

sktimeに読み込めるデータフォーマットは次の4つです。
- csvフォーマット
- tsフォーマット
- Weka ARFFフォーマット
- UCR .tsvフォーマット
前回は、最も利用頻度が高いと思われるCSVの読み込み方と、sktimeデータフォーマットの作り方を説明しました。
ちなみに、sktimeで取り扱うデータの種類(scitype)には3つあります。
- 1. 時系列データ(Series)
- 2. パネル時系列データ(Panel)
- 3. 階層時系列(Hierarchical)
今回は、パネル時系列データ(Panel)を扱うtsフォーマットの読み込み方と、sktimeデータフォーマットの作り方を説明します。
Contents [hide]
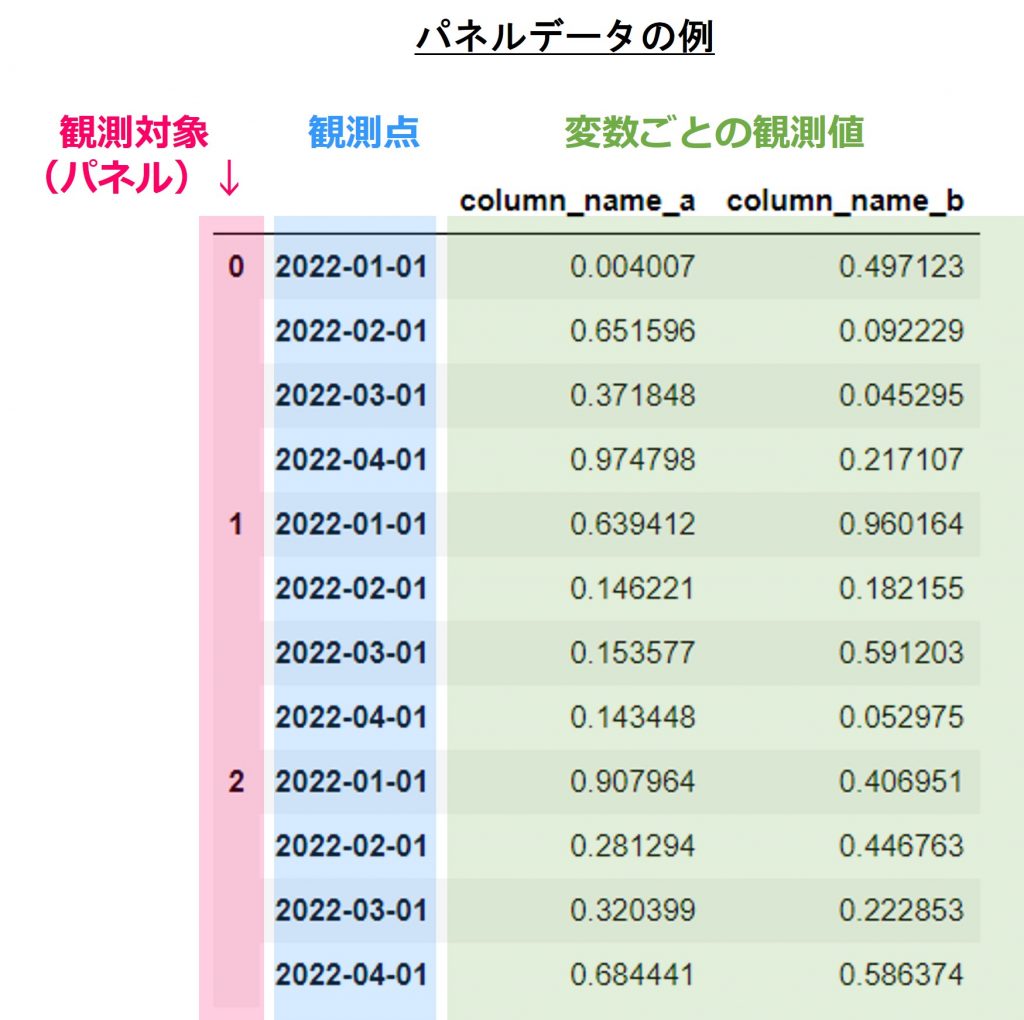
復習:パネル時系列データ(Panel)
先ずは、パネル時系列データ(Panel)の復習からです。
パネル時系列データは、系列データを複数の対象に拡張したデータです。例えば四半期ごとに個人消費支出、個人可処分所得、生産量、貯蓄、失業率など複数の経済指標を複数の国で同じ時点で一定の間隔で観測したデータなどがパネル時系列データになります。
TSフォーマットの構成
次に、このパネル時系列データ(Panel)を扱うtsフォーマットの構成について説明します。
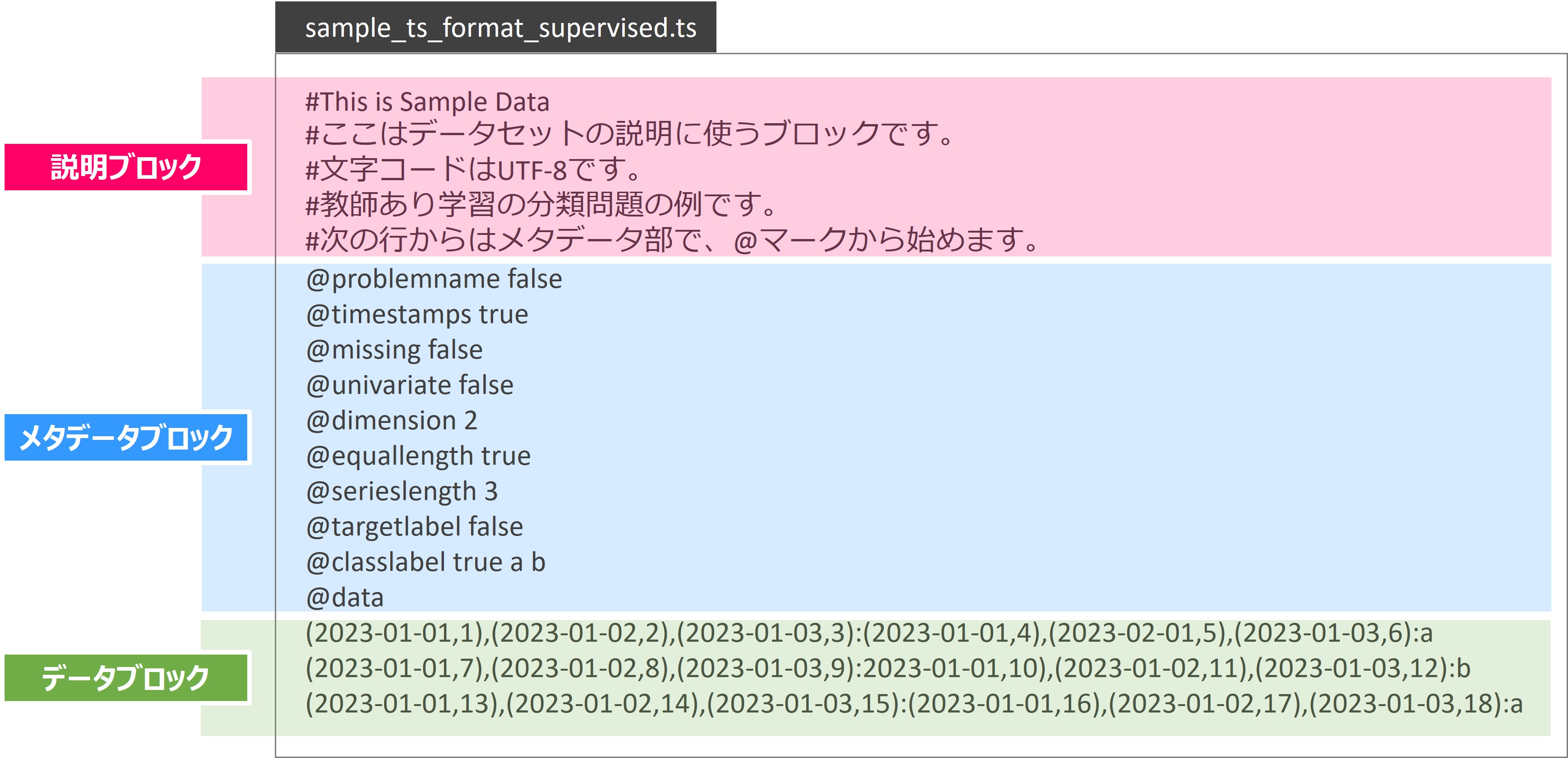
TSフォーマットは3つのブロックで構成されています。
- 説明ブロック … データセットの説明を記載するブロック(#から始まる)
- メタデータブロック … データセットを定義するブロック(@から始まる)
- データセットブロック … データセット本体
例えば、次のようなファイルを作ります。時系列分類(aとbの2クラス)の例で、1つめの観測対象(instances=0)のクラスがa,2つめの観測対象( instances=1)のクラスがb,3つめの観測対象(instances=2)のクラスがaです。
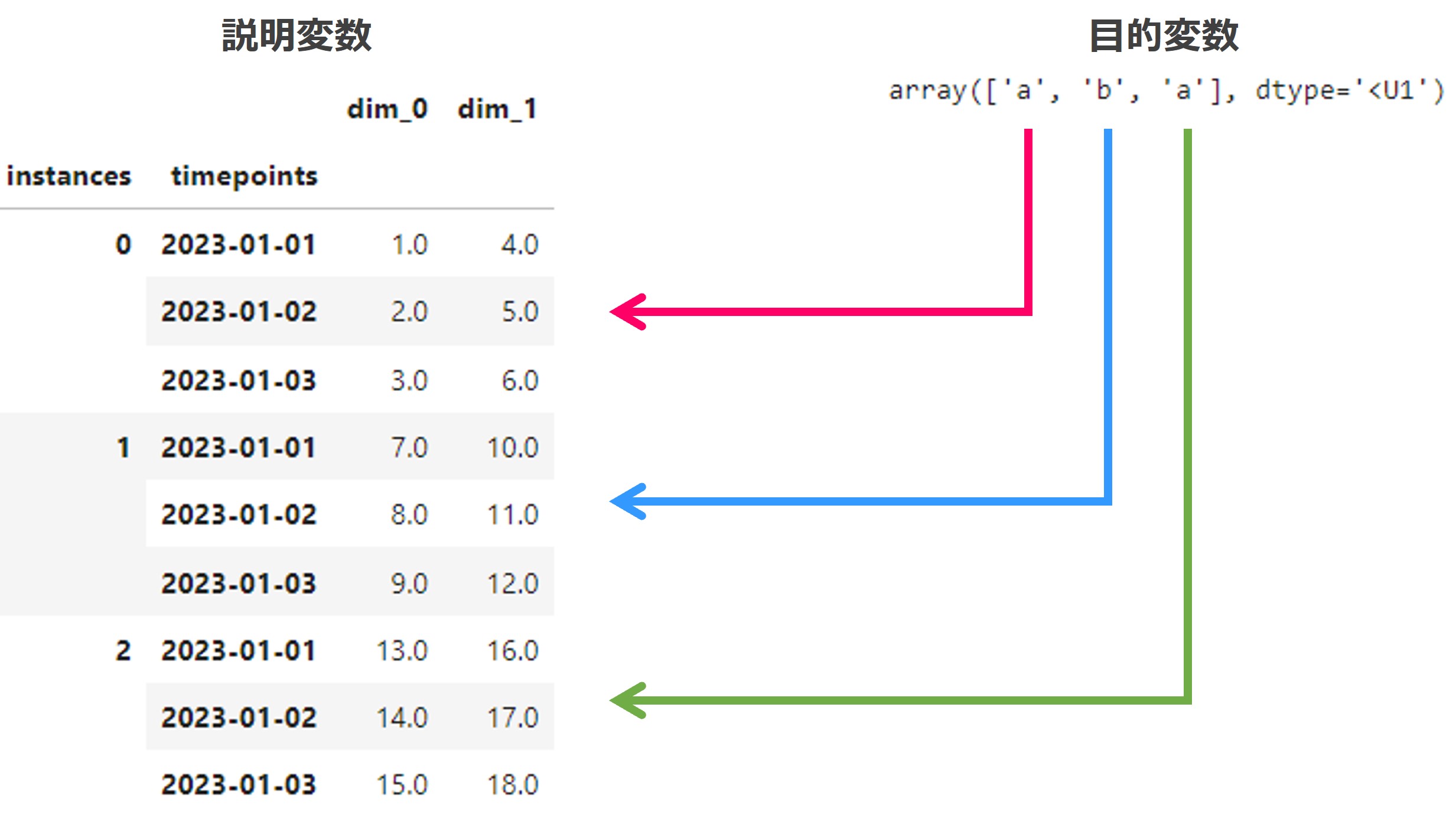
これを読み込みpd-multiindexへ変換すると、次のようなパネル時系列データ(Panel)になります。
わけわからないと思いますので、各ブロックごとに説明します。
TSフォーマットの「説明ブロック」
