

sktimeで取り扱うデータの種類(scitype)には3つあります。
- 1. 時系列データ(Series)
- 2. パネル時系列データ(Panel)
- 3. 階層時系列(Hierarchical)
各データの種類(scitype)に対し、複数のデータの持ち方(mtype)があります。
![]()
利用する時系列モデルのアルゴリズムに応じて利用できるmtypeが異なります。
参考:Loading and working with data in sktime
https://www.sktime.org/en/v0.8.0/examples/loading_data.html
今回は、sktimeで使うデータの構造について説明します。
Contents [hide]
時系列データの種類(scitypeの種類)
では、以下のデータの種類(scitype)について説明します。
- 1. 時系列データ(Series)
- 2. パネル時系列データ(Panel)
- 3. 階層時系列(Hierarchical)
時系列データ(Series)
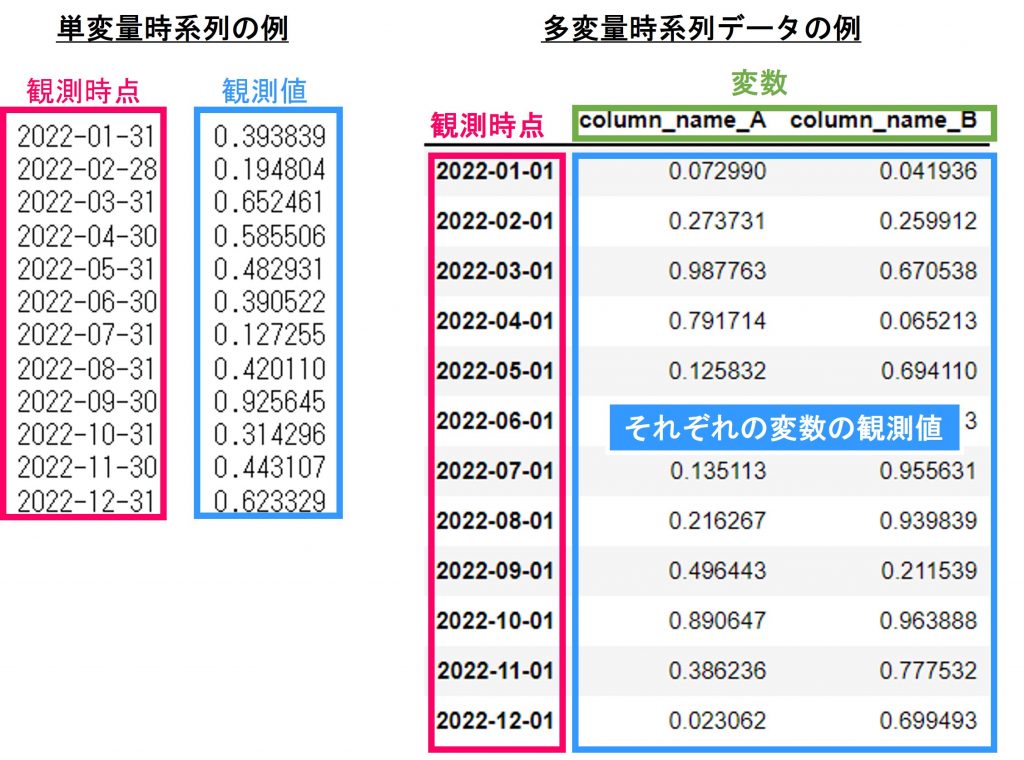
