

sktimeはPythonでよく使われている機械学習ライブラリsklearn(scikit-learn)と同じインターフェースで提供されているPythonの時系列ライブラリです。
sktimeでは2022.7.4時点で時系列の4つの時系列機械学習の問題を解くことができます。
| 問題名 | データの種類 | 内容 |
| 1. 時系列予測 Forecasting |
目的変数のみの時系列データ | 過去の時系列データが与えられたときの将来の予測です。 |
| 2. 時系列クラスタリング Time Series Clustering |
特徴量(説明変数)のみの時系列データ | 複数の時系列データを、いくつかの類似のグループに分けます。 |
| 3. 時系列分類 Time Series Classification |
目的変数と特徴量(説明変数)のある時系列データ | 特徴量と目的変数が与えられた分類問題のうち、特徴量に時間的もしくはデータの順番に意味があるときに使います。sktimeでは二値分類および多値分類に対応しています。 |
| 4. 時系列回帰 Time Series Regression |
特徴量と目的変数が与えられたとき、目的変数が時系列かつ連続データであるときの目的変数の予測です。 |
このsktimeを使うためには、sktimeをPythonにインストールし呼び出さなければなりません。
前回は、sktimeのインストールについて簡単に説明しました。
インストールしたら使ってみましょう。今回から、sktimeを使って順番に時系列問題を解いていきます。
今回は時系列予測の方法を説明します。一定間隔で記録された目的変数の将来を予測するものです。
- 時系列予測 ⇒ 今回
- 時系列クラスタリング
- 時系列分類
- 時系列回帰
Contents [hide]
事前準備