データセットに関する説明を記述するブロックです。
決まっているのは行を#(半角シャープ)から始めることだけで、記述する内容に決まりはありません。
データセットの内容があとからでもわかるように記載しましょう。
以下、説明ブロックの記載例です。
#ここはデータセットの説明に使うブロックです。
#文字コードはUTF-8です。
#教師あり学習の分類問題の例です。
#次の行からはメタデータ部で、@マークから始めます。
TSフォーマットの「メタデータブロック」
データセットの形式について定義するブロックです。
非常に重要です。
以下、各項目の説明です。
| 項目 | 内容 | 値 | 例 |
| @problemname | データセットの名前 | 文字列 | TsFormatSamples |
| @timestamps | タイムスタンプの有無 | true:あり false:なし |
true |
| @missing | 欠損値の有無 | true:あり false:なし |
false |
| @univariate | 単変量か多変量か | true:単変量 false:多変量 |
false |
| @dimension | データの次元数 | 1以上の整数 | 2 |
| @equallength | 観測対象の観測点数がすべて同じか | true:同じ false:異なる |
true |
| @serieslength | 観測点数 | 1以上の整数 | 3 |
| @targetlabel | 回帰問題の場合のみ
ターゲット列が存在するか否か |
true:存在する false:存在しない |
false |
| @classlabel | 分類問題の場合のみ
クラスの存在有無とクラスの値 |
true:存在する false:なし |
true a b |
| @data | データの開始を宣言する識別子 | ― | ― |
以下、メタデータブロックの設定例です。
@timestamps true
@missing fase
@univariate false
@dimension 2
@equallength true
@serieslength 3
@targetlabel false
@classlabel true 0 1
@data
メターデータブロックの最後に@dataがあります。
@dataの次の行からがデータセットブロックになります。
TSフォーマットの「データセットブロック」
