

sktimeはPythonでよく使われている機械学習ライブラリsklearn(scikit-learn)と同じインターフェースで提供されているPythonの時系列ライブラリです。
sktimeでは2023.5.1時点で時系列の4つの時系列機械学習の問題を解くことができます。
| 問題名 | データの種類 | 内容 |
| 1. 時系列予測 Forecasting |
目的変数のみの時系列データ | 過去の時系列データが与えられたときの将来の予測です。 |
| 2. 時系列クラスタリング Time Series Clustering |
特徴量(説明変数)のみの時系列データ | 複数の時系列データを、いくつかの類似のグループに分けます。 |
| 3. 時系列分類 Time Series Classification |
目的変数と特徴量(説明変数)のある時系列データ | 特徴量と目的変数が与えられた分類問題のうち、特徴量に時間的もしくはデータの順番に意味があるときに使います。sktimeでは二値分類および多値分類に対応しています。 |
| 4. 時系列回帰 Time Series Regression |
特徴量と目的変数が与えられたとき、目的変数が時系列かつ連続データであるときの目的変数の予測です。 |
このsktimeを使うためには、sktimeをPythonにインストールし呼び出さなければなりません。
今回は、時系列分類の方法を説明します。
- 時系列予測
- 時系列クラスタリング
- 時系列分類 ⇒ 今回
- 時系列回帰
Contents [hide]
時系列分類(時系列データの分類問題)とは?
時系列分類とは、複数の時系列データをいくつかのクラスへと分けることです。
いくつかのクラスへと分けることには、教師ありと教師なしによる方法あります。テーブルデータでも同様です。
- 教師ありの場合:分類問題
- 教師なしの場合:クラスタリング
時系列分類とは、要は「時系列データの分類問題」です。
例えば、1日のオフィスの時系列電力消費量を休日と平日にラベル付けして学習、新しい時系列電力消費量を平日か休日か当てる、のような形で使います。
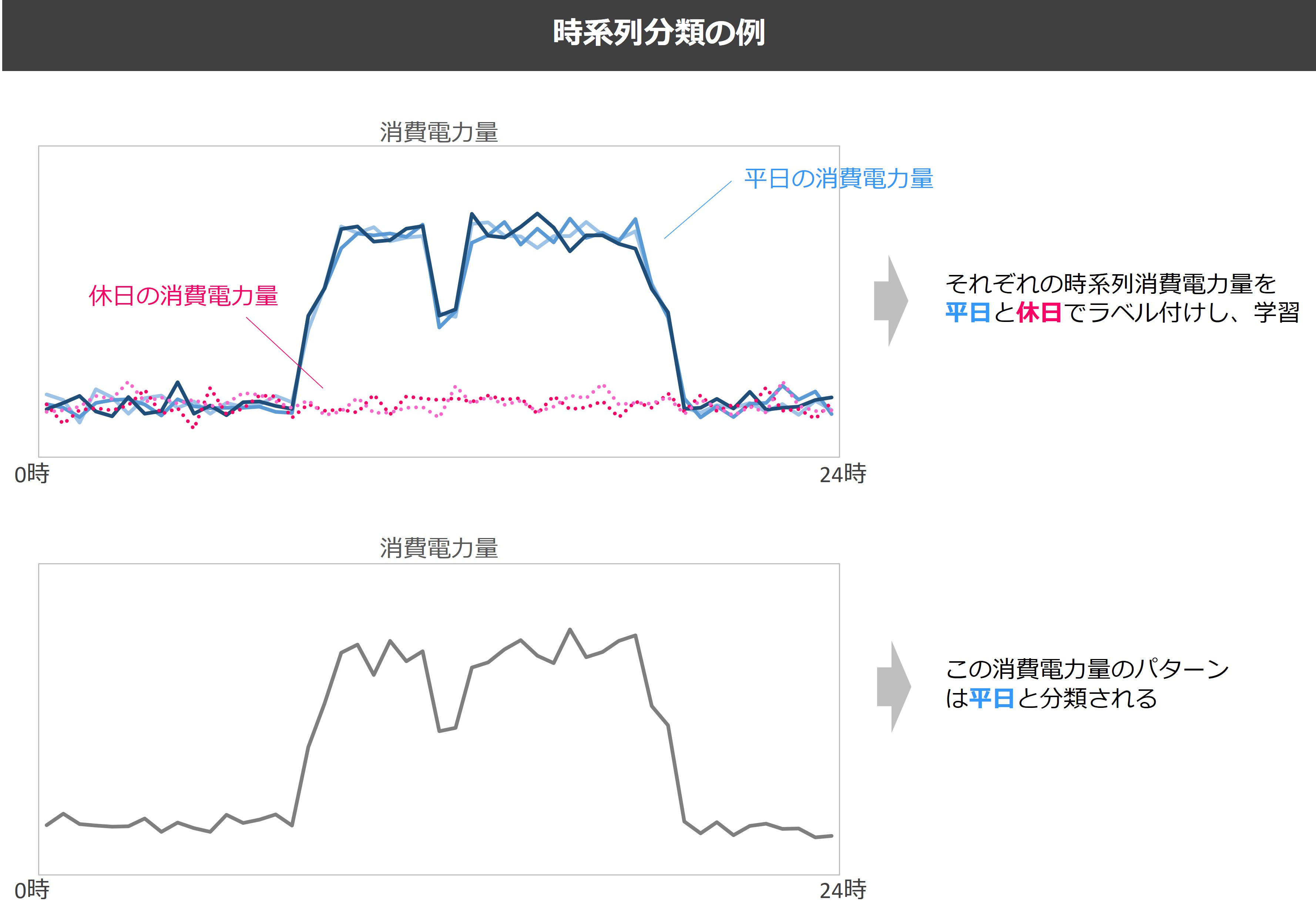
それでは実際にsktimeで時系列分類をしてみましょう。
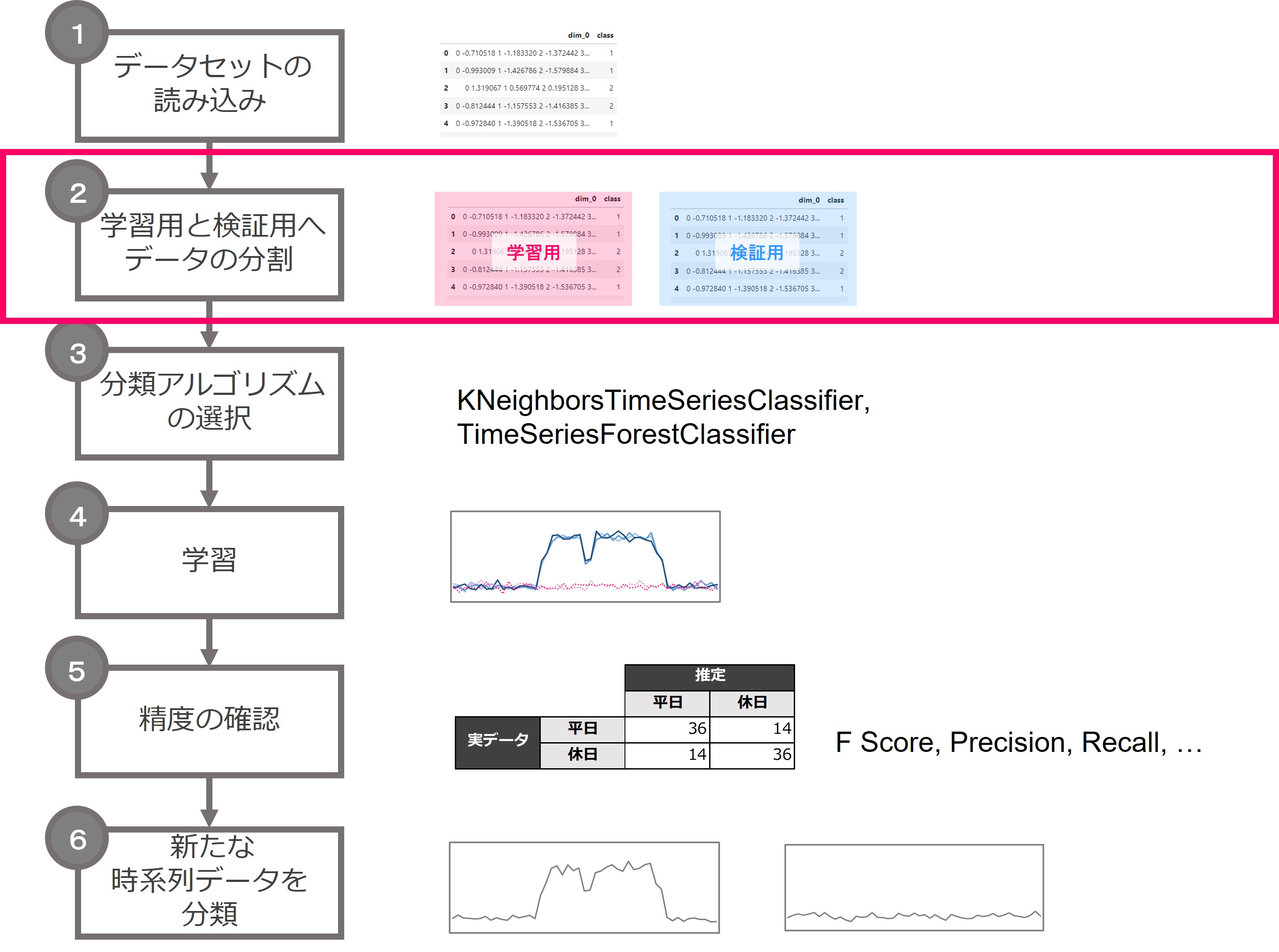
分類の流れと事前準備
時系列分類の流れです。
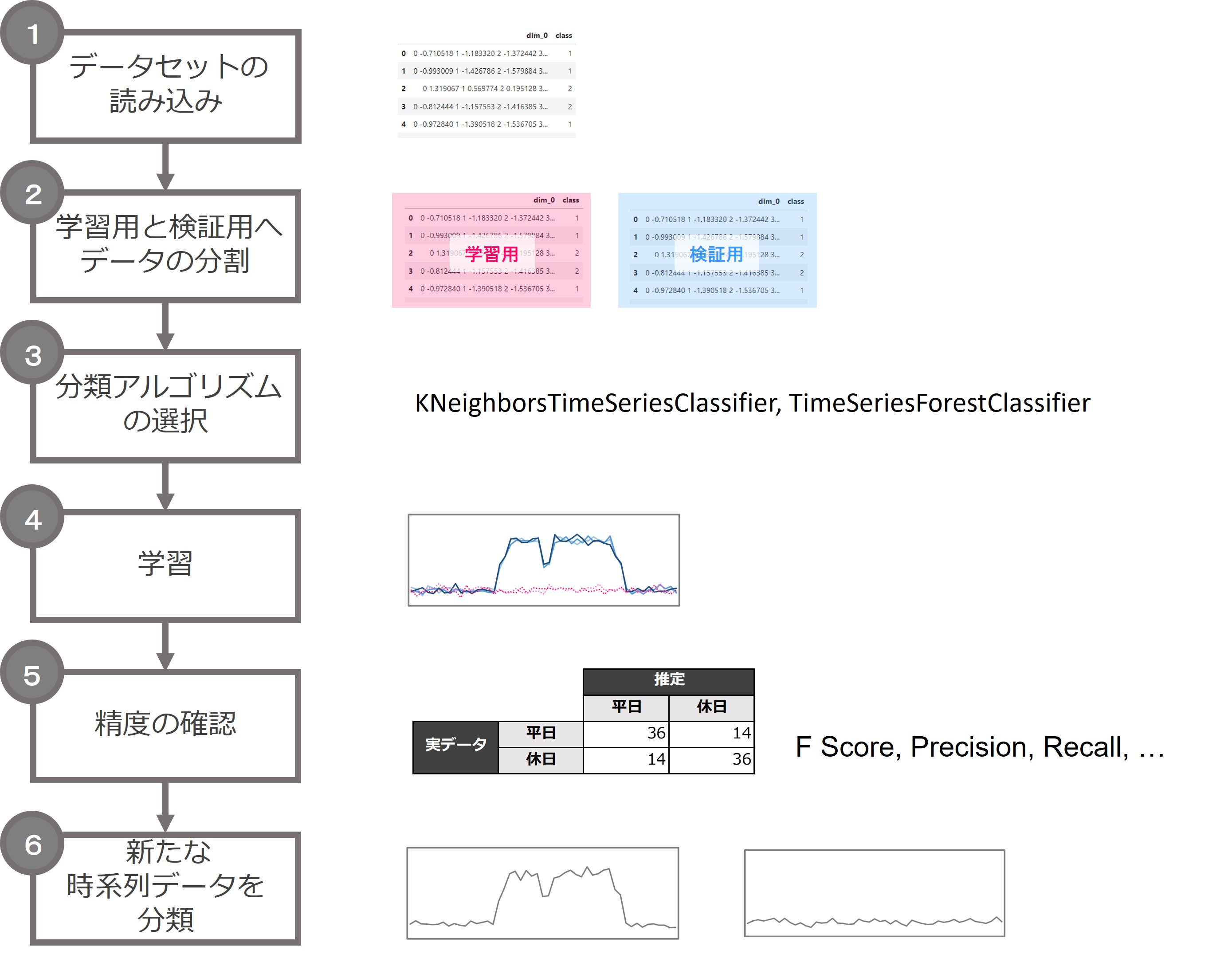
流れは、テーブルデータの分類問題と同じです。
異なるのは、時系列問題特有の分類アルゴリズムを利用するところです。
1.データセットの準備
利用するデータセットは、sktimeのload_italy_power_demandという関数で取得できる時系列データを使います。
これは、1年間の電力需要を10月~3月(冬期)と4月~9月(夏期)に分けてラベリングしたデータセットです。1と2の2つのクラスで区別されています。