まずはJupyter Notebookを開いておきます。
次に、下記コマンドを入力し、必要なモジュールを読み込んでおきます。
from sktime.datasets import load_airline from sktime.forecasting.model_selection import temporal_train_test_split from sktime.forecasting.trend import STLForecaster from sktime.performance_metrics.forecasting import mean_absolute_percentage_error import matplotlib.pyplot as plt import pandas as pd
| モジュール名 | 内容 |
| load_airline | sktimeに含まれるデータセットの一つ。 |
| temporal_train_test_split | sktimeに含まれるモジュール。時系列データに特化したデータ分割モジュール。 |
| STLForecaster | sktimeに含まれる時系列予測器。周期とトレンドに分け、時系列予測するためのモジュール。 |
| mean_absolute_percentage_error | sktimeに含まれる時系列予測の評価関数。MAPE |
| matplotlib.pyplot | matplotlibに含まれる、プロットのためのツール |
| pandas | 二次元形式のデータを取り扱うためのツール |
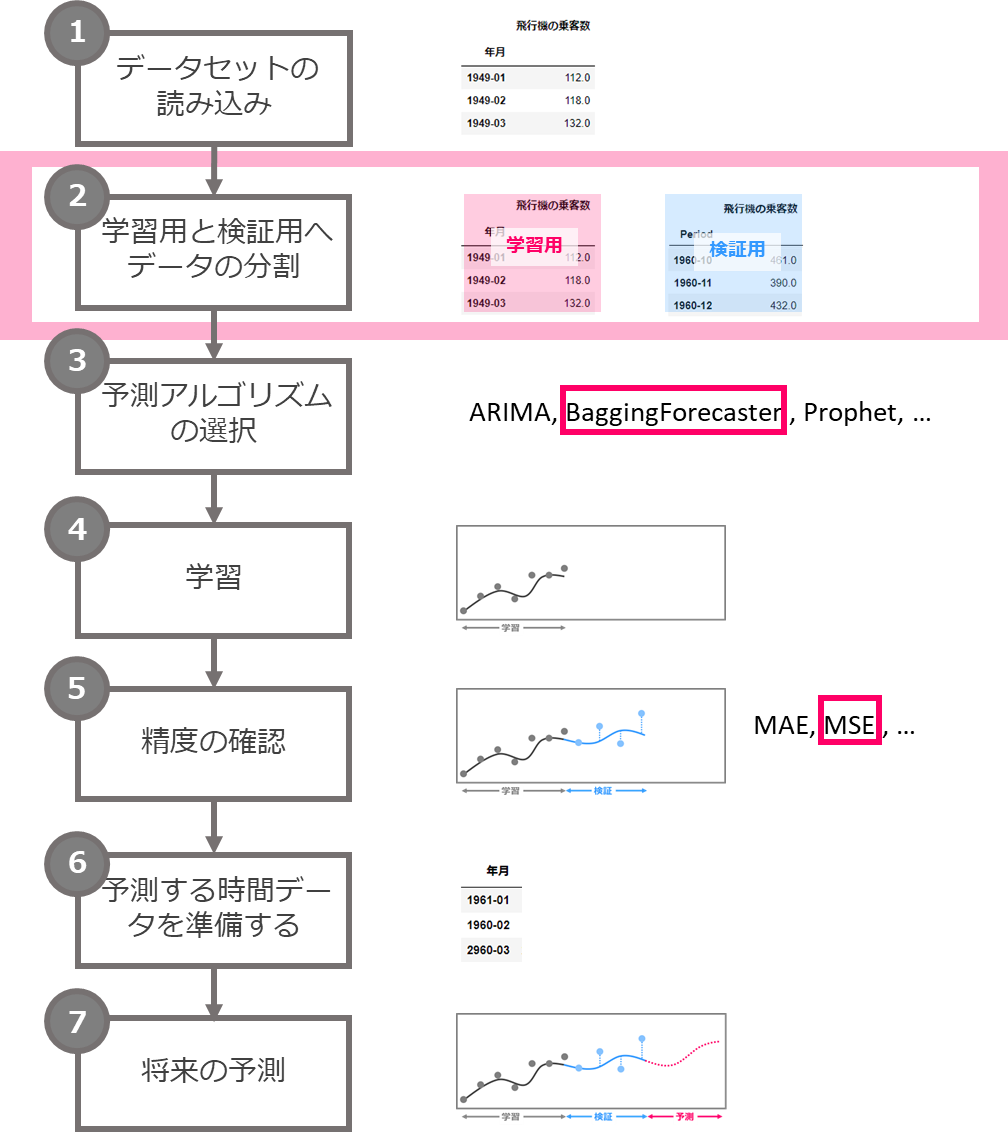
予測の流れ
予測の流れは次のとおりです。ご覧になって分かるように、機械学習の一般の流れと同じです。
