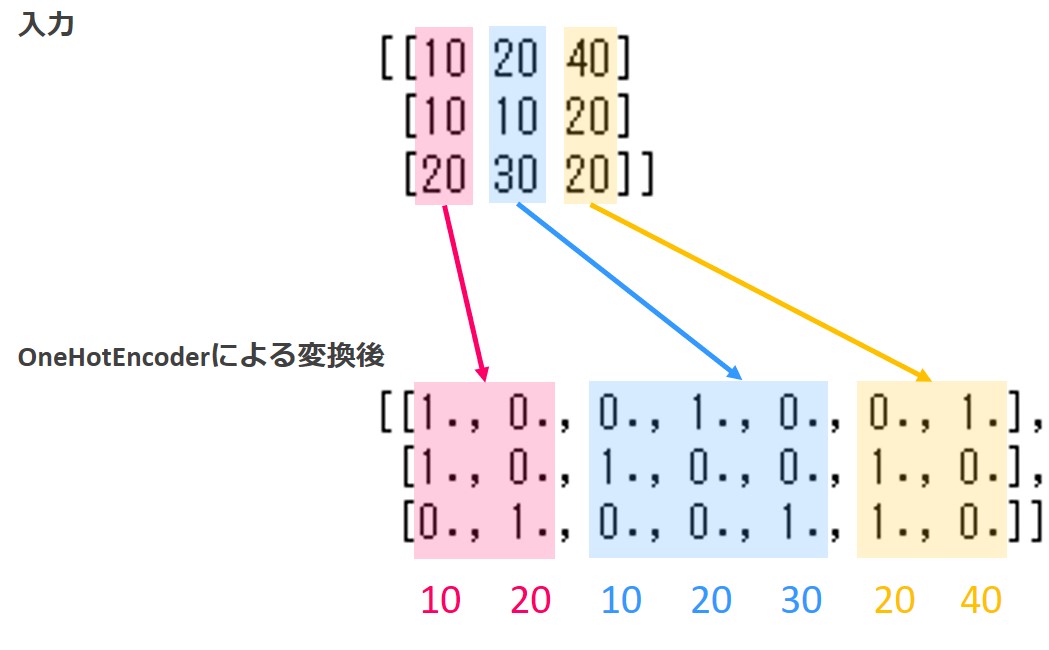
変換後の配列の1~2列目は入力の1列目に対応します。
入力の1列目は整数10と整数20の2つの要素から構成されています。
2つの要素から構成されるので、2列使ってダミー変数に変換されます。列の順番は要素の昇順に並びます。つまり、1列目が整数10に対応し、2列目が整数20に対応します。入力の1列目は1行目と2行目が10なので、変換後の10を表す列である1列目の、1行目と2行目にフラグ1が格納されます。また、入力の1列目の3行目が20なので、変換後は20に対応する2列目にフラグ1が格納されます。
入力の2列目は10,20,30の3つの要素が存在するので、変換後は3列用意されます。
同様に入力の3列目は20,40の2つの要素から構成されるので変換後は2列用意されています。
OneHotEncoderの説明で使ったコード全体
from tpot.builtins import OneHotEncoder
import numpy as np
X = np.array([[10, 20, 40],
[10, 10, 20],
[20, 30, 20]])
print(X)
OneHotEncoder(sparse=False).fit_transform(X)
次回
次回は、とく利用されるTPOT独自の変換器の1つである「StackingEstimator」について説明します。