それではデータを読み込みます。
以下、コードです。
from sktime.datasets import load_italy_power_demand X, y = load_italy_power_demand()
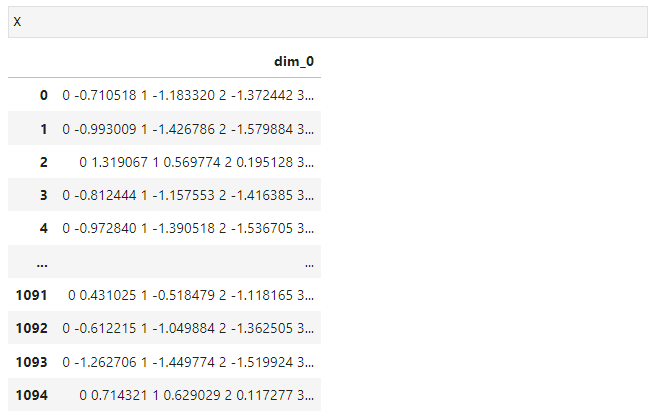
読み込んだデータの内容を見てみます。
以下、コードです。
X
以下、実行結果です。
このデータのデータタイプを調べてみます。
以下、コードです。
from sktime import datatypes datatypes.mtype(X)
以下、実行結果です。

nested_univタイプの時系列は、各行に時点と時系列が格納されています。
パネルデータと考えても良いです。1行(インデックス)が1パネルとなっています。
ある行(インデックス)の時系列データを取り出すには次のように指定します。例えば、index=5のデータを取り出すには次のようにします。
以下、コードです。
X.loc[5,:].values
以下、実行結果です。
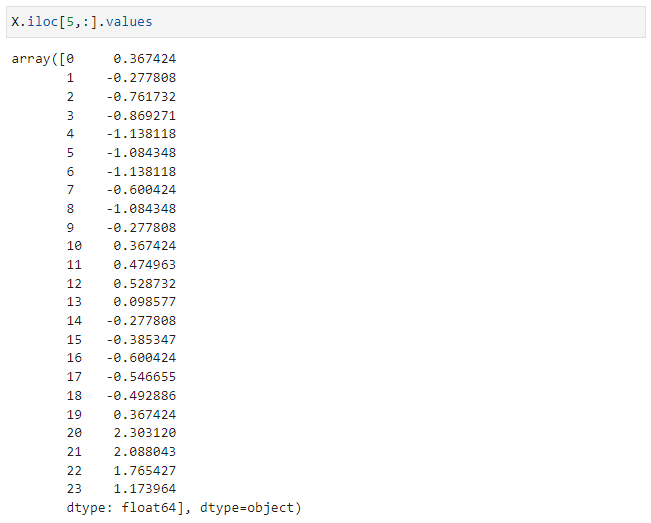
構造としてはこのようになっています。

次にyを見てみます。
以下、コードです。
y
以下、実行結果です。

yは分類結果(クラス)であり、Xの各行(インデックス)に紐づいた値が格納されています。今回は1と2です。