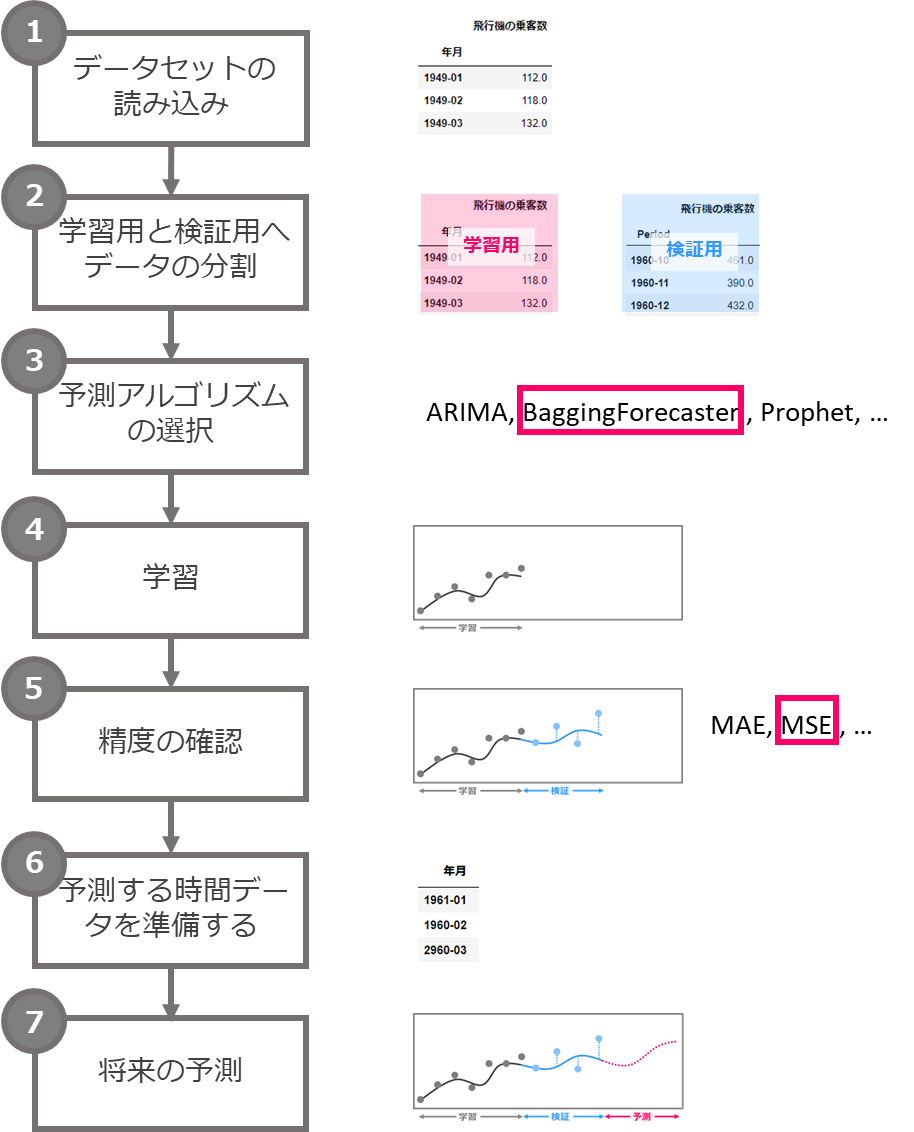
1.データセットの読み込み
まずはデータセットを読み込みます。今回は1変量の時系列予測、つまり目的変数のみを持つ時系列データの予測をします。
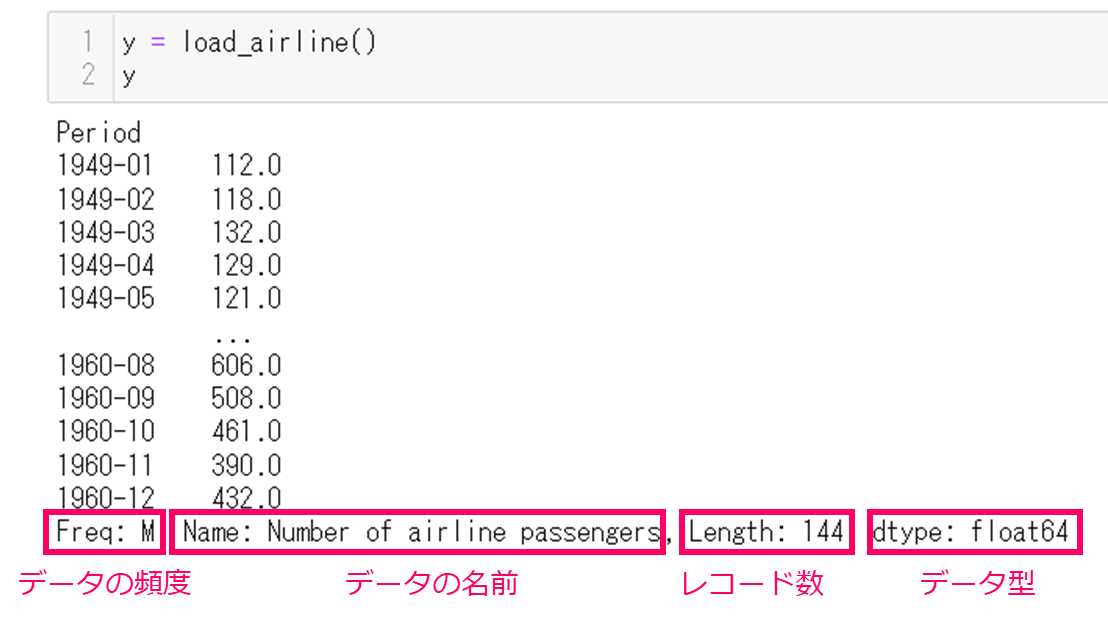
sktimeのデータセットとして用意されている飛行機の乗客数のデータを使って予測します。次のコマンドで変数yにデータセットを読み込みます。1行目でデータの読み込み、2行目でyの中身を表示しています。
y = load_airline() y
実行結果です。Periodとして1949年1月から1960年12月まで、毎月の飛行機の乗客数が記録されています。データの頻度は1ヶ月ごと(Freq: M)レコード数は144行(Length: 144)、データ型は倍精度浮動小数点型(float64)ということがわかります。
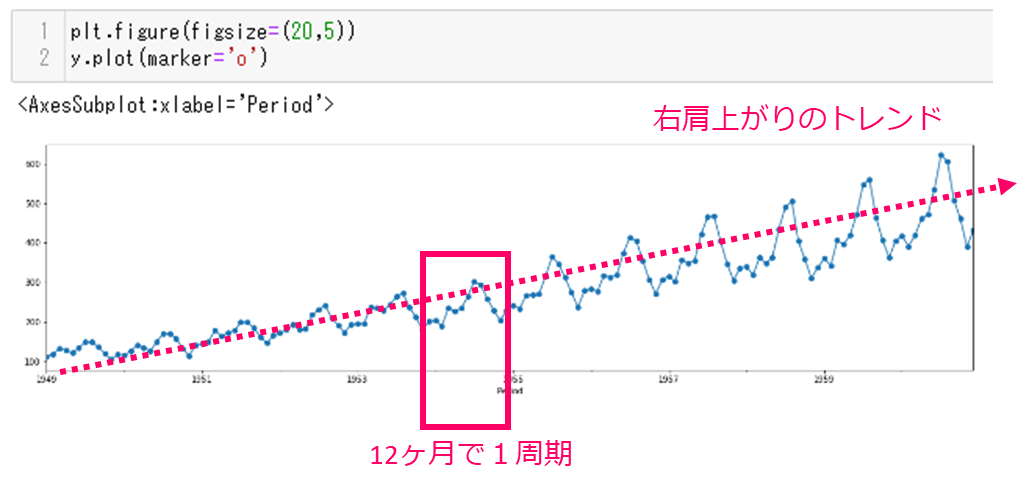
どのようなデータか、プロットしてみてみます。次のコマンドを入力してください。1行目で図の大きさをしていしており、2行目でプロットを作っています。
plt.figure(figsize=(20,5)) y.plot(marker='o')
実行結果です。12ヶ月の周期と、右肩上がりのトレンドが存在することがわかります。
2.学習用と検証用へデータの分割
次は、精度検証のための学習用データと検証用データへの分割です。
ここで注意することがあります。時系列データではないデータの機械学習の場合、ランダムにデータをピックアップし、データを分割します。しかし、そうすると時系列データでは時間の情報が失われてしまうので、学習も精度検証もできなくなってしまいます。