(単純な)時系列データには単変量時系列データ(Univariate time series)と多変量時系列データ(Multivariate time series)があります。
単変量時系列データとは、一つの変数を時系列順に並べたものです。時間ごとに観測された値だけではなく、空間としての観測点ごとの値でもいいです。いずれにせよ、ある間隔で、値を順番に観測したデータです。例えば飛行機の毎年の乗客数などは年という一定の間隔で順番に乗客数という値を並べたデータになります。
多変量時系列データとは、同一の対象から、複数のデータをある間隔で同じ順番に並べたデータです。例えば四半期ごとに一国の個人消費支出、個人可処分所得、生産量、貯蓄、失業率など複数の経済指標を同じ時点で一定の間隔で観測したデータなどが多変量時系列データになります。
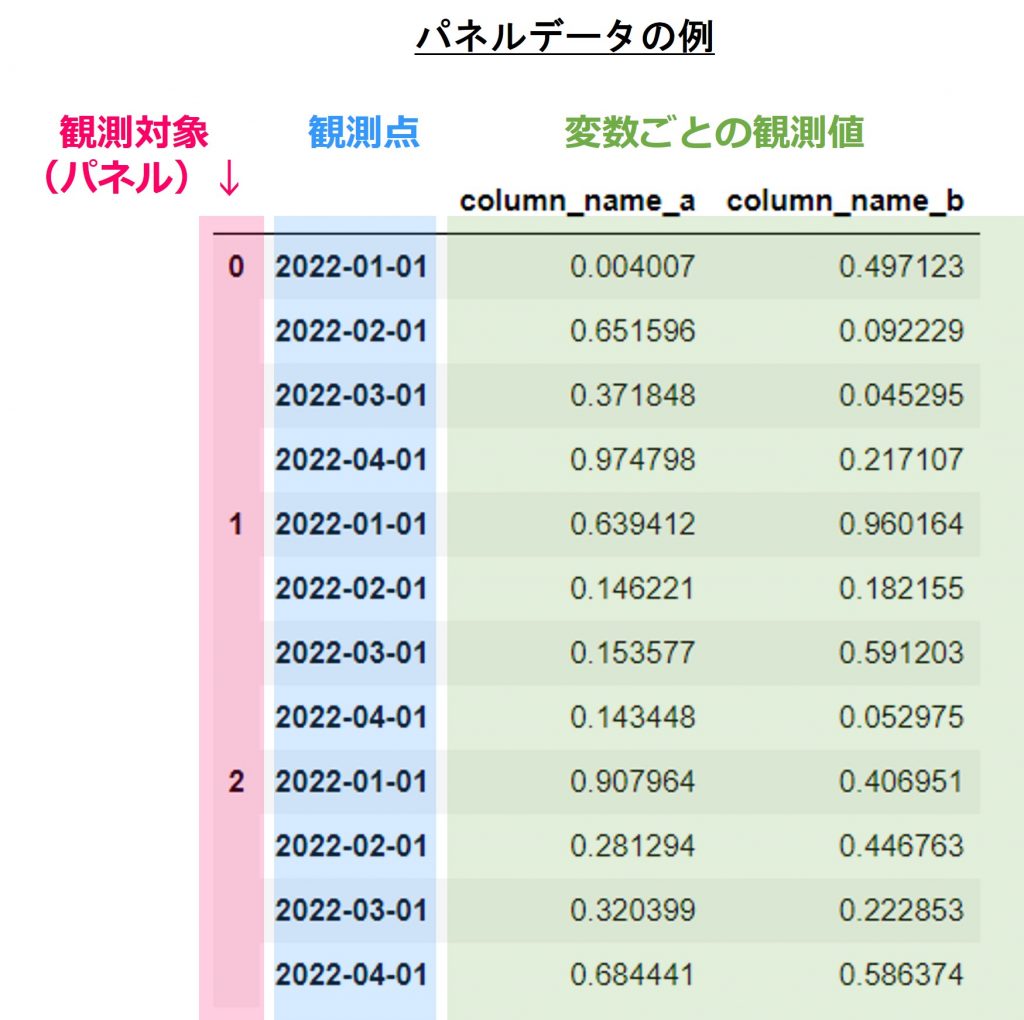
パネル時系列データ(Panel)
パネル時系列データは、系列データを複数の対象に拡張したデータです。例えば四半期ごとに個人消費支出、個人可処分所得、生産量、貯蓄、失業率など複数の経済指標を複数の国で同じ時点で一定の間隔で観測したデータなどがパネル時系列データになります。
