

前回は、データ構造を説明しました。
それぞれのデータ構造に沿ったデータの読み込み方・作り方があります。
sktimeに読み込めるデータフォーマットは次の4つです。
- csvフォーマット
- tsフォーマット
- Weka ARFFフォーマット
- UCR .tsvフォーマット
今回は、最も利用頻度が高いと思われるCSVの読み込み方と、sktimeデータフォーマットの作り方を説明します。
Contents [hide]
- 復習:データの種類(scitype)とデータの持ち方(mtype)
- 手順(ファイルの読み込みとmtypeへ変換)
- 利用するデータ
- sample_Series.csv(単変量時系列データ)
- sample_DataFrame.csv(多変量時系列データ)
- sample_multiindex.csv(パネル時系列データ)
- sample_hierarchical.csv(階層時系列データ)
- 準備(必要なモジュールの読み込み)
- mtype=pd.Series
- 1.CSVファイルを読み込む
- 2.mtypeへ変換する
- 3.mtypeに変換できたかどうか確認する
- mtype=pd.DataFrame
- mtype=np.ndarray
- mtype=pd-multiindex
- mtype=numpy3D
- mtype=df-list
- mtype=pd_multiindex_hier
- まとめ
復習:データの種類(scitype)とデータの持ち方(mtype)
前回の復習です。
sktimeで取り扱うデータの種類(scitype)には3つあります。
- 1. 時系列データ(Series)
- 2. パネル時系列データ(Panel)
- 3. 階層時系列(Hierarchical)
各データの種類(scitype)に対し、複数のデータの持ち方(mtype)があります。
![]()
利用する時系列モデルのアルゴリズムに応じて利用できるmtypeが異なります。
手順(ファイルの読み込みとmtypeへ変換)
先ずCSVファイルを読み込み、読み込んだデータをmtypeに変換し、sktimeで利用します。
mtypeごとに、今回は次の流れで説明します。
- CSVファイルを読み込む
- mtypeへ変換する
- mtypeに変換できたかどうか確認する
利用するデータ
今回利用するデータは、以下の6つのCSVファイルです。
- sample_Series.csv(単変量時系列データ)
- sample_DataFrame.csv(多変量時系列データ)
- sample_multiindex.csv(パネル時系列データ)
- sample_hierarchical.csv(階層時系列データ)
c:/work直下に保存してあると想定して説明していきます。
データは以下からダウンロードできます。
サンプルデータ一式
https://www.salesanalytics.co.jp/wk7u
その前に、それぞれのデータの中を簡単に見ていきます。
sample_Series.csv(単変量時系列データ)
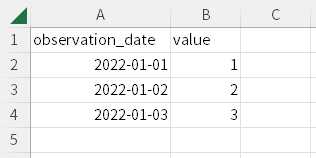
sample_DataFrame.csv(多変量時系列データ)
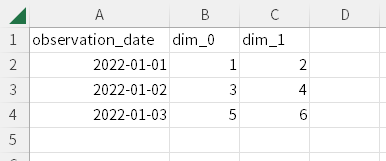
sample_multiindex.csv(パネル時系列データ)
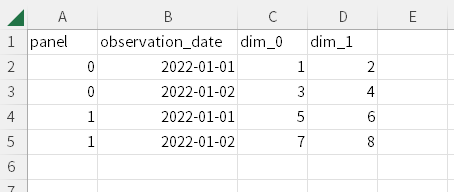
sample_hierarchical.csv(階層時系列データ)
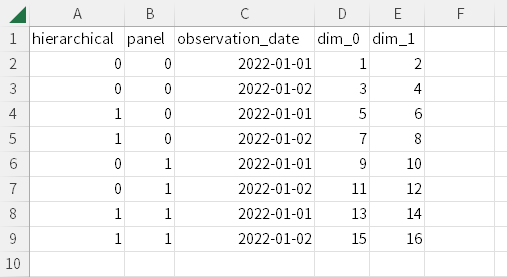
準備(必要なモジュールの読み込み)
準備としてpandasとsktimeのdatatypes(sktime.datatypes)を読み込んでおきます。
以下、コードです。
import pandas import sktime.datatypes
mtype=pd.Series
読み込むデータは、sample_Series.csv(単変量時系列データ)です。
最初なので丁寧に説明していきます。
1.CSVファイルを読み込む
pandas.read_csv関数で、mtype=pd.Seriesに互換性があるように、CSVファイルを読み込み、データフレームdfに格納します。
互換性を保つためには、インデックスが日付型(DatetimeIndexもしくはPeriodIndex)であることが必要です。
そこで、インデックスとしてindex_col引数にobservation_date列を指定し、さらに日付型として認識するために引数parse_datesをTrueとしておきます。
以下、コードです。
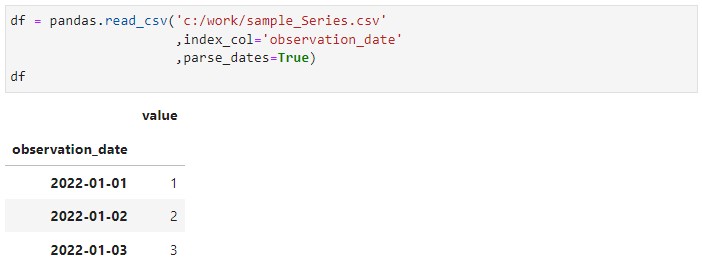
df = pandas.read_csv('c:/work/sample_Series.csv',
index_col='observation_date',
parse_dates=True)
df
以下、実行結果です。
2.mtypeへ変換する
convert_to関数で、mtype=pd.Seriesへと変換します。
- 第一引数:変換元のオブジェクト(df)
- 第二変数:変換先のmtype名(pd.Series)
以下、コードです。
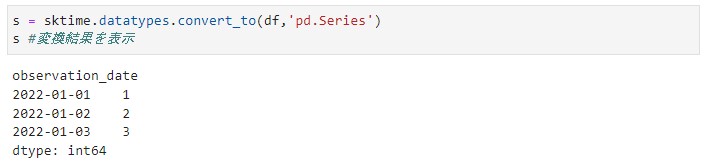
s = sktime.datatypes.convert_to(df,'pd.Series') s #変換結果を表示
以下、実行結果です。
3.mtypeに変換できたかどうか確認する
mtypeへ変換できたことを、sktime.datatypes.check_is_mtype関数で確認します。
- 第一引数:型を確認したいオブジェクト(s)
- 第二変数:確認したいmtype名(pd.Series)
コードです。
sktime.datatypes.check_is_mtype(s,'pd.Series')
以下、実行結果です。