そこで、sktimeでは時間の順番を保持した、時系列データ用の分割関数temporal_train_test_splitが用意されています。なお、実際はこの分割方法ではなくクロスバリデーションを使った精度検証が多いので、また別の回でご説明します。
次のコマンドで読み込んだデータセットyを学習用データy_trainと検証用データy_testへ分割します。検証用データのサイズは全体の25%とします。学習用データのサイズは残りの75%となります。
y_train, y_test = temporal_train_test_split(y, test_size=0.25)
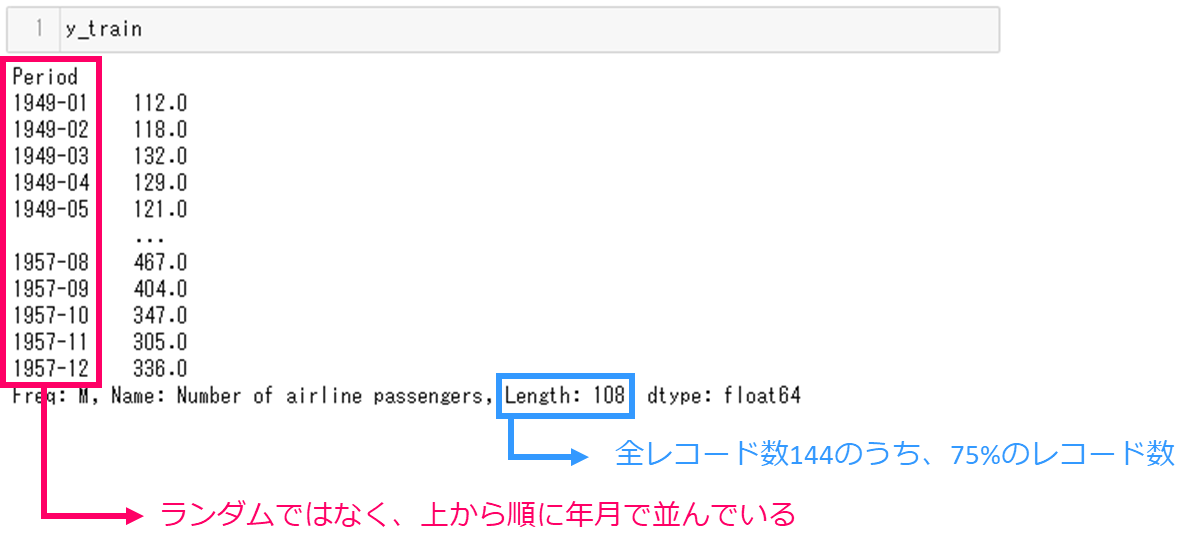
学習用データy_trainと検証用データy_testの中身を見てみます。まずは学習用データです。コマンドです。
y_train
実行結果です。注目すべきは時間データのPeriodで、ランダムではなく上から順に年月で並んでいます。また、レコード数は、元のレコード数が144でしたので、指定した75%、108のレコードが格納されています。
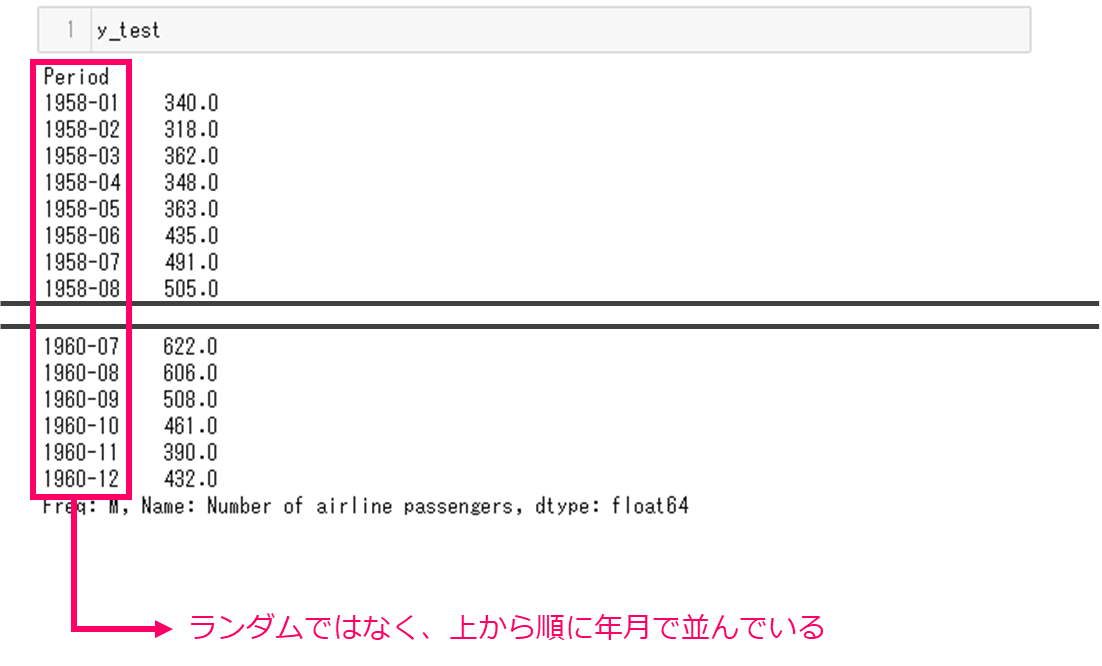
同様に検証用データy_testも見てみます。コマンドです。
y_test
実行結果です。長いので途中は省略しています。こちらも、時間データを見ると、ランダムではなく上から順に並んでいます。
3.予測アルゴリズムの選択
次は予測に使うアルゴリズムを選択します。
アルゴリズムは豊富に用意されています。こちらが2022.08.30時点の、version:stableのアルゴリズム一覧です。各予測器の詳細は別の回で説明します。また、単体では使えないためここには載せていませんが、予測器を組み合わせて使う予測器もあります。
今回は周期とトレンドがきれいに見えているので、周期成分とトレンド、ノイズに分解して予測するSTLForecasterを使います。