階層時系列(Hierarchical)
階層時系列データは、例えば第1階層として会社全体の会員数時系列データがあり、第2階層として地域ごとの会員数時系列データがあり、第3階層として各店舗の会員数時系列データがあり、それぞれの階層の会員数を合計すると上の階層の会員数になる、という構造を持つデータです。
階層時系列データの解析例は例えば次のページも見てみてください(https://www.salesanalytics.co.jp/column/no00283/)

データの持ち方(各データの種類(scitype)に応じたmtype)
時系列データ(Series)のデータ構造(mtype)
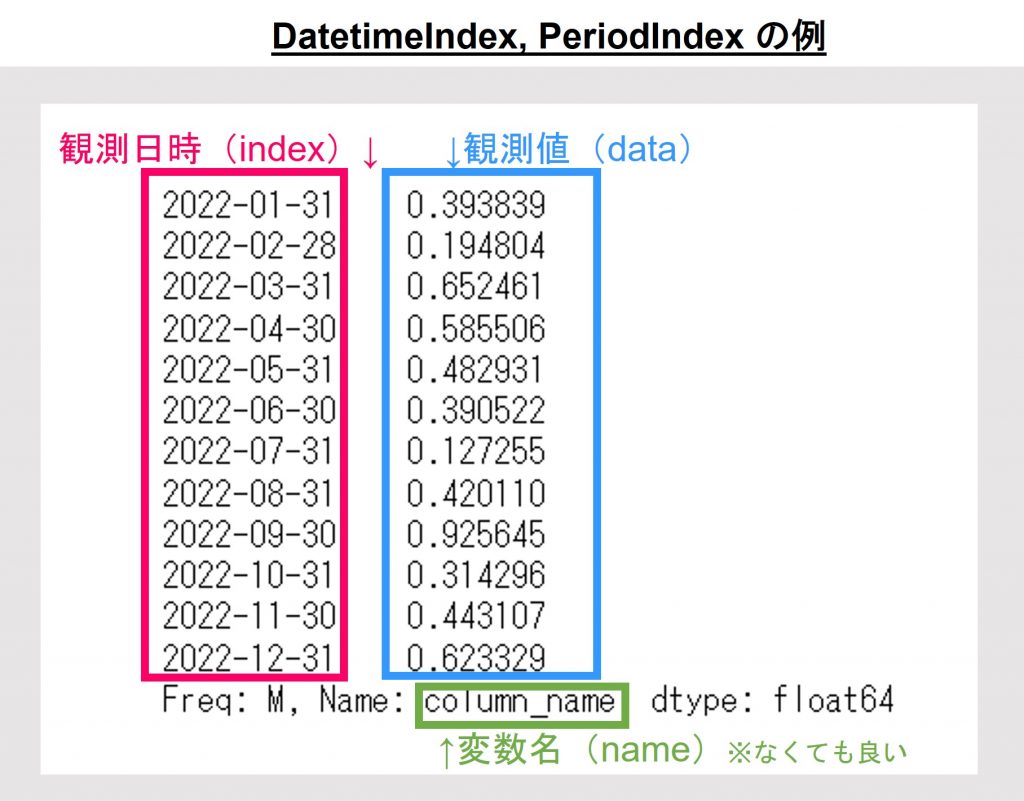
pd.Series
データ型はpandasライブラリのSeriesです。pandas.SeriesはIndex(行の情報)とValues(値)から構成されます。
Indexの種類は、以下の4種類です。
- Int64Index
- RangeIndex
- DatetimeIndex
- PeriodIndex
Int64Index。RangeIndexには日時の情報はなく、時点の順番のみが表現されています。