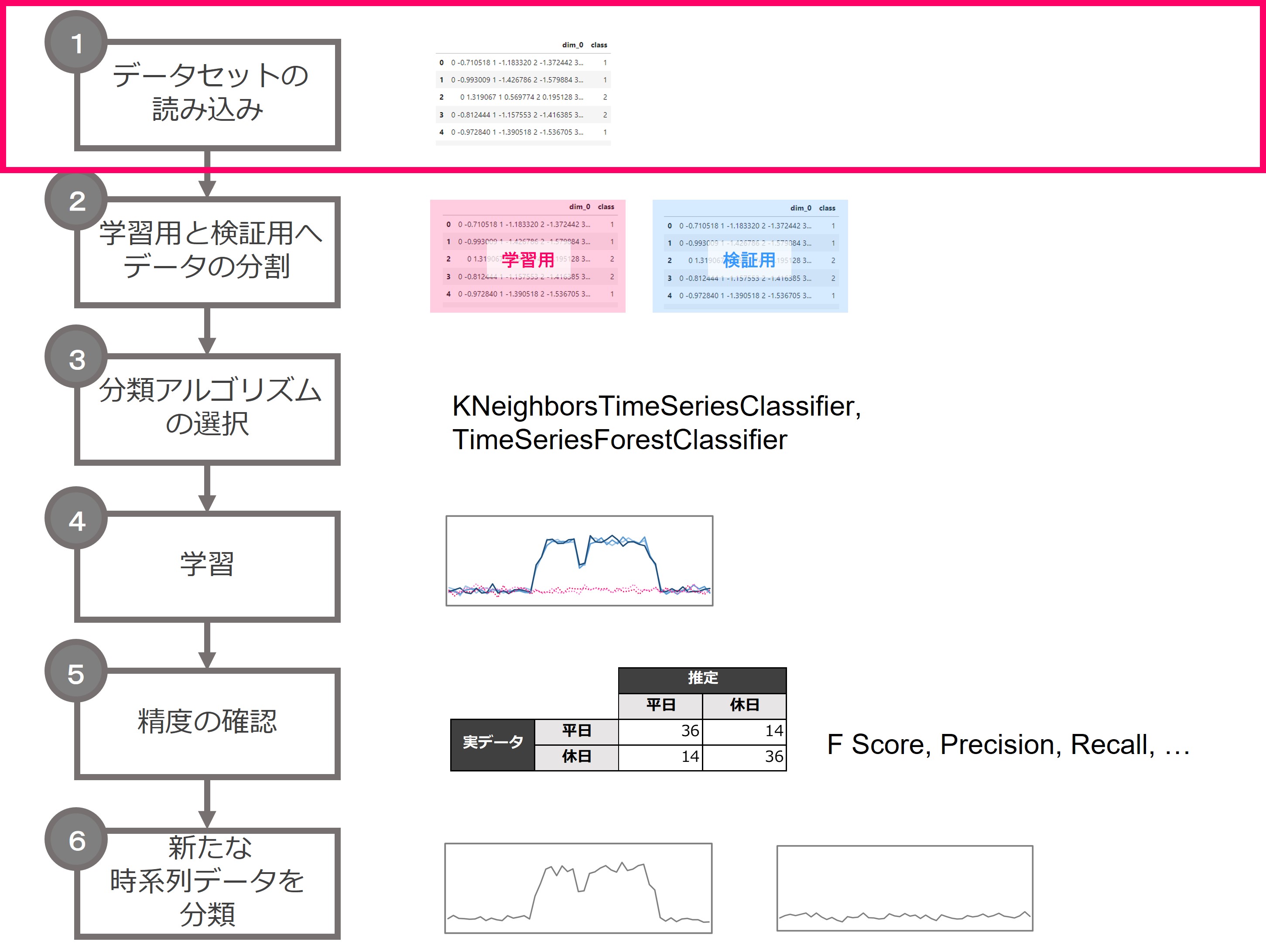
2.学習用と検証用へデータセットの分割
次に、取得したデータX,yを学習用と検証用へと分割します。
この分割は、パネル単位でランダムに分割するので、sktimeではなく、sklearnライブラリのtrain_test_split関数を使います。
以下、コードです。
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X,y,train_size=0.6)
- コードの1行目:データを行ごとにランダムに分割するsklearnのtrain_test_split関数を読み込んでいます
- コードの2行目:実際に分割しています。train_size=0.8として、学習用を60%、検証用を40%としてパネル単位で分割しています
中身を見てみます。
以下、コードです。
X_train
以下、実行結果です。
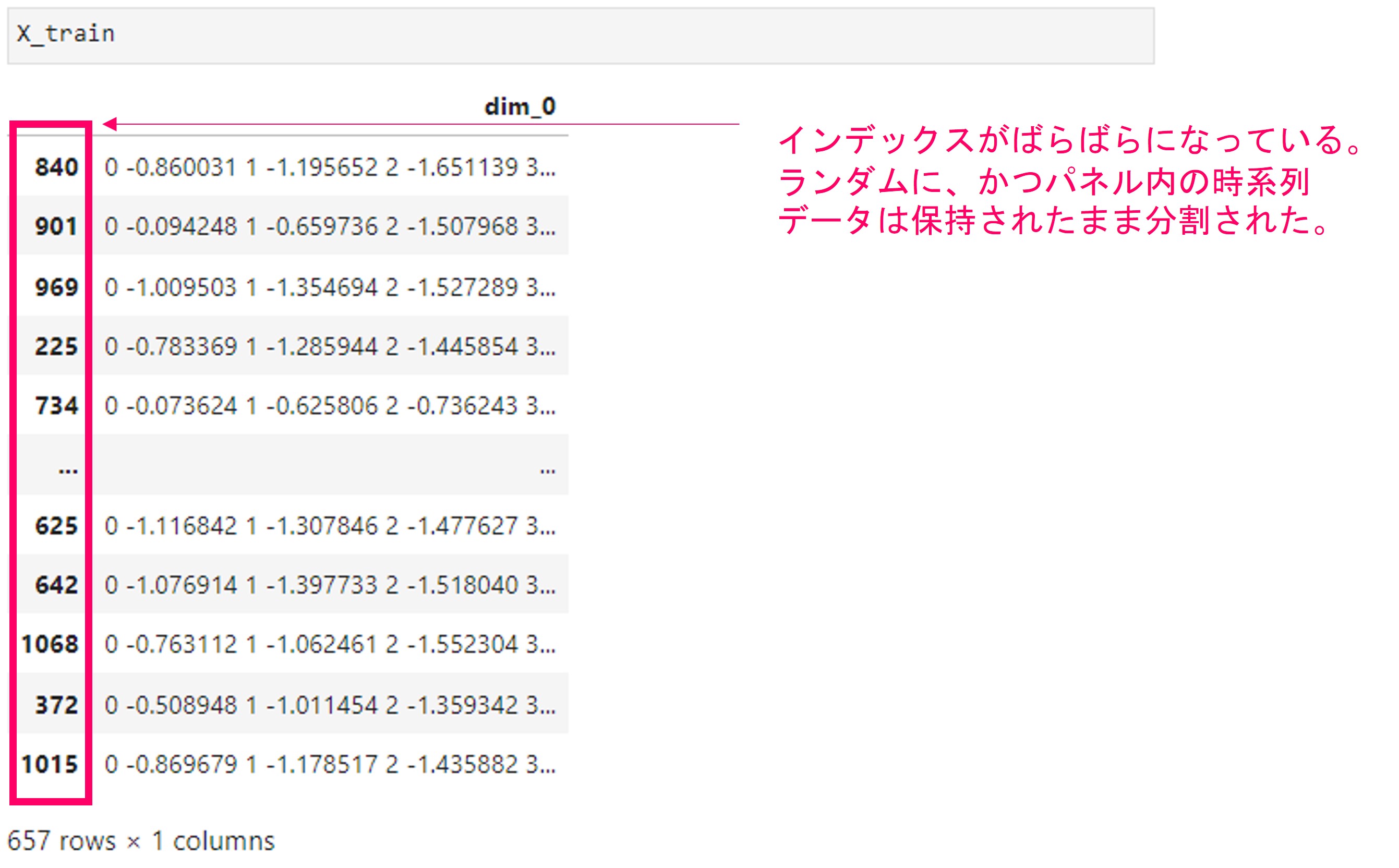
インデックスがばらばらになっているので、ランダムに学習用の時系列データが取得されたことがわかります。
これで、学習用データはX_train(時系列データ)とy_train(分類結果)に、検証用データはX_test(時系列データ)とy_test(分類結果)に分割されました。
3.分類アルゴリズムの選定
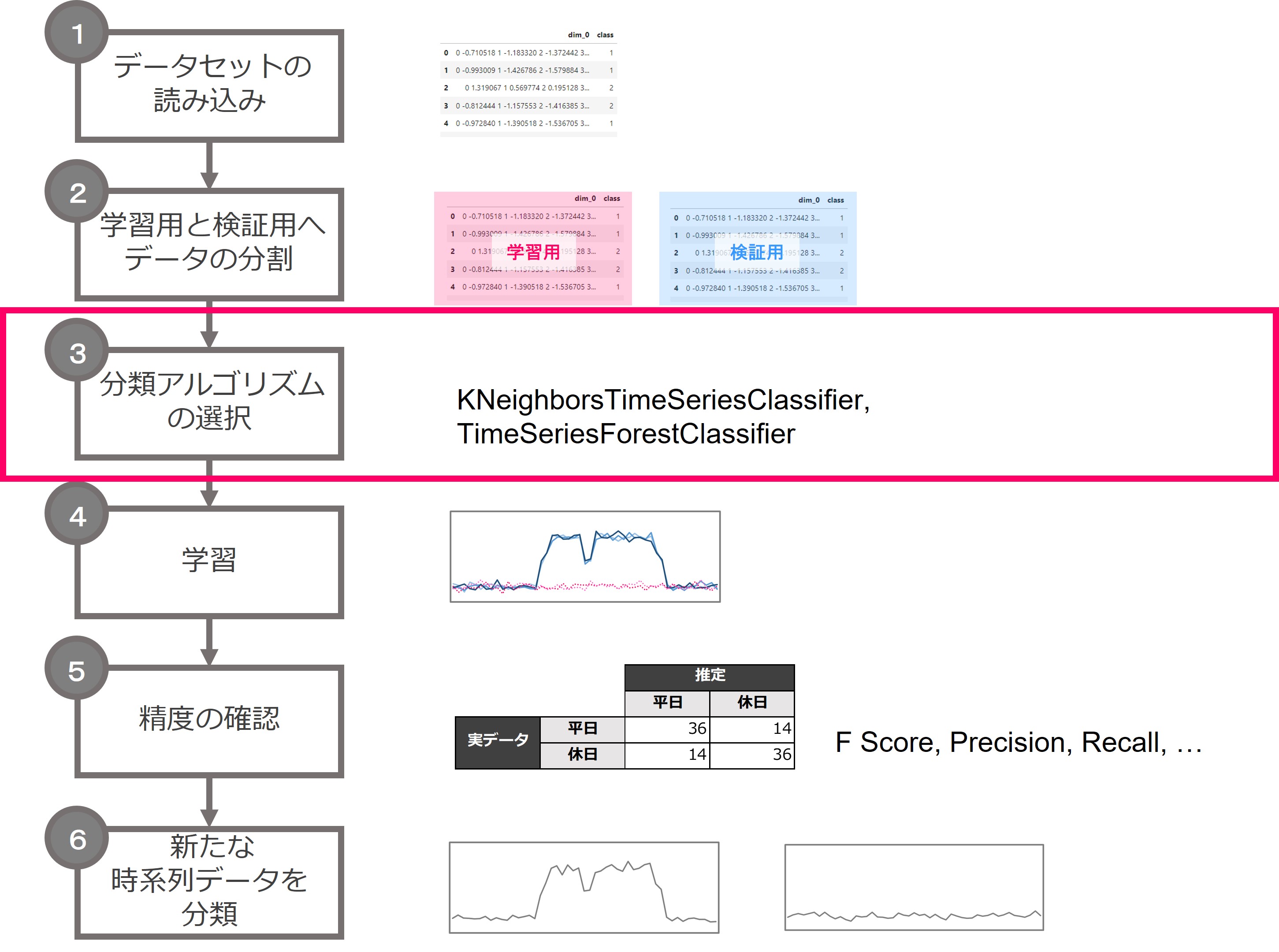