いきなり、データセットブロックの例を示します。
以下です。
(2023-01-01,7),(2023-01-02,8),(2023-01-03,9):2023-01-01,10),(2023-01-02,11),(2023-01-03,12):b
(2023-01-01,13),(2023-01-02,14),(2023-01-03,15):(2023-01-01,16),(2023-01-02,17),(2023-01-03,18):a
行がパネルの観測対象を示します。
この例ではデータが3行なので、観測対象が3つあります。
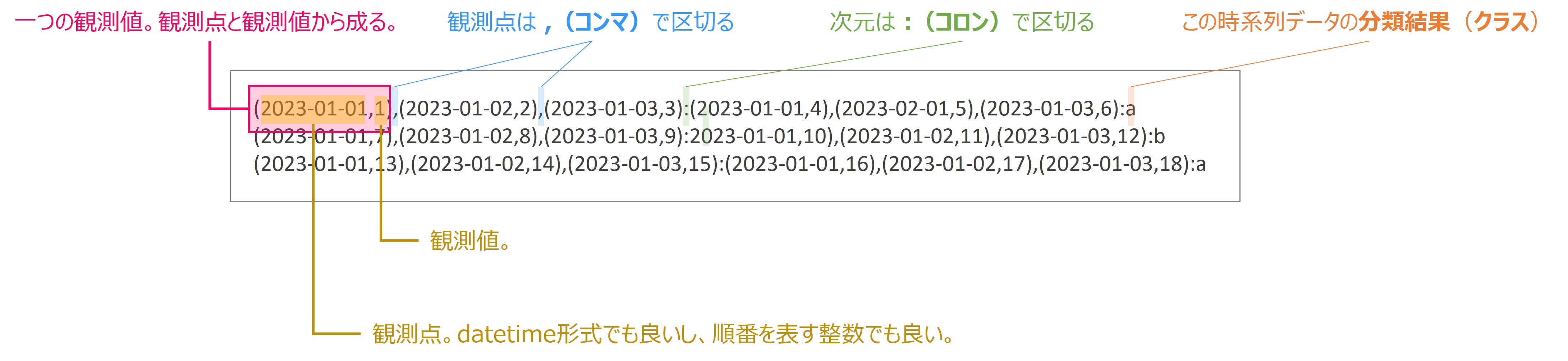
このデータセットをよく見ると、次の3つから構成されていることがわかります。
- タプル ( , )
- コンマ ,
- コロン :
タプルの中に観測時点と観測値があり、(観測時点,観測値)で表されます。
このタプルは、,(コンマ)で区切られ、次元は:(コロン)で区切られています。
:(コロン)で区切られた最後の次元がクラスです。
難しそうに見えますが、覚えてしまえば問題はありません。
ここから、具体的にデータセットブロックの記載方法について説明します。
タイムスタンプ
データセットにはタイムスタンプをつけるか、つけないかを選べます。
タイムスタンプをつける場合
メタデータブロックの項目@timestampをtrueとします。
タイムスタンプと観測値をタプルにして記録します。
タイムスタンプは……
- 日時型(yyyy-mm-dd hh:mm:ss)
- 整数型
……を指定できます。
以下、日時型のタイムスタンプがある場合の例です。
@timestamps true
@missing false
@univariate true
@dimension 2
@equallength true
@serieslength 5
@targetlabel false
@data
(2022-01-01 01:00:00,1),(2022-01-01 02:00:00,1),(2022-01-01 03:00:00,1)
(2022-02-01 01:00:00,1),(2022-02-01 02:00:00,1),(2022-02-01 03:00:00,1)
以下、整数型のタイムスタンプがある場合の例です。
@timestamps true