ここまでのコードの全体です。
import pandas
import sktime.datatypes
#1.CSVファイルを読み込む
df = pandas.read_csv('c:/work/sample_Series.csv',
index_col='observation_date',
parse_dates=True)
df
#2.mtypeへ変換する
s = sktime.datatypes.convert_to(df,'pd.Series')
s #変換結果を表示
#3.mtypeに変換できたかどうか確認する
sktime.datatypes.check_is_mtype(s,'pd.Series')
他のmtypeに関しても同じ様な説明を繰り返すのも冗長なので、コードの全体だけを示して行きます。
mtype=pd.DataFrame
読み込むデータは、sample_DataFrame.csv(多変量時系列データ)です。
以下、コードです。
import pandas
import sktime.datatypes
#1.CSVファイルを読み込む
df = pandas.read_csv('c:/work/sample_DataFrame.csv',
index_col='observation_date',
parse_dates=True)
df #結果を表示
#2.mtypeへ変換する
d = sktime.datatypes.convert_to(df,'pd.DataFrame')
d #変換結果を表示
#3.mtypeに変換できたかどうか確認する
sktime.datatypes.check_is_mtype(d,'pd.DataFrame')
以下、実行結果です。

mtype=np.ndarray
読み込むデータは、sample_DataFrame.csv(多変量時系列データ)です。
以下、コードです。
import pandas
import sktime.datatypes
#1.CSVファイルを読み込む
df = pandas.read_csv('c:/work/sample_DataFrame.csv',
index_col='observation_date',
parse_dates=True)
df #結果を表示
#2.mtypeへ変換する
d = sktime.datatypes.convert_to(df,'np.ndarray')
d #変換結果を表示
#3.mtypeに変換できたかどうか確認する
sktime.datatypes.check_is_mtype(d,'np.ndarray')
以下、実行結果です。