それでは、時系列分類のアルゴリズムを選定します。各アルゴリズムの特徴は別の回で説明します。
今回は、KNeighborsTimeSeriesClassifierを使います。
これは、時系列データ間の距離をユークリッド距離やDTWなどで測定し、距離が近いものを同じクラスとして分類する手法です。
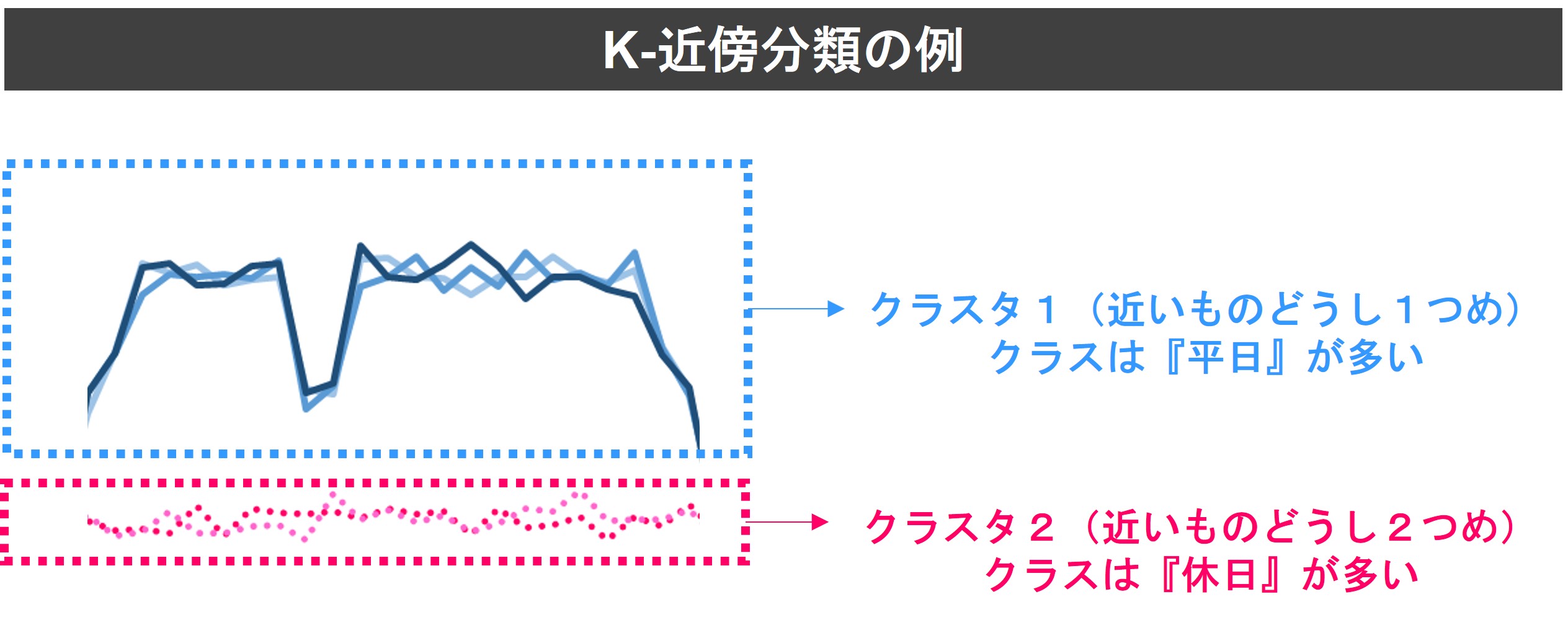
では実装です。アルゴリズムを読み込み、設定します。
以下、コードです。1行目でアルゴリズムのライブラリを読み込み、2行目で変数classifierにアルゴリズムを設定しています。3行目は設定されたアルゴリズムの確認です。
from sktime.classification.distance_based import KNeighborsTimeSeriesClassifier classifier = KNeighborsTimeSeriesClassifier(distance="euclidean") classifier
実行結果です。アルゴリズムとしてKNeiborsTimeSeriesClassifierが設定されました。

4.学習
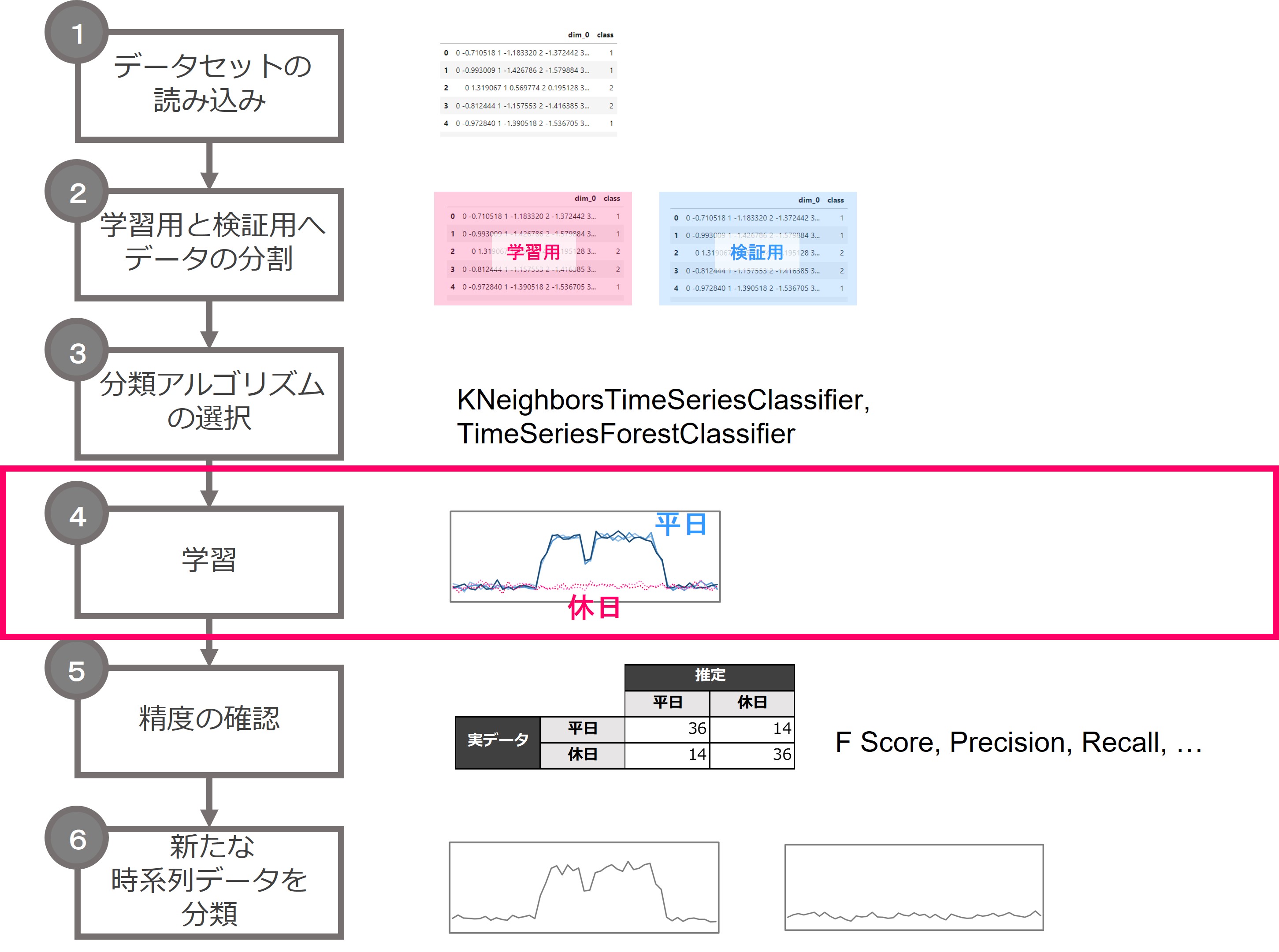
では学習します。
先ほどアルゴリズムを指定した、変数classifierのfit関数で、学習用データのX_trainとy_trainを与えて学習します。
以下、コードです。