@missing false
@univariate true
@dimension 1
@equallength true
@serieslength 5
@targetlabel false
@data
(0,10),(1,20),(2,30)
(0,10),(1,20),(2,30)
タイムスタンプをつけない場合
メタデータブロックの項目@timesampをfalseとします。
観測値のみをコンマ,で区切って並べます。
以下、タイムスタンプのない場合の例です。
@timestamps false
@missing false
@univariate true
@dimension 1
@equallength true
@serieslength 5
@targetlabel false
@data
1,2,3,4,5
10,20,30,40,50
次元
タイムスタンプの例で示したデータセットの次元は1でしたが、次元(データセットの列)を増やしたい場合は、@dimension項目に次元数を記載します。
データはコロン:で区切ります。
ここは簡単のため、タイムスタンプのない3次元の例で示します。
@timestamps false
@missing false
@univariate true
@dimension 3
@equallength true
@serieslength 5
@targetlabel false
@data
1,2,3,4,5:1,2,3,4,5:1,2,3,4,5
1,2,3,4,5:1,2,3,4,5:1,2,3,4,5
欠損
データに欠損(欠測値)がある場合、メタデータブロックの@missingをtrueとします。
そして、?でデータ欠損を示します。
以下、例です。
@timestamps false
@missing true
@univariate true
@dimension 2
@equallength true
@serieslength 5
@targetlabel false
@data
1,?,3,?,5:1,2,3,4,5
10,20,30,40,?:1,2,3,?,5
タイムスタンプと?を組み合わせて使う場合には、次のようになります。
@timestamps true
@missing true
@univariate true
@dimension 1
@equallength true
@serieslength 5