次のコマンドでアルゴリズムを指定します。12ヶ月の周期が見て取れたので、周期の長さを表すオプションspだけしておきます。1行目でアルゴリズムを指定、2行目で指定したアルゴリズムの確認ができます。
forecaster = STLForecaster(sp=12) forecaster
実行結果です。STLForecasterが指定されました。

4.学習
次は学習です。
次のコマンドで学習用データy_trainに対して学習します。
forecaster.fit(y_train)
実行結果です。

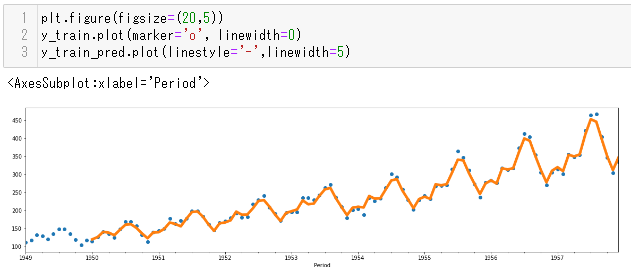
どのように学習されたかを見てみます。次のコマンドで学習結果を表示します。
plt.figure(figsize=(20,5)) y_train.plot(marker='o', linewidth=0) y_train_pred.plot(linestyle='-',linewidth=5)
実行結果です。青い点が学習用データ、オレンジの実線が学習結果です。周期とトレンドをうまく推定できていそうです。
精度も見てみましょう。今回はMAPE(=Mean Absolute Percentage Error)を使ってみます。
学習データの推定値は最初の12ヶ月分がないので、それまでのデータは切り捨てて精度検証します。MAPEとは、実測値と予測値の差分を実測値で割ったものの絶対値をデータ数で割ったものです。
mean_absolute_percentage_error(y_train[12:], y_train_pred[12:])
実行結果です。実測値に対して平均的に2%の誤差で学習できていることがわかります。

5.精度の確認
それでは次に検証用データy_testを使って精度を検証します。