DatetimeIndex、PeriodIndexには日時の情報が入っています。
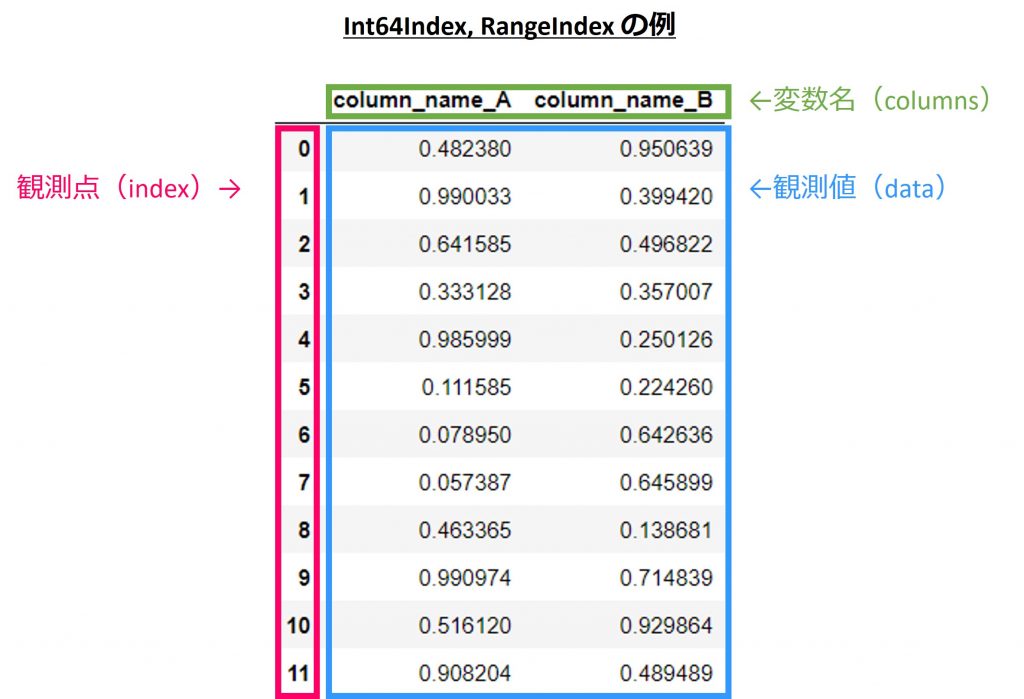
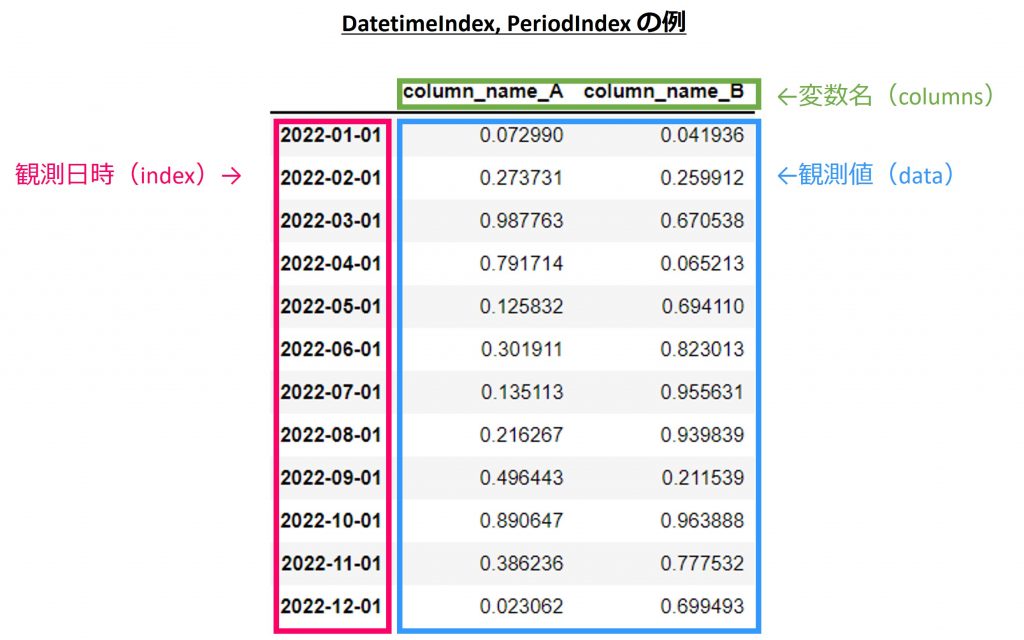
pd.DataFrame
データ型はpandasライブラリのDataFrameです。
Index(行)とdata(観測値)、columns(変数名)から構成されます。上述のpd.Seriesは単変量のみでしたが、pd.DataFrameは、単変量と多変量どちらにも対応しています。
また、pd.Seriesと同様に、Indexの種類は、以下の4種類です。
- Int64Index
- RangeIndex
- DatetimeIndex
- PeriodIndex
多変量の例で示します。
以下、Int64Index、RangeIndexの場合:
以下、DatetimeIndex、PeriodIndexの場合:
np.ndarray
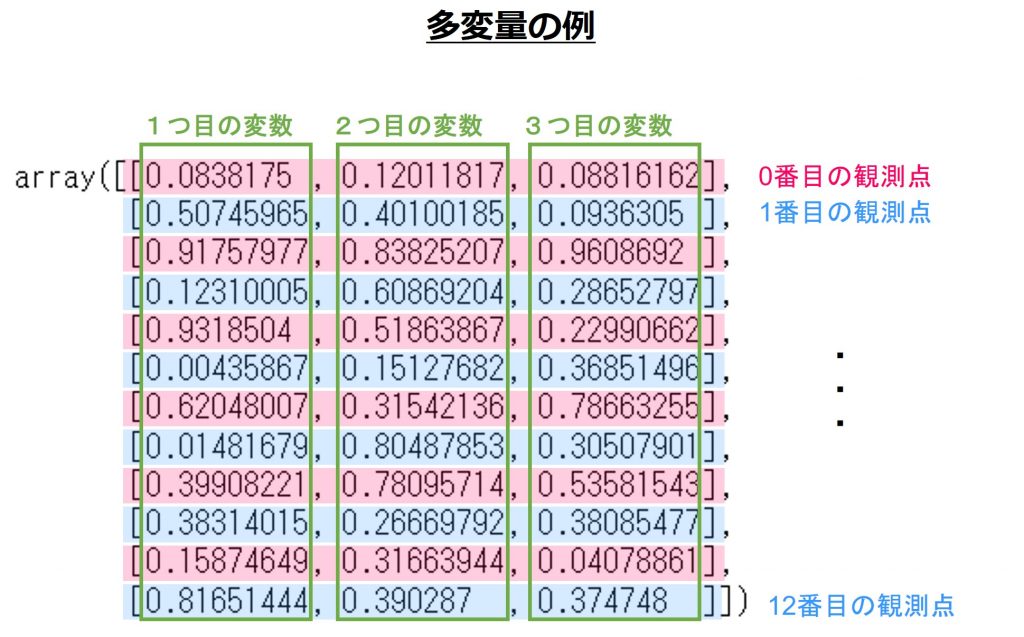
numpyライブラリのndarrayデータ型として表現されます。
