時系列データ分析は、特定の期間における変化を捉え、将来の動向を予測するための重要な手法です。 前回の記事では、mlforecastライブラリを使用して基本的な時系列予測モデルを構築する方法と、モデル性能を向上させるための...
時系列データの予測は、企業が将来の売上や需要を予測し、意思決定に活用するための重要なツールです。近年、機械学習技術の発展により、時系列予測はより高精度かつ柔軟なアプローチが求められています。 Pythonライブラリ「ml...
機械学習モデルの性能に不満を感じたことはありませんか? どんなに時間をかけてモデルを調整しても、予測精度が思うように上がらないことがあります。そんな時、アンサンブル学習という手法が効果的です。 アンサンブル学習とは、複数...
アンサンブル学習は、複数の機械学習モデルを組み合わせることで、単一のモデルよりも高い予測精度を達成する手法です。 アンサンブル学習は、現実世界の様々な問題に適用され、機械学習コンペティションでも常に上位を占める手法として...
データが未来を形作る今日、ビジネスリーダーたちは常により良い意思決定のための新しい手法を模索しています。 その答えの一つが、シャープレイバリューとツリー系モデルの組み合わせによるアプローチです。 シャープレイバリューは、...
近年、機械学習の技術はビジネスのあらゆる分野で急速に進化し、企業の意思決定プロセスに革命をもたらしています。 しかし、複雑化するモデルの背後にある「なぜ」という問いに答えることは、ますます困難になってきています。 今回は...
データサイエンスの進展に伴い、機械学習モデルの正確さを左右する重要な問題の一つがデータ不均衡です。 データ不均衡は、特定のクラスのサンプル数が他のクラスに比べて極端に少ない場合に発生し、予測モデルの性能に悪影響を及ぼしま...
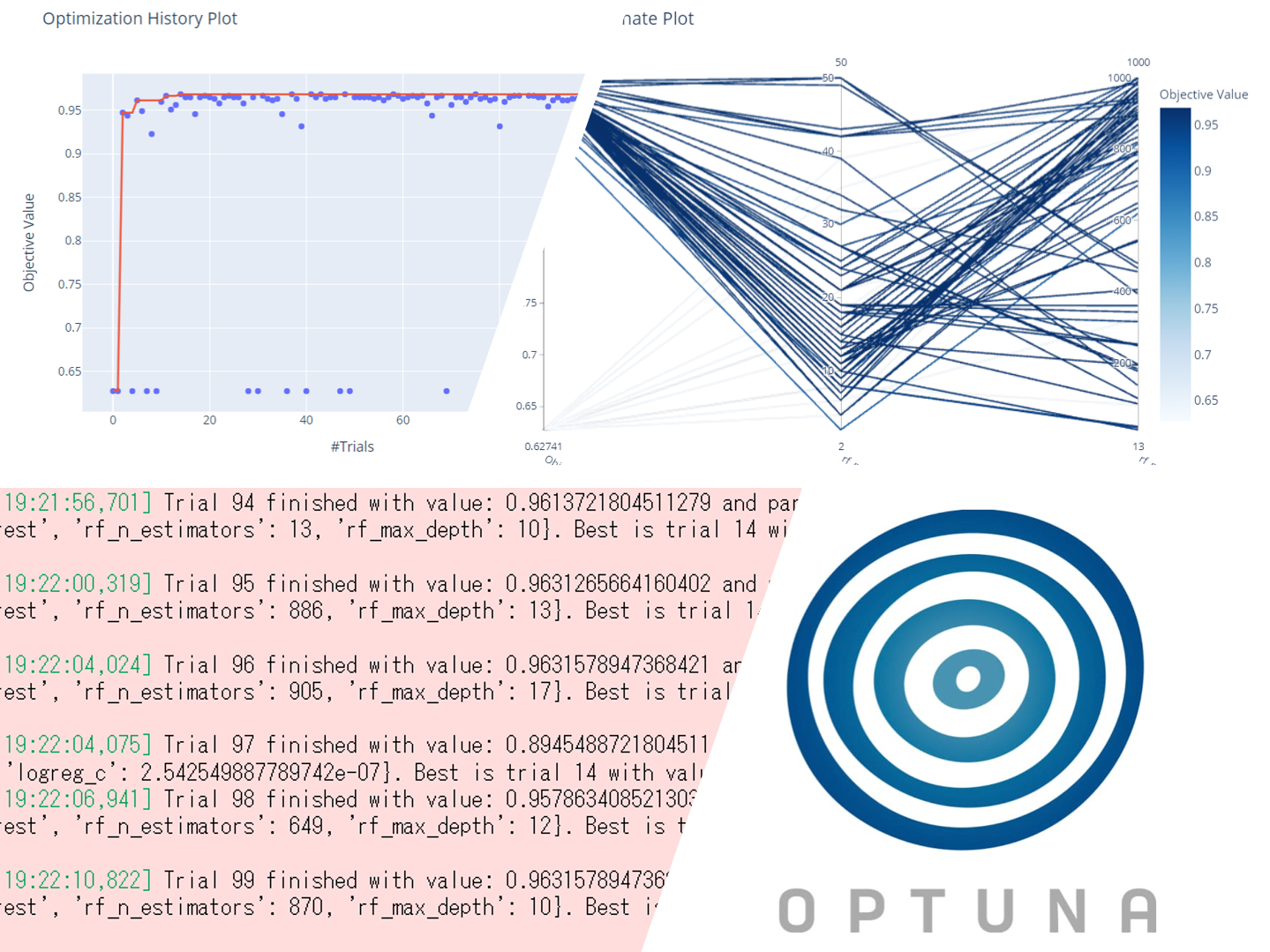
scikit-learnのモデルをOptunaでCV(クロスバリデーション)を実施する方法は2種類あります。 良し悪しを判断するメトリクスにscikit-learnのCVを指定する方法 OptunaのCV関数(Optun...
機械学習などの数理モデルには、通常幾つかのハイパーパラメータがあり、そのハイパーパラメータの設定次第で大きく精度が変わります。 このハイパーパラメータを調整し最適な設定を探すタスクを、ハイパーパラメータチューニングと言い...
機械学習などの数理モデルには、通常幾つかのハイパーパラメータがあり、そのハイパーパラメータの設定次第で大きく精度が変わります。 このハイパーパラメータを調整し最適な設定を探すタスクを、ハイパーパラメータチューニングと言い...