以下、コマンドです。1行目でy_testに対して予測し、2行目で推定結果を表示しています。
y_train_pred = forecaster.predict(y_test.index) y_train_pred
以下、実行結果です。
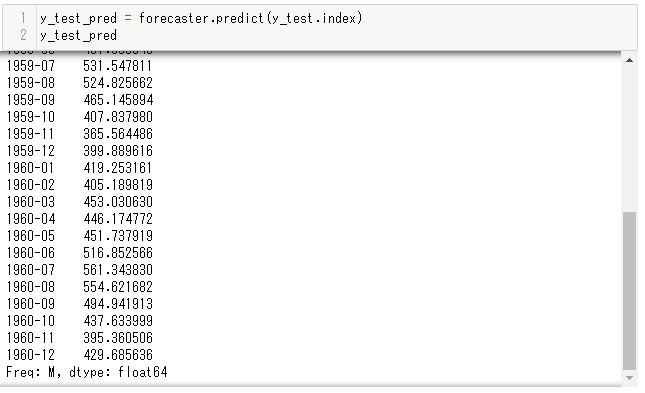
こちらも数字だけではわかりにくいので、プロットしてみます。
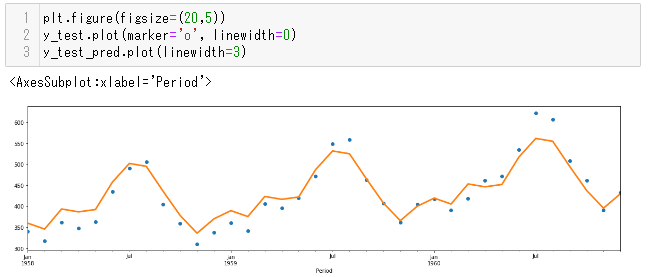
1行目は図の大きさの指定、2行目は元の検証用データy_testのプロット、3行目は検証用データの時間データでの予測値のプロットです。学習用に蔵べ、精度はやや下がりそうです。
plt.figure(figsize=(20,5)) y_test.plot(marker='o', linewidth=0) y_test_pred.plot(linewidth=3)
以下、実行結果です。
では精度検証します。MAPE(=Mean Absolute Percentage Errorr)を使います。
mean_absolute_percentage_error(y_test, y_test_pred)
実行結果です。

学習用データがMAPE=約2%に対して、検証用データでは約5%ということが分かります。必要な制度は解くべき問題によって違いますが、プロットと精度を見る限りは大きく違った予測にはなってなさそうです。
6.予測する時間データを準備する
それでは、ここからは学習用データにも検証用データにも入っていない、未来の予測です。
予測したいデータの外の(未来の)時間のデータを用意します。以下、コマンドです。
y_pred_index = pd.PeriodIndex(pd.date_range("1961-01", periods=12, freq="M"))