pd.Seriesやpd.DataFrameは不等間隔の観測点を表現できますが、np.ndarrayは等間隔のみ可です。
なぜならば、観測点の情報(index)を持たないため、暗黙的に各行が同じ間隔で観測されたと解釈するしかないからです。
以下、単変量の例です。

以下、多変量の例です。
パネル時系列データ(Panel)のデータ構造(mtype)
pd-multiindex
データ型はpandasライブラリのDataFrameです。ただし、複数のインデックス(Multi-Index)を持ちます。
先程の時系列データ(Series)との大きな違いは、観測点(観測日時)と観測値の情報に加え、複数の観測対象のデータを持てることです。
観測対象と観測点をペアとしてpandasライブラリのMultiIndexとしてデータを持ちます。
どういう状態のデータセットなのかは、見たほうが理解が早いと思いますので、簡単な例を示します。
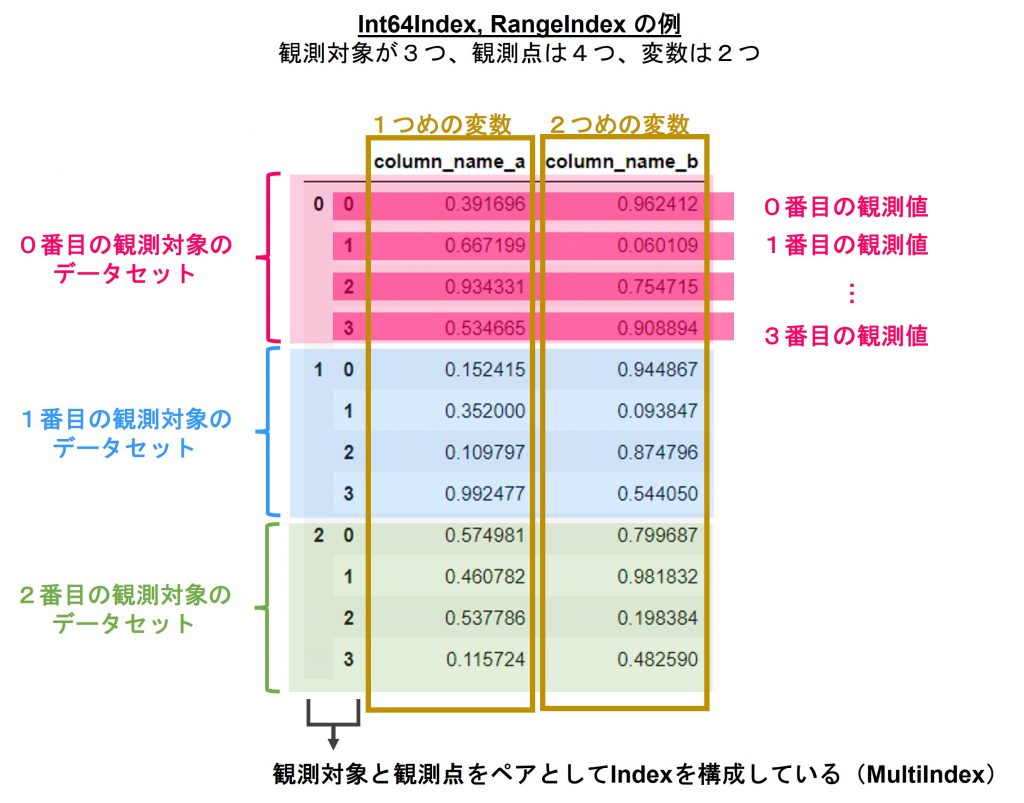
以下、Int64Index、RangeIndexの場合:
以下、DatetimeIndex、PeriodIndexの場合:

MultiIndexは第1レベル、第2レベル、第3レベル…と階層構造を持ちますが、pd-multiindexは以下のようになります。
- 観測対象を第1レベルのIndex
- 観測点(観測日時)を第2レベルのIndex
先程のDatetimeIndex、PeriodIndexの場合の例では……
- 観測対象が0,1,2の3つ
- 観測日時が2022年1月1日から1ヶ月単位で4時点
- 各観測対象の各時点に変数が2つ
……合計で、3観測対象×4時点×2変数=24個の観測値が格納されています。
一方、Int64Index、RangeIndexの場合の例では、観測点が日時ではなく観測点で表されており、観測値の数は同じく3観測対象×4観測点×2変数=24個の観測値が格納されています。
numpy3D
Panelには、観測点の情報を明示的に持たない、3次元のnumpy.ndarrayデータ型のデータ構造もあります。
pd-multiindexでは観測対象や観測点、変数を明示しましたが、numpy3Dでは明示しません。次元ごとにsktimeが観測対象、観測点、変数を判断します。
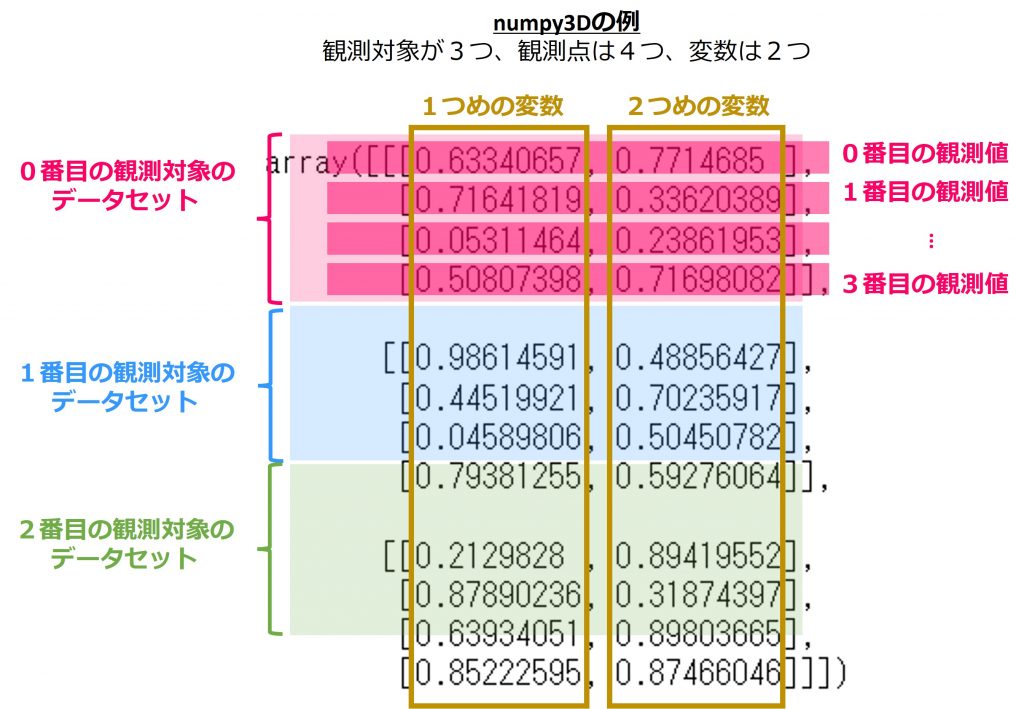