@targetlabel false
@data
(2022-01-01,1),(2022-01-02,?),(2022-01-03,3)
(2023-01-01,1),(2023-01-02,2),(2023-01-03,3)
回帰問題
数値の目的変数が存在し、この目的変数の値を予測する問題を回帰問題と言います。
メタデータブロックの@targetlabelをtrueにして、最後の次元に目的変数の値(数値)を記載します。
以下、記載例です。
@timestamps false
@missing false
@univariate true
@dimension 1
@equallength true
@targetlabel true
@data
1,2,3,4,5:50
1.1,2.2,3.3,4.4,5.5:55
分類問題
クラスを示す目的変数が存在し、この目的変数のクラスを予測する問題を分類問題と言います。
メタデータブロックの@classlabelをtrueにして、最後の次元に目的変数の値(クラス)を記載します。
以下、クラスが文字列で表現されている場合の例です。
@timestamps false
@missing false
@univariate true
@dimension 2
@equallength true
@serieslength 5
@classlabel true a b
@data
1,2,3:a
10,20,30:b
5,6,7:a
以下、クラスが数字で表現されている場合の例です。
@timestamps false
@missing false
@univariate true
@dimension 2
@equallength true
@serieslength 5
@classlabel true 0.1 0.2
@data
1,2,3:0.1
10,20,30:0.2
5,6,7:0.1
まとめ
今回は、パネル時系列データ(Panel)を扱うtsフォーマットの読み込み方と、sktimeデータフォーマットの作り方を説明しました。
CSVフォーマットに次いで利用頻度の高いデータフォーマットです。
若干癖がありますが、慣れてしまえば問題はなく扱えるようになると思います。
次回は、時系列分類について説明します。
Python ライブラリー「sktime」で学ぶ らくらくビジネス時系列機械学習 Web講座 – 第8回:時系列分類 –