y_pred_index
実行結果です。今回は12ヶ月分の時間データを作りました。

7.将来の予測
先ほど作った将来の時間データを使って予測します。
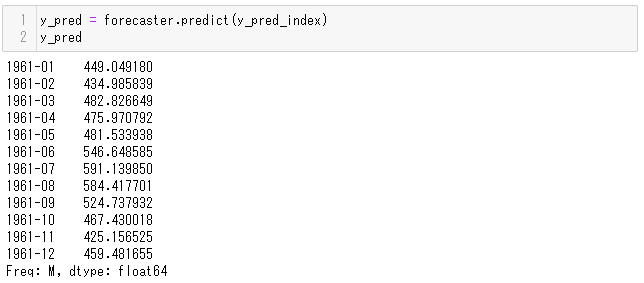
コマンドです。1行目で予測、2行目で予測結果を表示しています。
y_pred = forecaster.predict(y_pred_index) y_pred
実行結果です。
最後に学習用データ、検証用データ、将来の予測データをプロットします。
plt.figure(figsize=(20,5)) y_train.plot(marker='o', linewidth=0, c='darkblue') y_train_pred.plot(linewidth=3, c='darkblue', alpha=0.5) y_test.plot(marker='o', linewidth=0,c='orange') y_test_pred.plot(linewidth=3, c='orange', alpha=0.5) y_pred.plot(linewidth=3, c='darkred', linestyle='--')
実行結果です。
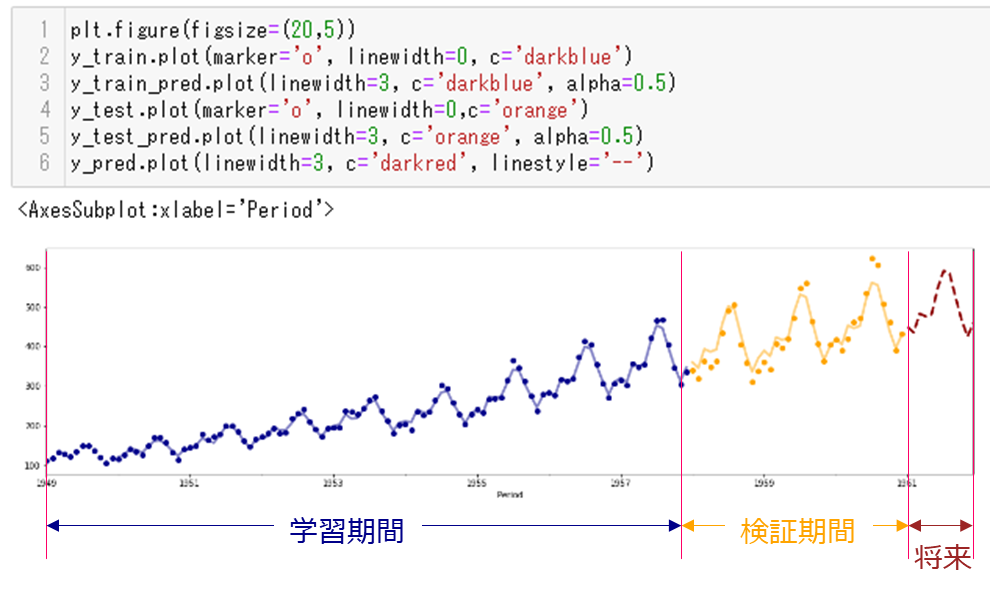
以上で時系列データだけ(時間データと目的変数)のときの予測の一連の流れが完了しました。
まとめ
今回は時系列予測の方法を説明しました。一定間隔で記録された目的変数の将来を予測するものです。
- 時系列予測 ⇒ 今回
- 時系列クラスタリング ⇒ 次回
- 時系列分類
- 時系列回帰
次回は、時系列クラスタリングです。
Python ライブラリー「sktime」で学ぶ らくらくビジネス時系列機械学習 Web講座 – 第4回:時系列クラスタリング –