mtype=pd-multiindex
読み込むデータは、sample_multiindex.csv(パネル時系列データ)です。
以下、コードです。
import pandas
import sktime.datatypes
#1.CSVファイルを読み込む
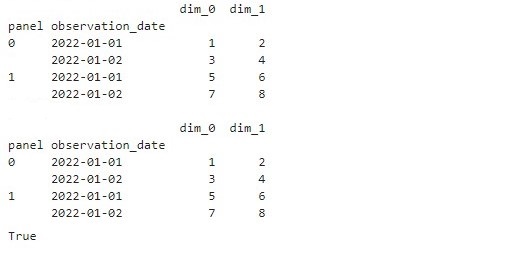
df = pandas.read_csv('c:/work/sample_multiindex.csv',
index_col=['panel','observation_date'],
parse_dates=True)
df #結果を表示
#2.mtypeへ変換する
d = sktime.datatypes.convert_to(df,'pd-multiindex')
d #変換結果を表示
#3.mtypeに変換できたかどうか確認する
sktime.datatypes.check_is_mtype(d,'pd-multiindex')
以下、実行結果です。
mtype=numpy3D
読み込むデータは、sample_multiindex.csv(パネル時系列データ)です。
以下、コードです。
import pandas
import sktime.datatypes
#1.CSVファイルを読み込む
df = pandas.read_csv('c:/work/sample_multiindex.csv',
index_col=['panel','observation_date'],
parse_dates=True)
df #結果を表示
#2.mtypeへ変換する
d = sktime.datatypes.convert_to(df,'numpy3D')
d #変換結果を表示
#3.mtypeに変換できたかどうか確認する
sktime.datatypes.check_is_mtype(d,'numpy3D')
以下、実行結果です。

mtype=df-list
読み込むデータは、sample_DataFrame.csv(多変量時系列データ)です。
以下、コードです。
import pandas
import sktime.datatypes
#1-1.CSVファイルを読み込む
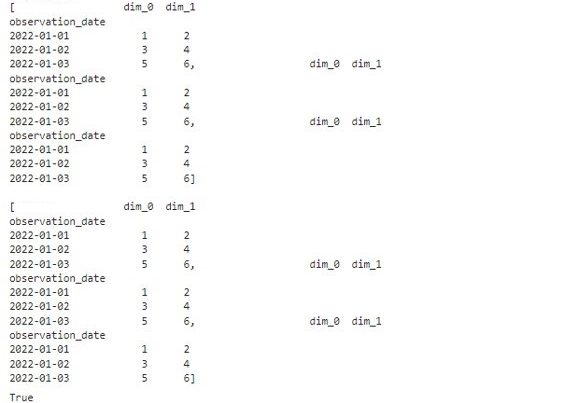
df = pandas.read_csv('c:/work/sample_DataFrame.csv'
,index_col='observation_date'
,parse_dates=True)
#1-2.疑似的に、df-listに互換性のある、データフレームのリストを作る
df = [df,df,df]
df #結果を表示
#2.mtypeへ変換する
d = sktime.datatypes.convert_to(df,'df-list')
d #変換結果を表示
#3.mtypeに変換できたかどうか確認する
sktime.datatypes.check_is_mtype(d,'df-list')
以下、実行結果です。
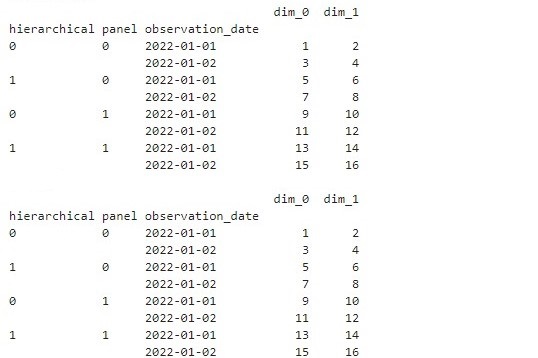
mtype=pd_multiindex_hier
読み込むデータは、sample_hierarchical.csv(階層時系列データ)です。
以下、コードです。
import pandas
import sktime.datatypes
#1.CSVファイルを読み込む
df = pandas.read_csv('c:/work/sample_hierarchical.csv',
index_col=['hierarchical','panel','observation_date'],
parse_dates=True)
df #結果を表示
#2.mtypeへ変換する
d = sktime.datatypes.convert_to(df,'pd_multiindex_hier')
d #変換結果を表示
#3.mtypeに変換できたかどうか確認する
sktime.datatypes.check_is_mtype(d,'pd_multiindex_hier')
以下、実行結果です。
まとめ
sktimeに読み込めるデータフォーマットは次の4つです。
- csvフォーマット
- tsフォーマット
- Weka ARFFフォーマット
- UCR .tsvフォーマット
今回は、最も利用頻度が高いと思われるCSVの読み込み方と、sktimeデータフォーマットの作り方を説明しました。
次回は、tsフォーマットの読み込み方と、sktimeデータフォーマットの作り方を説明します。
Python ライブラリー「sktime」で学ぶ らくらくビジネス時系列機械学習 Web講座 – 第7回:データの読み込み方・作り方(tsフォーマット編) –