上図では3つの観測対象、4つの観測点、2つの変数ですが、numpy.ndarrayの次元としては(3,4,2)として表現します。(観測対象数,観測点数,変数の数)として指定します。
df-list
df-listは、pd-multiindexをリストの要素として表現したものです。ここで、変数セットや観測点数は観測対象ごとに違ってもいいですし、観測点も不等間隔であることが許されています。
以下、Int64Index、RangeIndexの場合:

以下、DatetimeIndex、PeriodIndexの場合:

階層時系列(Hierarchical)のデータ構造(mtype)
pd_multiindex_hier
Hierarchicalのmtypeは1つだけで、このpd_multiindex_hierです。
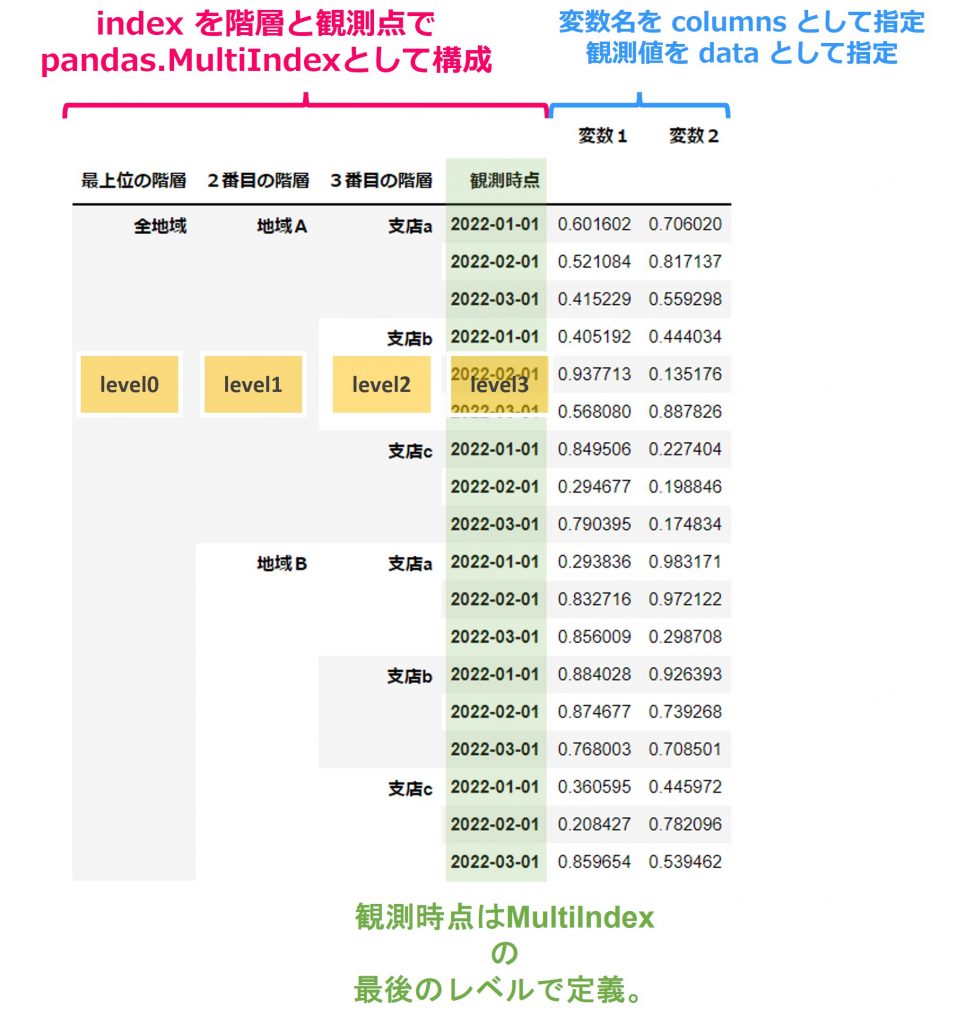
この例では3番目の階層(支店)を合計した値が2番目の階層(地域)の値に、2番目の階層(地域)を合計した値が最上位の階層(全地域)の値となるように構成されています。
階層と観測点を合わせてMultiIndexとして構成します。
MultiIndexの最後のレベル(ここではlevel3)で観測点を指定します。観測点はこれまでと同様、Int64Index, RangeIndex, DatetimeIndex, PeriodIndexが許可されています。
まとめ
今回は、sktimeで使うデータの構造について説明しました。
まとめると以下の表のようになります。
| scitype名 | mtype名 | 説明 |
| Series
(系列データ) |
pd.Series |
|
| pd.DataFrame |
|
|
| np.ndarray |
|
|
| Panel
(パネル時系列データ) |
pd-multiindex |
|
| numpy3D |
|
|
| df-list |
|
|
| Hierarchical
(階層的時系列データ) |
pd_multiindex_hier |
|
どのアルゴリズムがどのmtypeに対応しているのかは、API Referense(https://www.sktime.org/en/stable/api_reference.html)に記載があります。
次回はデータの作り方を説明します。
Python ライブラリー「sktime」で学ぶ らくらくビジネス時系列機械学習 Web講座 – 第6回:データの読み込み方・作り方(CSV編) –