classifier.fit(X_train, y_train)
5.精度の確認
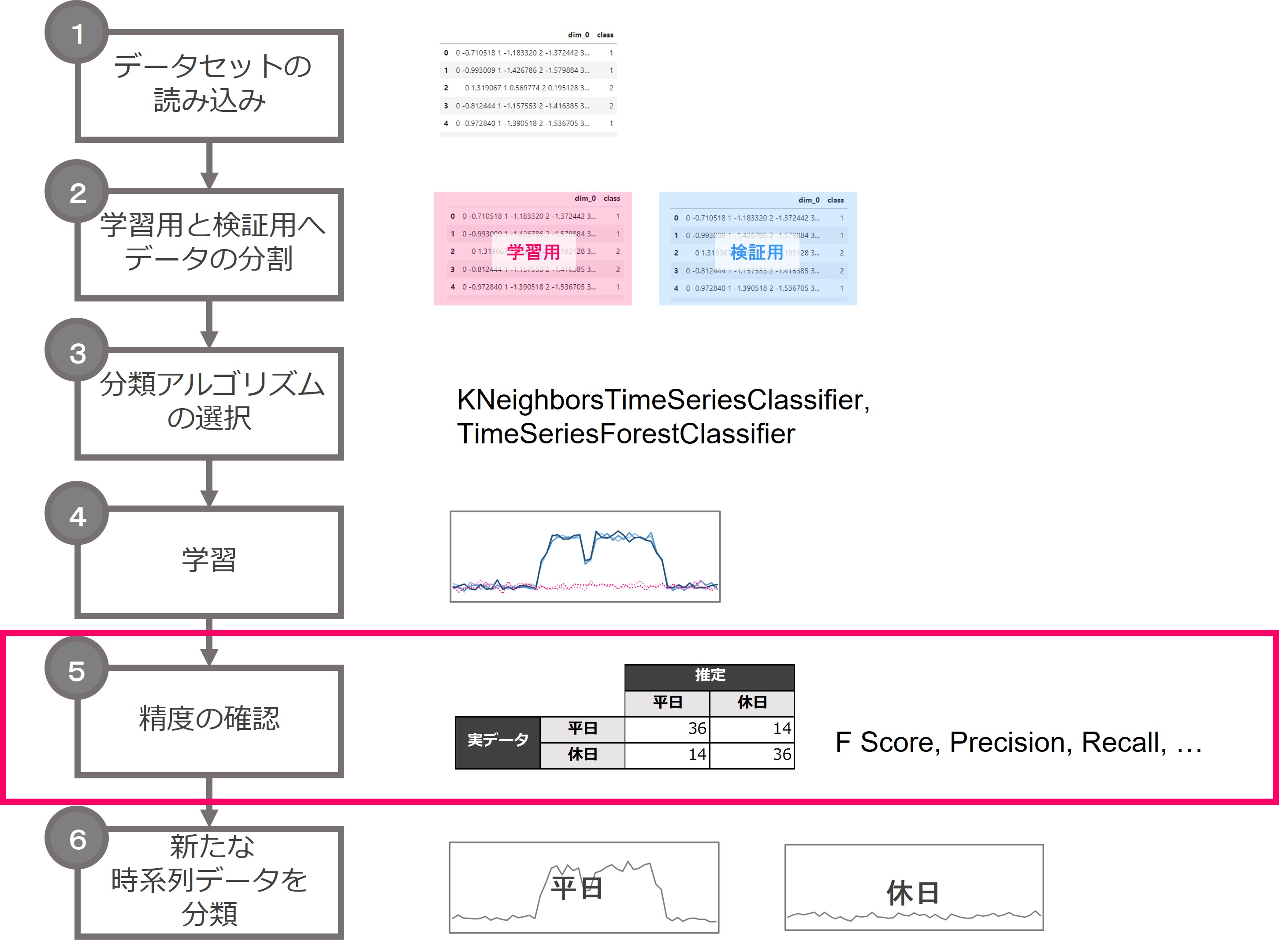
テーブルデータの分類問題と同様の精度指標で、精度確認ができます。
ここで、説明のため、検証用データをさらに分割し、検証用データと予測用データに分割しておきます。
元データの40%を半分ずつに分割するので……
- 検証用データは元データの20%(学習用データに対して33%)
- 予測用データも元データの20%
……となります。
以下、コードです。
X_test, y_test, X_pred, y_pred = train_test_split(X_test,y_test,train_size=0.5)
精度を検証するため、学習用データと検証用データを、学習済モデルで分類します。
以下、コードです。
y_train_pred = classifier.predict(X_train) y_test_pred = classifier.predict(X_test)
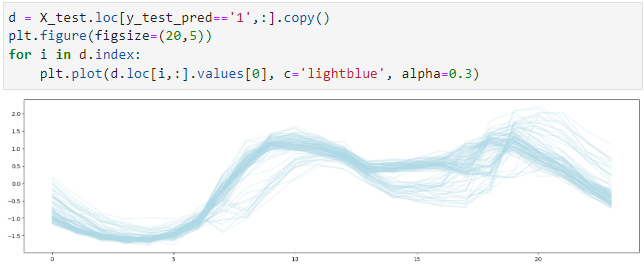
クラスごとに検証データの予測結果の時系列データをプロットしてみます。
まずはクラス’1’のプロットです。
以下、コードです。
d = X_test.loc[y_test_pred=='1',:].copy()
plt.figure(figsize=(20,5))
for i in d.index:
plt.plot(d.loc[i,:].values[0], c='lightblue', alpha=0.3)
以下、実行結果です。
次にクラス’2’です。
以下、コードです。
d = X_test.loc[y_test_pred=='2',:].copy()
plt.figure(figsize=(20,5))
for i in d.index:
plt.plot(d.loc[i,:].values[0],c='orange',alpha=0.2)
以下、実行結果です。
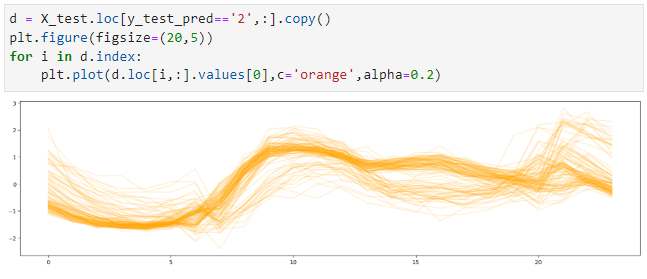
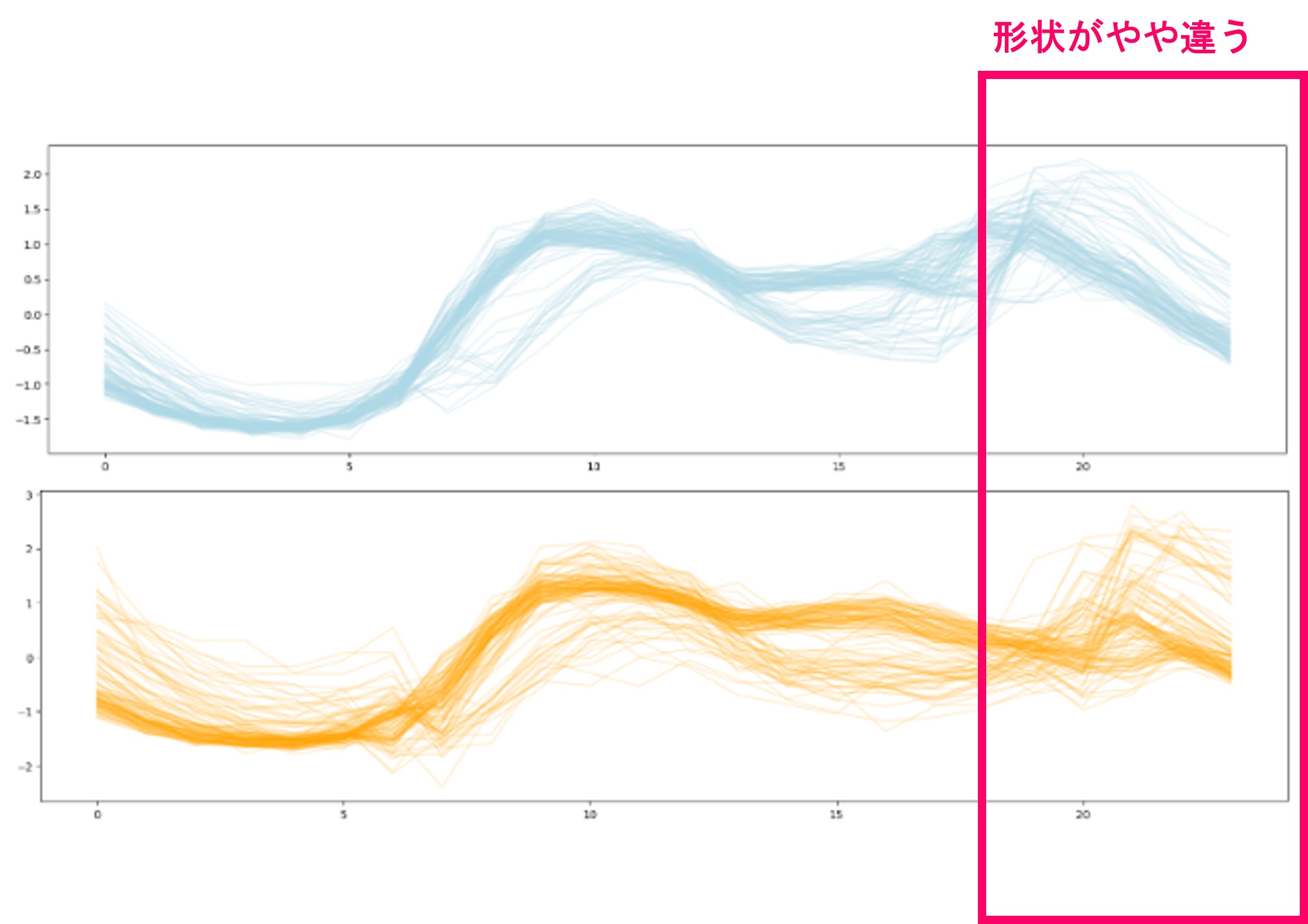
グラフを見ると、枠線で囲ったところがクラス間で形状がやや違うように見えます。つまり、分類できていそうです。
sklearnの混同行列で見てみましょう。1行目で混同行列のライブラリを読み込み、2行目で算出しています。
以下、コードです。
from sklearn.metrics import confusion_matrix confusion_matrix(y_test,y_test_pred)
以下、実行結果です。かなりうまく分類できていることがわかります。

分類問題の代表的な評価指標であるF1スコアも計算しておきます。
1行目でライブラリの読み込み、2行目で計算です。F1スコアの計算のためには、0,1の2値、もしくはTrue,Falseでクラスと分類結果を表しておく必要がありますので、2行目で、y_test==’1’やy_test_pred==’1’として真偽値へ変換しています。
以下、コードです。
from sklearn.metrics import f1_score f1_score(y_true=(y_test=='1'),y_pred=(y_test_pred=='1'))
以下、実行結果です。

0.98と、良いスコアが出ています。
他の評価指標はsklearn.metricsのページを参考にしてください。
6.新たな時系列データを分類
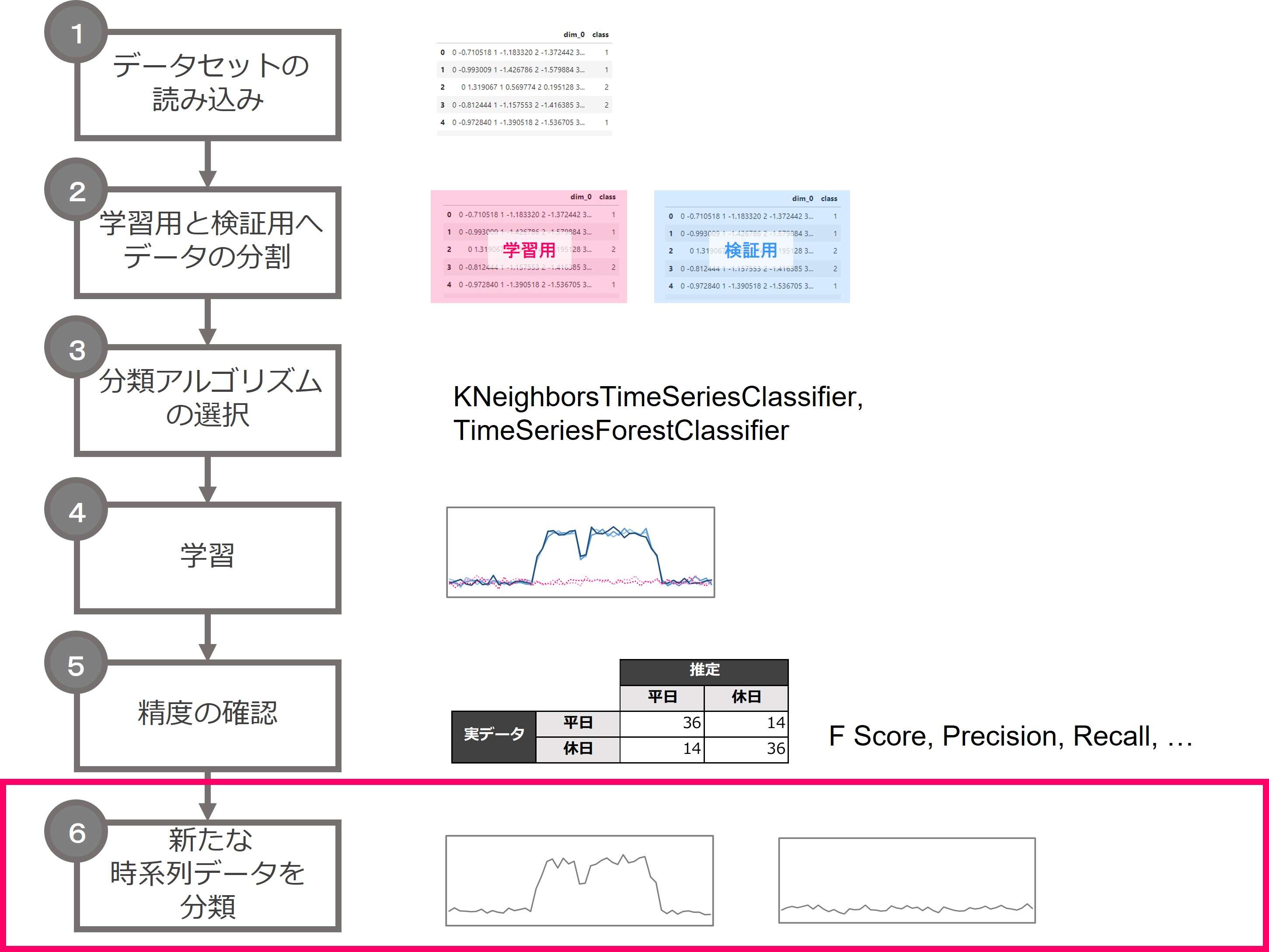
以上でモデルの学習が終わりましたので、新たな時系列データに対して分類を行います。
「5.精度の確認」で作成したデータ「X_pred」を使います。
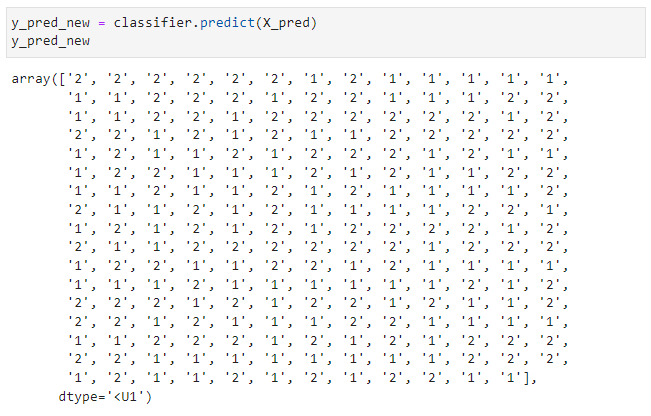
classifierのpredict関数で予測できます。結果は変数y_pred_newへ格納します。
以下、コードです。
y_pred_new = classifier.predict(X_pred)
以下、実行結果です。
まとめ
今回は、時系列分類の方法を説明します。
- 時系列予測
- 時系列クラスタリング
- 時系列分類 ⇒ 今回
- 時系列回帰
時系列分類とは、複数の時系列データをいくつかのクラスへと分ける、「時系列データの分類問題」です。